目录
第一题
题目来源
题目内容
解决方法
方法一:遍历一次数组
方法二:贪心算法
方法三:双指针
第二题
题目来源
题目内容
解决方法
方法一:动态规划
方法二:贪婪算法
方法三:正则表达式
第三题
题目来源
题目内容
解决方法
方法一:贪心算法
方法二:动态规划
方法三:广度优先搜索
方法四:逆向贪婪算法
第一题
题目来源
605. 种花问题 - 力扣(LeetCode)
题目内容

解决方法
方法一:遍历一次数组
该问题的思路与算法如下:
- 初始化一个计数器count为0,用于记录可以种植花的数量。
- 遍历花坛数组,检查每个位置是否可以种植花。
- 如果当前位置为0,且其相邻的两个位置也为0(或者是边界情况),则该位置可以种植花。将该位置设为1,计数器count加1。
- 遍历结束后,判断计数器count的值是否大于等于n。
- 如果是,则表示可以种入n朵花,返回true。
- 如果不是,则表示不能种入n朵花,返回false。
这个思路的关键在于遍历花坛数组,检查每个位置是否满足种植花的条件。需要注意边界情况的处理,即第一个位置和最后一个位置的相邻位置的判断条件略有不同。通过遍历一次数组,可以快速判断能否种入n朵花。时间复杂度为O(n),其中n为花坛数组的长度。
class Solution {
public static boolean canPlaceFlowers(int[] flowerbed, int n) {int count = 0;int length = flowerbed.length;int i = 0;while (i < length) {if (flowerbed[i] == 0 && (i == 0 || flowerbed[i - 1] == 0) && (i == length - 1 || flowerbed[i + 1] == 0)) {flowerbed[i] = 1;count++;}i++;if (count >= n) {return true;}}return false;}
}复杂度分析:
- 时间复杂度:遍历一次花坛数组,对于每个位置最多访问其相邻的两个位置,因此时间复杂度为O(n),其中n为花坛数组的长度。
- 空间复杂度:该算法只使用了常数个变量,因此空间复杂度为O(1)。
综上所述,该算法的时间复杂度为O(n),空间复杂度为O(1)。
LeetCode运行结果:

方法二:贪心算法
除了遍历数组的解法,还可以使用贪心算法来解决这个问题。具体思路是:从左到右遍历花坛数组,如果当前位置为0且其相邻的左右位置都是0,则在该位置种植花,并将计数器加1;如果当前位置为1,则直接跳到下一个位置。
使用贪心算法的好处在于避免了对整个数组的遍历,而是仅仅关注每个位置是否能够种植花。这样可以优化时间复杂度,使得算法的运行时间更快。
class Solution {
