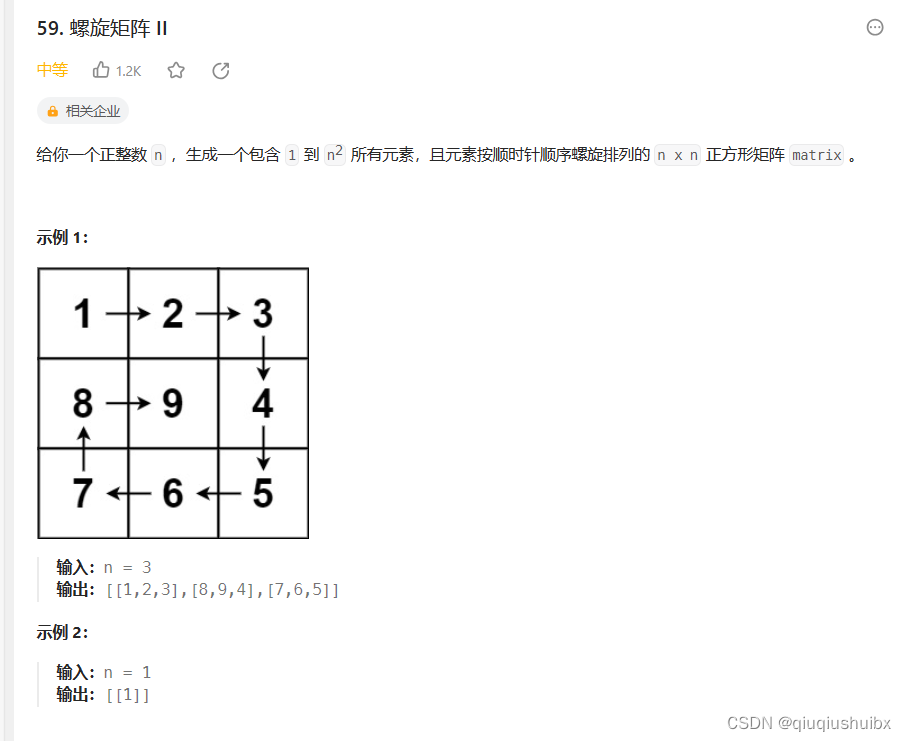
DTW算法介绍
DTW(Dynamic Time Warping):按距离最近原则,构建两个序列之间的对应的关系,评估两个序列的相似性。
要求:
- 单向对应,不能回头;
- 一一对应,不能有空;
- 对应之后,距离最近。
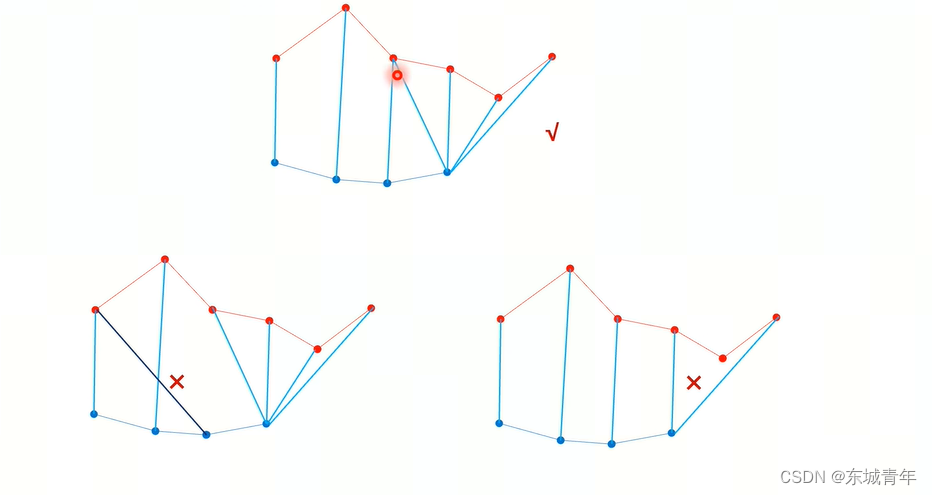


DTW代码实现
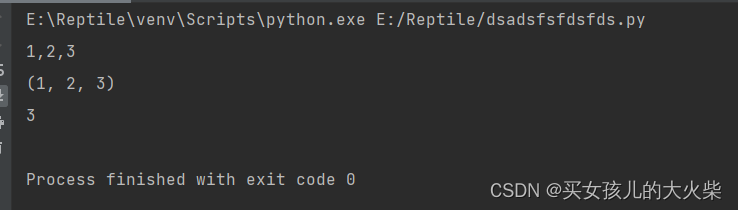
import numpy as npdef dis_abs(x, y):return abs(x - y)[0]def estimate_twf(A, B, dis_func=dis_abs):N_A = len(A)N_B = len(B)D = np.zeros([N_A, N_B])D[0, 0] = dis_func(A[0], B[0])# 左边一列for i in range(1, N_A):D[i, 0] = D[i - 1, 0] + dis_func(A[i], B[0])# 下边一行for j in range(1, N_B):D[0, j] = D[0, j-1] + dis_func(A[0], B[j])# 中间部分for i in range(1, N_A):for j in range(1, N_B):D[i, j] = dis_func(A[i], B[j]) + min(D[i-1, j], D[i, j-1], D[i-1][j-1])# 路径回溯i = N_A - 1j = N_B - 1cnt = 0d = np.zeros(max(N_A, N_B) * 3)path = []while True:if i > 0 and j > 0:path.append((i, j))m = min(D[i-1, j], D[i, j-1], D[i-1, j-1])if m == D[i-1, j-1]:d[cnt] = D[i,j] - D[i-1, j-1]i -= 1j -= 1cnt += 1elif m == D[i, j-1]:d[cnt] = D[i,j] - D[i, j-1]j -= 1cnt += 1elif m == D[i-1, j]:d[cnt] = D[i,j] - D[i-1, j]i -= 1cnt += 1elif i == 0 and j == 0:path.append((i, j))d[cnt] = D[i, j]cnt += 1breakelif i == 0:path.append((i, j))d[cnt] = D[i, j] - D[i, j-1]j -= 1cnt += 1elif j == 0:path.append((i, j))d[cnt] = D[i, j] - D[i-1, j]i -= 1cnt += 1mean = np.sum(d) / cntreturn mean, path[::-1], Da = np.array([1,3,4,9,8,2,1,5,7,3])
b = np.array([1,6,2,3,0,9,4,1,6,3])
a = a[:, np.newaxis]
b = b[:, np.newaxis]
dis, path, D = estimate_twf(a, b, dis_func=dis_abs)
print(dis, path, D)>>:
1.0833333333333333[(0, 0), (1, 1), (1, 2), (1, 3), (2, 4), (3, 5), (4, 5), (5, 6), (6, 7), (7, 8), (8, 8), (9, 9)]
[[ 0. 5. 6. 8. 9. 17. 20. 20. 25. 27.][ 2. 3. 4. 4. 7. 13. 14. 16. 19. 19.][ 5. 4. 5. 5. 8. 12. 12. 15. 17. 18.][13. 7. 11. 11. 14. 8. 13. 20. 18. 23.][20. 9. 13. 16. 19. 9. 12. 19. 20. 23.][21. 13. 9. 10. 12. 16. 11. 12. 16. 17.][21. 18. 10. 11. 11. 19. 14. 11. 16. 18.][25. 19. 13. 12. 16. 15. 15. 15. 12. 14.][31. 20. 18. 16. 19. 17. 18. 21. 13. 16.][33. 23. 19. 16. 19. 23. 18. 20. 16. 13.]]基于DTW算法的命令字识别
utils.py:
# -*- coding:UTF-8 -*-
import streamlit as st
import pyaudio
import wave
import librosa
import soundfile as sf
import numpy as np
import os
import time# 采用MFCC特征使用mcd距离
def euclideanDistance(a, b):diff = a - bmcd = 10.0 / np.log(10) * np.sqrt(2.0 * np.sum(diff ** 2))return mcd# DTW算法匹配距离
class DTW:def __init__(self, disFunc=euclideanDistance):self.disFunc = disFuncdef compute_distance(self, reference, test):DTW_matrix = np.empty([reference.shape[0], test.shape[0]])DTW_matrix[:] = np.infDTW_matrix[0, 0] = 0for i in range(reference.shape[0]):for j in range(test.shape[0]):cost = self.disFunc(reference[i, :], test[j, :])r_index = i - 1c_index = j - 1if r_index < 0:r_index = 0if c_index < 0:c_index = 0DTW_matrix[i, j] = cost + min(DTW_matrix[r_index, j], DTW_matrix[i, c_index],DTW_matrix[r_index, c_index])return DTW_matrix[-1, -1] / (test.shape[0] + reference.shape[0])# 语音录制
class wordRecorder:def __init__(self, samplingFrequency=8000, threshold=20):self.samplingFrequency = samplingFrequencyself.threshold = thresholddef record(self):p = pyaudio.PyAudio()stream = p.open(format=pyaudio.paInt16, channels=1, rate=self.samplingFrequency, input=True, output=False,frames_per_buffer=1024)frames = []for i in range(int(self.samplingFrequency * 4 / 1024)):data = stream.read(1024)frames.append(data)stream.stop_stream()stream.close()p.terminate()return framesdef record2File(self, path):frames = self.record()p = pyaudio.PyAudio()with wave.open(path, 'wb') as wf:wf.setnchannels(1)wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))wf.setframerate(self.samplingFrequency)wf.writeframes(b''.join(frames))print('record finished!')# 提取mfcc特征
def getmfcc(audio, isfile=True):if isfile:# 读取音频文件y, fs = librosa.load(audio, sr=8000)else:# 音频数据,需要去除静音y = np.array(audio)intervals = librosa.effects.split(y, top_db=20)y = librosa.effects.remix(y, intervals)# 预加重y = librosa.effects.preemphasis(y)fs = 8000N_fft = 256win_length = 256hop_length = 128n_mels = 23n_mfcc = 14# mfcc提取mfcc = librosa.feature.mfcc(y=y, sr=fs, n_mfcc=n_mfcc, n_mels=n_mels, n_fft=N_fft, win_length=win_length,hop_length=hop_length)mfcc = mfcc[1:, :]# 添加差分量mfcc_deta = librosa.feature.delta(mfcc)mfcc_deta2 = librosa.feature.delta(mfcc, order=2)# 特征拼接mfcc_d1_d2 = np.concatenate([mfcc, mfcc_deta, mfcc_deta2], axis=0)return mfcc_d1_d2.T# 指定文件夹下文件个数