public static boolean canPlaceFlowers(int[] flowerbed, int n) {int count = 0;int i = 0;while (i < flowerbed.length) {if (flowerbed[i] == 0 && (i == 0 || flowerbed[i - 1] == 0) && (i == flowerbed.length - 1 || flowerbed[i + 1] == 0)) {flowerbed[i] = 1;count++;}i++;}return count >= n;}
}复杂度分析:
- 时间复杂度: 这个解法只需要遍历一次花坛数组,对于每个位置最多访问其相邻的两个位置。因此,时间复杂度为 O(n),其中 n 是花坛数组的长度。
- 空间复杂度: 该解法只使用了常数个变量,所以空间复杂度为 O(1)。
综上所述,使用贪心算法的解法的时间复杂度为 O(n),空间复杂度为 O(1)。与遍历数组的解法相比,在时间复杂度上并无区别,但是在代码实现上更简洁。
LeetCode运行结果:
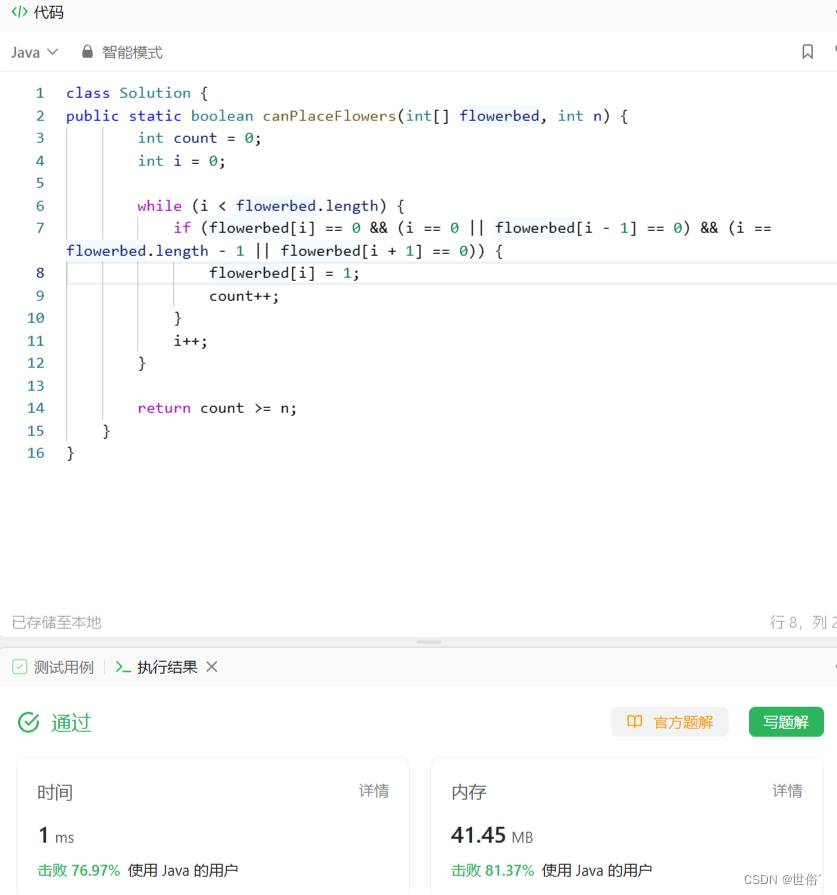
方法三:双指针
除了遍历数组、贪心算法,还可以使用双指针来解决这个问题。
具体思路是使用两个指针,一个指向当前位置,一个指向前一个位置。从左到右遍历花坛数组,如果当前位置为0且前一个位置和后一个位置都是0,则在该位置种植花,并将计数器加1。然后将两个指针向后移动两位,继续遍历下一个位置。
class Solution {
public static boolean canPlaceFlowers(int[] flowerbed, int n) {int count = 0;int i = 0;while (i < flowerbed.length) {if (flowerbed[i] == 0 && (i == 0 || flowerbed[i - 1] == 0) && (i == flowerbed.length - 1 || flowerbed[i + 1] == 0)) {flowerbed[i] = 1;count++;i += 2;} else {i++;}}return count >= n;}
}复杂度分析:
- 时间复杂度:O(n),其中n为花坛数组的长度。
- 空间复杂度:O(1),只需要常数级别的额外空间存储临时变量。
与贪心算法相比,在思路上稍微有所不同,但在时间复杂度和空间复杂度上相同。
LeetCode运行结果:

第二题
题目来源
44. 通配符匹配 - 力扣(LeetCode)
题目内容

解决方法
方法一:动态规划
这个问题可以使用动态规划的思路来解决。
我们可以定义一个二维布尔数组dp,其中dp[i][j]表示字符串s的前i个字符和模式串p的前j个字符是否匹配。
接下来我们分析状态转移的情况:
- 当s的第i个字符和p的第j个字符相等或者p的第j个字符为'?'时,dp[i][j]的值取决于dp[i-1][j-1],即s的前i-1个字符和p的前j-1个字符是否匹配。
- 当p的第j个字符为'*'时,dp[i][j]的值可以从dp[i][j-1]或dp[i-1][j]转移而来:
- dp[i][j-1]表示'*'匹配了空字符,此时dp[i][j]的值取决于dp[i][j-1];
- dp[i-1][j]表示'*'匹配了s的第i个字符,此时dp[i][j]的值取决于dp[i-1][j]。
根据以上分析,我们可以得到动态规划的状态转移方程:
if (s.charAt(i - 1) == p.charAt(j - 1) || p.charAt(j - 1) == '?') {dp[i][j] = dp[i - 1][j - 1];
} else if (p.charAt(j - 1) == '*') {dp[i][j] = dp[i][j - 1] || dp[i - 1][j];
}
边界情况:
- dp[0][0]表示空字符和空字符完全匹配,初始化为true;
- dp[0][j]表示空字符和模式串p的前j个字符匹配的情况。若p的第j个字符为'*',则dp[0][j]的值取决于dp[0][j-1];否则为false;
- dp[i][0]表示字符串s的前i个字符和空字符匹配的情况,都为false。
最终,我们返回dp[m][n],即字符串s的全部字符和模式串p的全部字符是否完全匹配。
class Solution {public boolean isMatch(String s, String p) {int m = s.length(), n = p.length();boolean[][] dp = new boolean[m + 1][n + 1];dp[0][0] = true;// 处理 p 以 * 开头的情况for (int j = 1; j <= n; j++) {if (p.charAt(j - 1) == '*') {dp[0][j] = true;} else {break;}}for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (s.charAt(i - 1) == p.charAt(j - 1) || p.charAt(j - 1) == '?') {dp[i][j] = dp[i - 1][j - 1];} else if (p.charAt(j - 1) == '*') {dp[i][j] = dp[i][j - 1] || dp[i - 1][j];}}}return dp[m][n];}
}
复杂度分析:
对于给定长度为m的字符串s和长度为n的模式串p,动态规划解法的时间复杂度为O(mn),空间复杂度也为O(mn)。
在计算过程中,我们需要填充一个大小为(m+1)×(n+1)的二维dp数组。每个位置的填充操作需要常数时间,因此总的时间复杂度为O(m*n)。
同时,我们只使用一个二维dp数组来存储中间结果,所以空间复杂度也是O(m*n)。
需要注意的是,这里的m和n并不是指s和p的最大长度,而是分别表示s和p实际的长度加1。这是因为我们在填充dp数组时,需要考虑到空字符和空模式串的情况。
总结起来,该解法具有较优的时间和空间复杂度,适用于处理规模较小的字符串匹配问题。