def check_file(name):os.makedirs('data', exist_ok=True)save_dir = os.path.join('data', name)os.makedirs(save_dir, exist_ok=True)n_files = 0for roots, dirs, files in os.walk(save_dir):for file in files:if file.endswith('.wav'):n_files += 1return n_files@st.cache_resource # 防止重载
def model_load():model1 = ModelHotWord(os.path.join('data', '向上'))model2 = ModelHotWord(os.path.join('data', '向下'))model3 = ModelHotWord(os.path.join('data', '向左'))model4 = ModelHotWord(os.path.join('data', '向右'))models = [model1, model2, model3, model4]return modelsclass ModelHotWord(object):def __init__(self, path):self.mfccs = get_train_mfcc_list(path)def get_score(self, ref_mfcc):return get_score(ref_mfcc, self.mfccs)def get_train_mfcc_list(data_path):mfccs = []for roots, dirs, files in os.walk(data_path):for file in files:if file.endswith('wav'):file_audio = os.path.join(data_path, file)mfcc = getmfcc(file_audio)mfccs.append(mfcc)return mfccsdef get_score(ref_mfcc, list_mfccs):m_dtw = DTW()N = len(list_mfccs)scores = 0for i in range(N):dis = m_dtw.compute_distance(ref_mfcc, list_mfccs[i])scores = scores + disreturn scores / NDTW.py:
# -*- coding:UTF-8 -*-
from utils import *st.title('基于DTW算法的命令字识别')
tab1, tab2 = st.tabs(['音频录制', '识别演示'])with tab1:list_labs = ['向上', '向下', '向左', '向右']col1, col2, col3, col4 = st.columns(4)with col1:name = st.selectbox('模型选择', list_labs)with col2:st.write('命令字录制')flag_record = st.button(label='录音')with col3:st.write('命令字重录')flag_cancel = st.button(label='撤销')with col4:st.write('试听')flag_show_audios = st.button(label='试听')info_file_number = st.empty()info_file_number.write('命令字---%s--已有%d个样本'%(name, check_file(name)))info_audios = st.empty()
info_success = st.empty()