LeetCode运行结果:
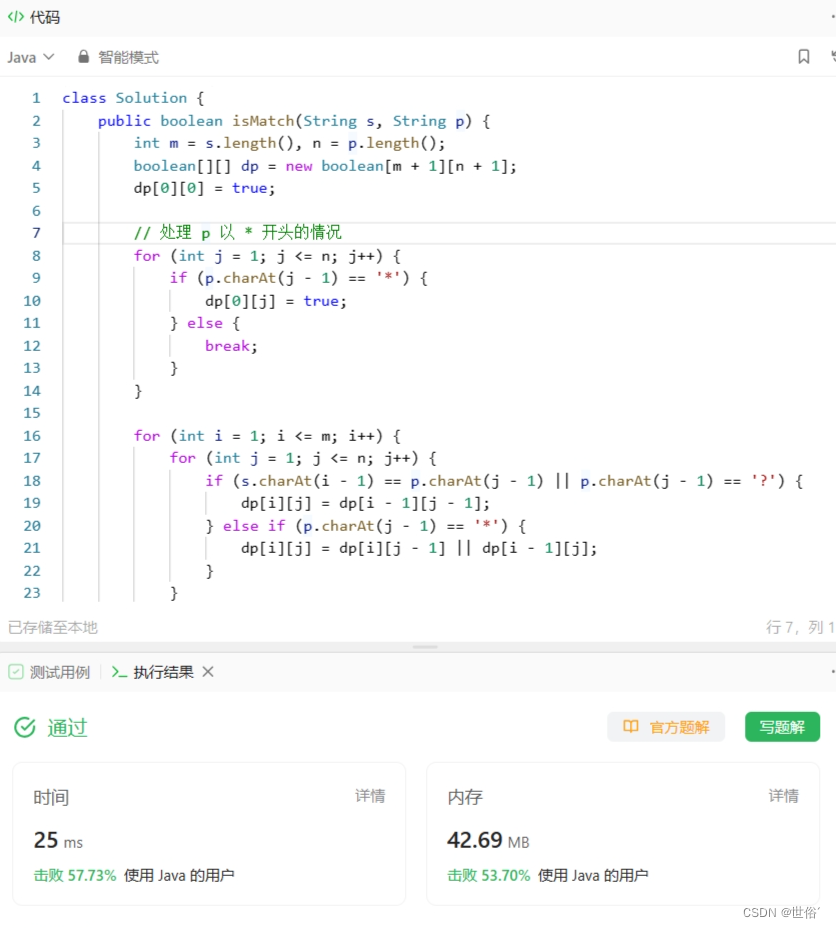
方法二:贪婪算法
除了动态规划,还可以使用贪婪算法进行字符串匹配。贪婪算法通常是一种基于局部最优选择的策略,在某些情况下可以得到快速且有效的解。具体到字符串匹配问题,我们可以通过迭代遍历的方式来实现贪婪算法。
该贪婪算法的思路是一次处理字符串s和模式串p的一个字符,根据当前的字符匹配情况进行不同操作:
- 若两个字符相等或者模式串p的当前字符为'?',则两个索引都向后移动;
- 若模式串p的当前字符为'*',记录当前位置,并只移动模式串的索引;
- 若当前字符不匹配,但之前出现过''的情况,回溯到''匹配的下一个位置,并将字符串索引+1;
- 若没有之前出现过'*'的情况,则匹配失败。
- 最后需要处理模式串p末尾的多余字符,判断是否全部为'*'。
该贪婪算法在某些情况下可以得到快速的解,但并不适用于所有的字符串匹配问题。在一些特殊的模式串情况下,可能会导致错误的匹配结果。因此,在实际应用中,需要根据具体情况选择合适的解法。
class Solution {public boolean isMatch(String s, String p) {int sIndex = 0; // 字符串s的索引int pIndex = 0; // 模式串p的索引int matchIndex = -1; // 最近一次出现'*'匹配的位置int starIndex = -1; // 最近一次出现'*'的位置while (sIndex < s.length()) {// 当两个字符相等或模式串为'?'时,两个索引都向后移动if (pIndex < p.length() && (s.charAt(sIndex) == p.charAt(pIndex) || p.charAt(pIndex) == '?')) {sIndex++;pIndex++;}// 当模式串为'*'时,记录当前位置,并只移动模式串的索引else if (pIndex < p.length() && p.charAt(pIndex) == '*') {starIndex = pIndex;matchIndex = sIndex;pIndex++;}// 当前字符不匹配,但有之前出现过'*'的情况,回溯到'*'匹配的下一个位置,并将字符串索引+1else if (starIndex != -1) {pIndex = starIndex + 1;matchIndex++;sIndex = matchIndex;}// 当没有之前出现过'*'的情况,返回falseelse {return false;}}// 处理模式串末尾的多余字符while (pIndex < p.length() && p.charAt(pIndex) == '*') {pIndex++;}// 字符串s和模式串p都遍历完毕,则匹配成功return pIndex == p.length();}
}
复杂度分析:
设字符串 s 的长度为 n,模式串 p 的长度为 m。
- 在最坏情况下(即没有匹配的字符和通配符时),两个索引 sIndex 和 pIndex 都要遍历整个字符串 s 和模式串 p。 时间复杂度为 O(n+m)。
- 在处理通配符 '*' 时,如果出现回溯的情况,需要在每次回溯时移动 pIndex 和 matchIndex,直到找到匹配的字符位置。 由于每次回溯都会移动 sIndex,所以总共只会有 n 次回溯操作。 因此,在最坏情况下,回溯操作的时间复杂度为 O(n)。
- 在处理模式串末尾的多余字符时,需要遍历剩余的模式串字符。 时间复杂度为 O(m-pIndex)。
综上所述,代码的总体时间复杂度为 O(n+m),空间复杂度为 O(1)。
LeetCode运行结果:
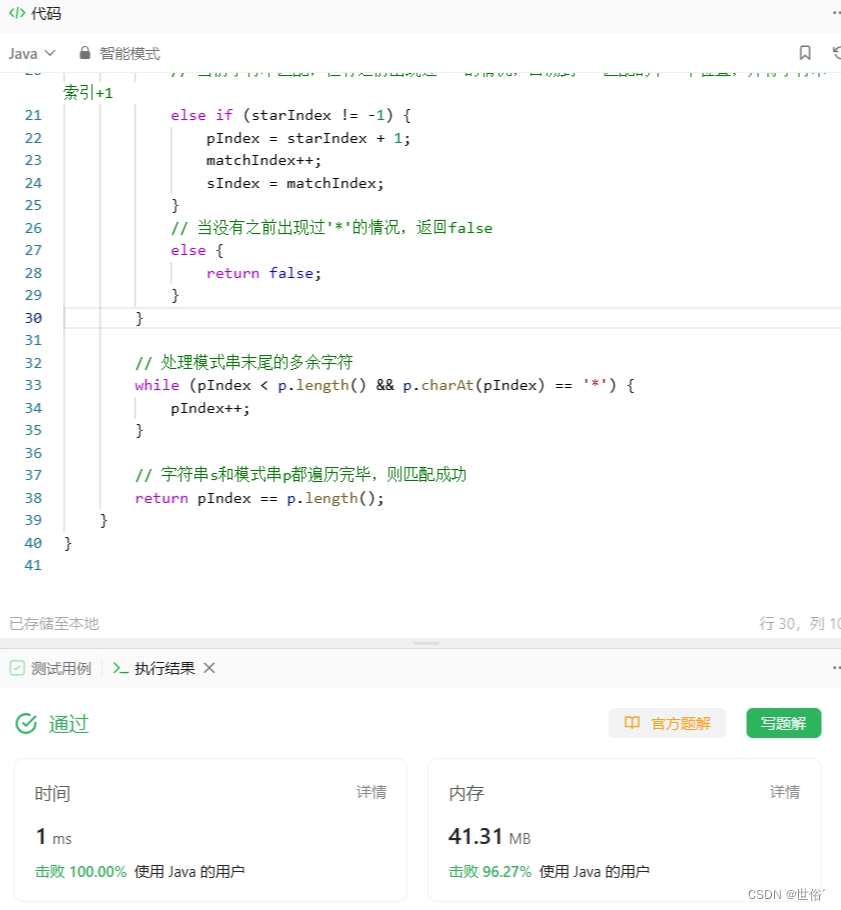
方法三:正则表达式
class Solution {public boolean isMatch(String s, String p) {String regex = p.replace("?", ".").replace("*", ".*");return s.matches(regex);}
}
这个实现使用了 Java 的正则表达式来处理通配符匹配。首先,将模式串 p 中的 '?' 替换成 '.',将 '' 替换成 '.',得到一个新的正则表达式 regex。
然后,使用字符串 s 的 matches() 方法,测试字符串 s 是否能够匹配正则表达式 regex。如果能够匹配,则返回 true,否则返回 false。
需要注意的是,该方法只是一种简单的通配符匹配算法,可能无法处理一些复杂的情况。在实际应用中,需要根据需求选择更加高效和精确的算法。
复杂度分析:
- 时间复杂度分析:使用正则表达式的 matches() 方法进行匹配,具体的实现和性能取决于底层正则引擎。一般情况下,时间复杂度为 O(M*N),其中 M 是模式串 p 的长度,N 是字符串 s 的长度。
- 空间复杂度分析:空间复杂度取决于正则表达式的匹配过程中是否需要生成匹配结果的存储。在 Java 的 matches() 方法中,会将整个匹配结果存储在内存中,并返回一个 boolean 值表示是否匹配成功。因此,空间复杂度为 O(M*N),其中 M 是模式串 p 的长度,N 是字符串 s 的长度。
LeetCode运行结果:

第三题
题目来源
45. 跳跃游戏 II - 力扣(LeetCode)
题目内容

解决方法
方法一:贪心算法
class Solution {public int jump(int[] nums) {if (nums.length <= 1) {return 0;}int maxReach = nums[0]; // 当前能够到达的最远位置int steps = nums[0]; // 当前步数内能够到达的最远位置int jumps = 1; // 跳跃次数for (int i = 1; i < nums.length; i++) {// 如果当前位置超过了最远位置,需要进行一次跳跃if (i > maxReach) {jumps++;maxReach = steps;}// 更新当前步数内能够到达的最远位置steps = Math.max(steps, i + nums[i]);}return jumps;}