if flag_record:info_audios.info('')info_success.success('') n_files = check_file(name)info_audios.info('开始录制---第%d个命令字---%s--请在2s内完成录制.....'%(n_files + 1, name))save_dir = os.path.join('data', name)audio_name = os.path.join(save_dir, '%d.wav'%(n_files + 1))wRec = wordRecorder()wRec.record2File(audio_name)info_success.success('录制完成,保存为' + audio_name)if flag_cancel:n_files = check_file(name)save_dir = os.path.join('data', name)file_del = os.path.join(save_dir, str(n_files)+'.wav')os.remove(file_del)info_file_number.write('命令字--%s--已有%d个样本'%(name, check_file(name)))if flag_show_audios:n_files = check_file(name)save_dir = os.path.join('data', name)if n_files > 0:for i in range(n_files):audio_file = open(os.path.join(save_dir, '%d.wav'%(i+1)), 'rb')audio_bytes = audio_file.read()st.audio(audio_bytes, format='audio/')with tab2:th = 125st.write('识别演示')if 'run' not in st.session_state:st.session_state['run'] = Falsedef start_listening():st.session_state['run'] = Truedef stop_listening():st.session_state['run'] = Falsecol1, col2 = st.columns(2)with col1:st.button('开始检测', on_click=start_listening)with col2:st.button('停止检测', on_click=stop_listening)det_word = st.empty()def init_up():det_word.write('向上')def init_down():det_word.write('向下')def init_left():det_word.write('向左')def init_right():det_word.write('向右')callbacks = [init_up, init_down, init_left, init_right]# 加载预测模型,提取好的一些mfcc特征models = model_load()dic_labs = {'0': '向上', '1': '向下', '2': '向左', '3': '向右', '-1': ''}while st.session_state['run']: # 循环进行检测wRec = wordRecorder()wRec.record2File('data/test.wav')ref_mfcc = getmfcc('data/test.wav', True)# 在每个模型上进行打分,扎到最小分数作为检测结果scores = [model.get_score(ref_mfcc) for model in models]i_word = np.argmin(scores)score = np.min(scores)print(i_word, score)if score < th:i_det_word = i_wordcallback = callbacks[i_det_word]if callback is not None:callback()print('---------det word---------', dic_labs[str(i_det_word)])else:continue python命令行运行streamlit run DTW.py即会出现web网页ui,结果如下图所示:

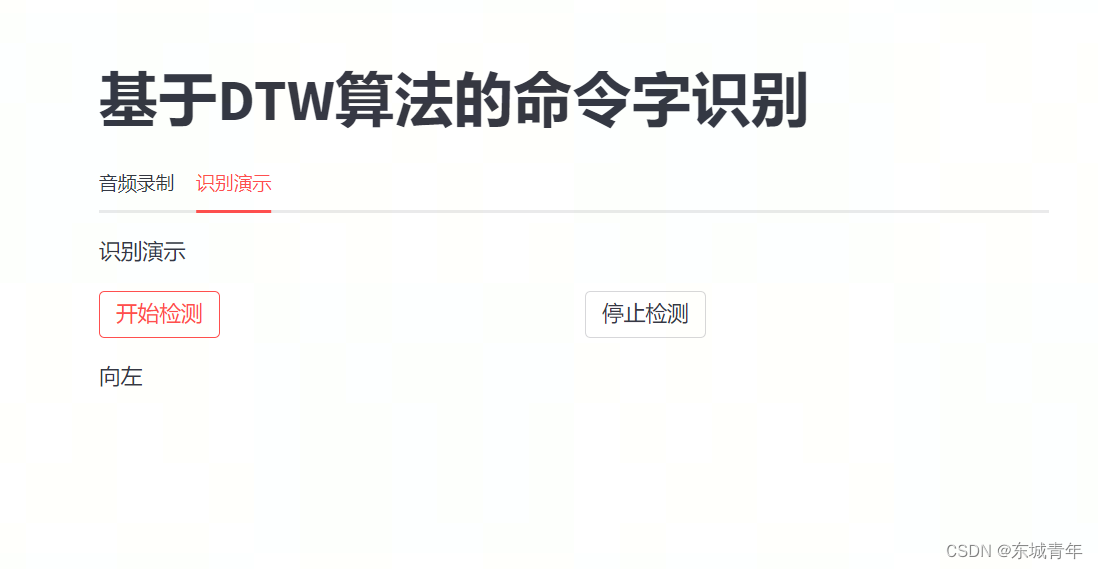
参考DTW关键字检测-代码实现_哔哩哔哩_bilibili