}
在这个实现中,我们使用贪心算法来寻找最优解。我们定义三个变量:
- maxReach:当前能够到达的最远位置
- steps:当前步数内能够到达的最远位置
- jumps:跳跃次数
我们从索引 1 开始遍历数组,每次更新 steps 的值为当前位置加上当前元素的值。如果当前位置超过了 maxReach,说明我们需要进行一次跳跃,此时将 jumps 加 1,并更新 maxReach 为 steps。
最终,返回 jumps 的值即为到达最后一个位置的最小跳跃次数。
复杂度分析:
- 时间复杂度是 O(n),其中 n 是数组
nums的长度。这是因为我们只需要遍历一次数组,每次遍历都更新跳跃的最远位置和步数内能够到达的最远位置。 - 空间复杂度是 O(1),即常数级别的额外空间。这是因为我们只使用了几个变量来保存最远位置、步数和跳跃次数,没有使用额外的数组或数据结构。
因此,该算法是一个高效的解决方案,可以在给定的约束条件下快速求解跳跃游戏问题。
LeetCode运行结果:

方法二:动态规划
除了贪心算法,还可以使用动态规划来解决跳跃游戏 II 问题。
class Solution {public int jump(int[] nums) {int n = nums.length;int[] dp = new int[n]; // dp[i] 表示到达第 i 个位置所需的最小跳跃次数Arrays.fill(dp, Integer.MAX_VALUE);dp[0] = 0;for (int i = 0; i < n; i++) {int maxJump = nums[i]; // 当前位置能够跳跃的最大长度for (int j = 1; j <= maxJump && i + j < n; j++) {dp[i + j] = Math.min(dp[i + j], dp[i] + 1);}}return dp[n - 1];}
}
在这个实现中,我们首先创建一个长度为 n 的数组 dp,用于保存到达每个位置所需的最小跳跃次数。初始化 dp[0] 为 0,其它位置的值都设置为一个较大的数,表示初始状态为无穷大。
然后,我们从左向右遍历数组 nums,对于每个位置 i,将当前位置能够跳跃的最大长度 nums[i] 内的所有位置的 dp 值更新为 dp[i] + 1,表示通过当前位置 i 进行一次跳跃。
最终,返回 dp[n - 1] 的值即为到达最后一个位置的最小跳跃次数。
该算法的时间复杂度是 O(n^2),其中 n 是数组 nums 的长度。因为我们需要遍历每个位置,并且对于每个位置,还需要遍历当前位置能够跳跃的最大长度内的所有位置。
复杂度分析:
- 时间复杂度是 O(n^2),其中 n 是数组 nums 的长度。这是因为我们需要遍历每个位置,并对于每个位置,还需要遍历当前位置能够跳跃的最大长度内的所有位置。
- 空间复杂度是 O(n),即额外使用了一个数组 dp 来保存最小跳跃次数。这是因为我们需要存储到达每个位置所需的最小跳跃次数。
虽然动态规划解法的时间复杂度较高,但它提供了一种通用的解决方法,适用于各种求解最优解问题的场景。在实际应用中,可以根据输入规模和实际需求来选择贪心算法或动态规划来解决跳跃游戏问题。如果输入规模较小,动态规划算法的性能可能会比较好;如果输入规模较大,贪心算法可能会更加高效。
LeetCode运行结果:

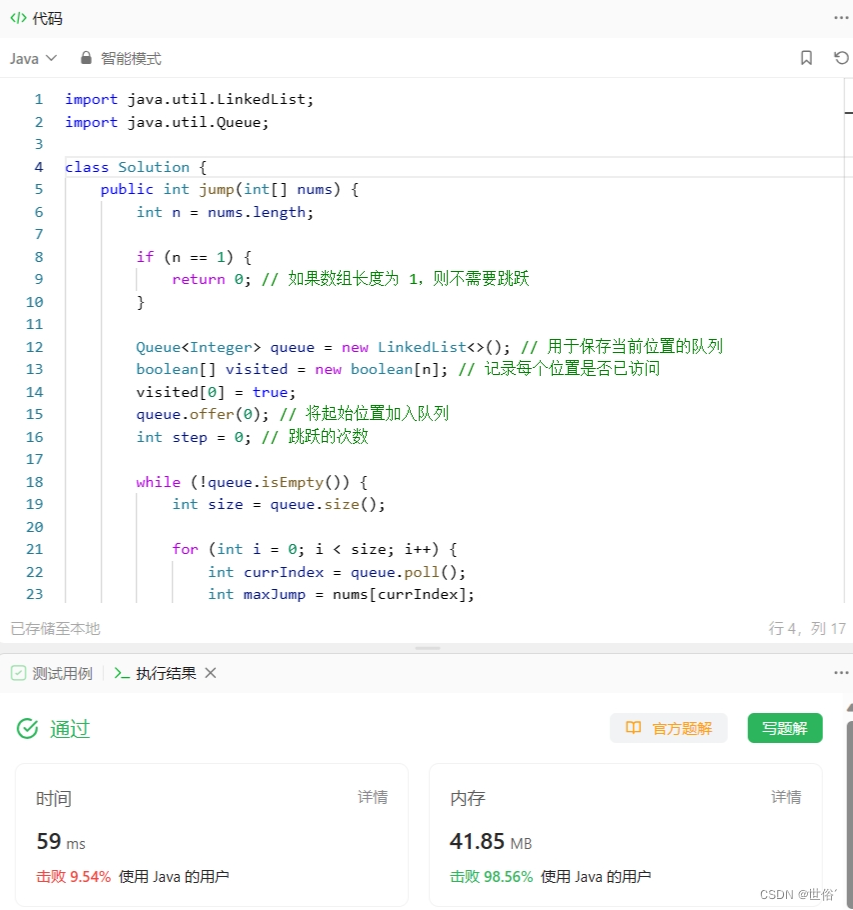
方法三:广度优先搜索
除了贪婪算法和动态规划之外,还有一种常见的解决方法是使用广度优先搜索(BFS)。
import java.util.LinkedList;
import java.util.Queue;class Solution {public int jump(int[] nums) {int n = nums.length;if (n == 1) {return 0; // 如果数组长度为 1,则不需要跳跃}Queue<Integer> queue = new LinkedList<>(); // 用于保存当前位置的队列boolean[] visited = new boolean[n]; // 记录每个位置是否已访问visited[0] = true;queue.offer(0); // 将起始位置加入队列int step = 0; // 跳跃的次数while (!queue.isEmpty()) {int size = queue.size();for (int i = 0; i < size; i++) {int currIndex = queue.poll();int maxJump = nums[currIndex];for (int j = 1; j <= maxJump; j++) {int nextIndex = currIndex + j;if (nextIndex >= n - 1) {// 如果能够跳到最后一个位置或超过最后一个位置,则返回当前步数+1return step + 1;}if (!visited[nextIndex]) {visited[nextIndex] = true;queue.offer(nextIndex);}}}step++;}return -1; // 如果无法达到最后一个位置,则返回 -1}
}
在这个实现中,我们使用一个队列 queue 来广度优先搜索每个位置能够跳跃到的下一个位置。
- 初始时,我们将起始位置加入队列,并将其标记为已访问。
- 然后,我们不断从队列中取出当前位置,遍历它能够跳跃的最大长度内的所有位置。如果遍历过程中发现某个位置能够跳到最后一个位置或超过最后一个位置,则返回当前步数+1,表示跳跃结束。
- 如果无法达到最后一个位置,则返回 -1。
复杂度分析:
时间复杂度:
- 遍历数组的过程中,每个位置最多会被访问一次,因此遍历数组的时间复杂度是 O(n)。
- 在最坏情况下,队列中的元素数量可以达到 n,每个元素都需要进行扩展操作。在每个扩展操作中,需要遍历当前位置能够跳跃的最大长度内的所有位置。由于最大跳跃长度的上限是 n,因此每个位置进行扩展操作的时间复杂度是 O(n)。总的时间复杂度是 O(n^2)。
空间复杂度:
- 使用一个队列来保存当前位置,队列的最大长度不会超过 n,因此队列的空间复杂度是 O(n)。
- 使用一个布尔数组 visited 来记录已访问的位置,数组的长度与数组 nums 的长度相同,因此布尔数组的空间复杂度也是 O(n)。
- 总的空间复杂度是 O(n)。
需要注意的是,由于贪婪算法的效率更高,动态规划和广度优先搜索通常在处理较大输入规模时才会被使用。在小规模问题上,贪婪算法往往是更快的解决方法。
LeetCode运行结果:
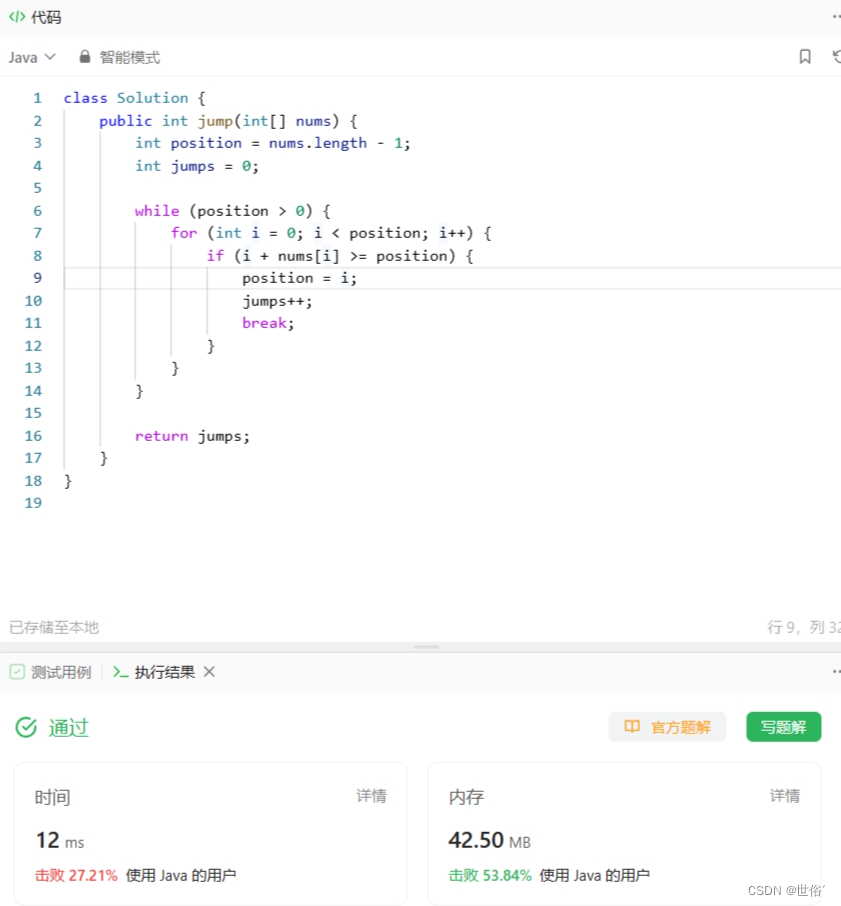
方法四:逆向贪婪算法
除了贪婪算法、动态规划和广度优先搜索,还有另外一种常用的解决方法,称为跳跃游戏问题的逆向贪婪算法。
逆向贪婪算法的基本思路是从目标位置开始向起始位置遍历,每次选择能够到达当前位置的最远跳跃位置作为新的目标位置,直到遍历到起始位置为止。这样可以得到从起始位置到目标位置的最小跳跃次数。
class Solution {public int jump(int[] nums) {int position = nums.length - 1;int jumps = 0;while (position > 0) {for (int i = 0; i < position; i++) {if (i + nums[i] >= position) {position = i;jumps++;break;}}}return jumps;}
}
在这个实现中,我们使用变量 position 来表示当前的目标位置,初始化为数组的最后一个位置。变量 jumps 记录跳跃次数,初始化为 0。
通过一个循环,我们从目标位置开始向起始位置遍历。内层循环遍历从当前位置到目标位置之间的所有位置,找到第一个能够跳跃到目标位置的位置,更新 position 和 jumps,然后继续向前遍历。
最终,返回 jumps 作为结果。
复杂度分析:
时间复杂度:
- 遍历数组进行内层循环时,最多需要执行 n 次,其中 n 是数组 nums 的长度。因此,内层循环的时间复杂度是 O(n)。
- 外层循环从目标位置开始,通过不断更新目标位置进行遍历,最多执行 n-1 次。因此,外层循环的时间复杂度是 O(n)。 综合起来,逆向贪婪算法的时间复杂度是 O(n)。
空间复杂度:
- 逆向贪婪算法只使用了常数级别的变量,没有使用额外的空间。因此,空间复杂度是 O(1)。
总结起来,逆向贪婪算法是一种时间复杂度为 O(n),空间复杂度为 O(1) 的解决方法。相比于动态规划和广度优先搜索等其他方法,它具有更低的时间复杂度,但需要注意的是,逆向贪婪算法的前提是能够到达目标位置,否则会陷入无限循环。
LeetCode运行结果: