Moe 混合多专家模型 原理 + 大模型的有性繁殖
- MoE 介绍
- 标准 Transformer 编码器
- MoE Transformer 编码器
- 专家网络层
- 大模型的有性繁殖
- mergekit 合并 多个专家模型 的方式
- 1. SLERP(球面线性插值)
- 2. TIES
- 3. DARE
- 4. Passthrough
- 5. Linear
- mergekit 合并 多个专家模型 实操
MoE 介绍
大模型最开始设计思路是 — 通用。
一个通才能够处理多个不同的任务,但一群专家能够更高效、更专业地解决多个问题。
- Moe 混合多专家模型:术业有专攻,将任务分类,分给多个专家解决
与一个“通才网络”相比,一组术业有专攻的“专家网络”能够:
-
让用户获得更快的响应速度
-
提供更好的模型性能 — 每个专家模型都能针对不同的数据分布和构建模式进行搭建
-
更好地完成复杂的多种任务
-
在不显著增加计算成本的情况下大幅增加模型容量
-
开发时间更短
让一个大模型既代码牛逼,又医疗牛逼,还数学、角色扮演牛逼,你得烧多少算力、买多少数据,即使做到,项目开发周期非常长,搞不好新技术出来又颠覆了。
-
模型越大,性能越好。
今天的大模型,正迫切地需要变得更大。
随着模型越来越大,稳定性也越来越差,种种综合原因让大模型参数量长久以来限制在百亿与千亿级别,难以进一步扩大。
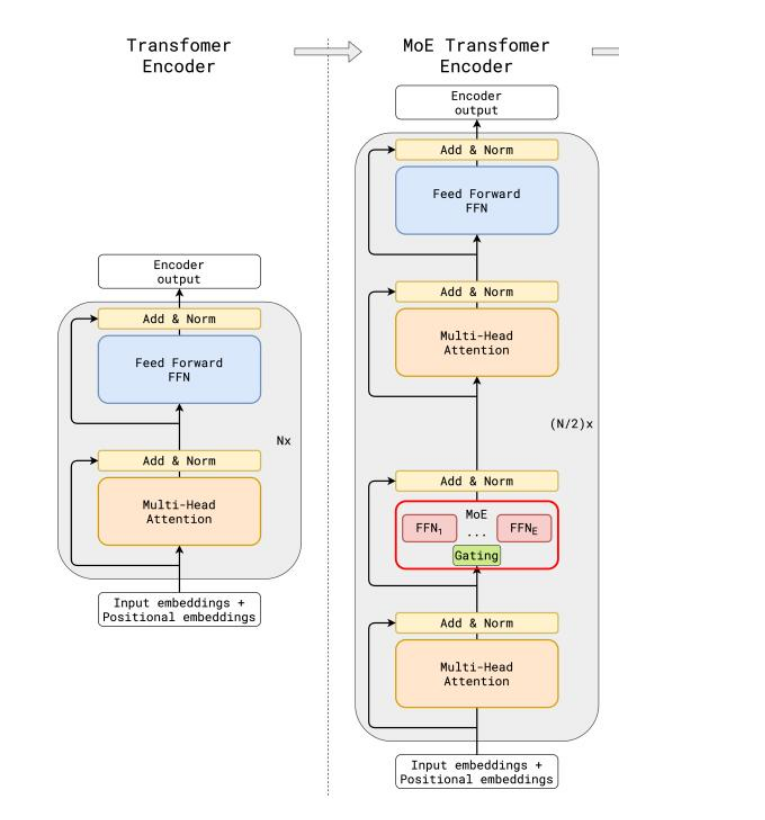
这张图对比了标准 Transformer 编码器(左侧)和 MoE(专家混合)Transformer 编码器(右侧)的架构。
-
MoE Transformer 编码器引入了MoE(专家混合)层,而标准 Transformer 编码器没有。
-
与传统大模型架构相比,MoE架构在数据流转过程中集成了一个专家网络层(红框部分)。
标准 Transformer 编码器
- 输入嵌入 + 位置嵌入:输入的嵌入向量和位置嵌入。
- 多头注意力机制:使用多头注意力机制来捕捉输入序列中不同位置之间的关系。
- 加法 & 归一化:将多头注意力机制的输出与输入进行残差连接,并进行归一化处理。
- 前馈神经网络(FFN):通过一个全连接的前馈神经网络对归一化后的输出进行进一步的处理。
- 加法 & 归一化:将前馈神经网络的输出与其输入进行残差连接,并进行归一化处理。
- 重复 Nx 次:上述步骤重复 N 次,得到编码器的最终输出。
MoE Transformer 编码器
- 输入嵌入 + 位置嵌入:输入的嵌入向量和位置嵌入。
- 多头注意力机制:使用多头注意力机制来捕捉输入序列中不同位置之间的关系。
- 加法 & 归一化:将多头注意力机制的输出与输入进行残差连接,并进行归一化处理。
- MoE 层:包含多个前馈神经网络(FFN₁, …, FFNₑ)。通过一个门控机制(Gating)来选择和激活其中的一部分前馈神经网络。这种机制使得模型可以选择性地激活特定的专家,从而增强模型的表示能力。
- 加法 & 归一化:将MoE层的输出与其输入进行残差连接,并进行归一化处理。
- 重复 (N/2)x 次:上述步骤重复 (N/2) 次,得到编码器的最终输出。
这种架构设计通过引入专家混合机制,使得模型在处理复杂任务时更具灵活性和适应性,同时也能够更有效地利用计算资源。
专家网络层
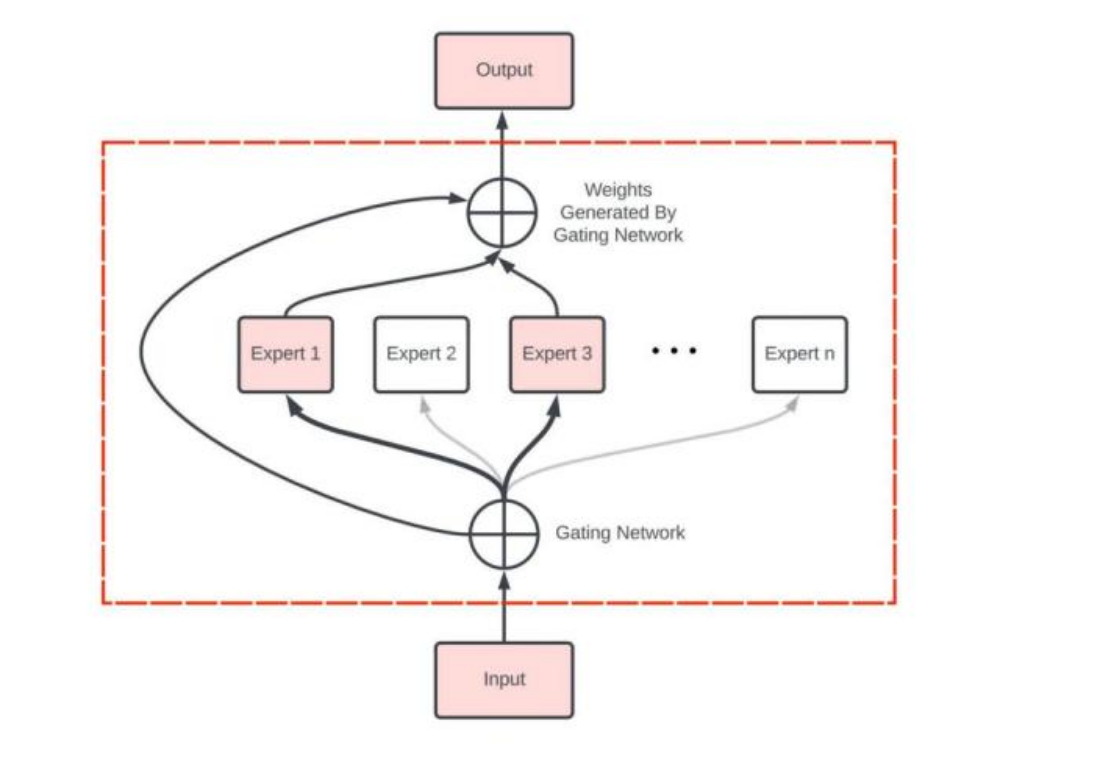
核心思想:
- 门控网络:负责智能分配任务,将不同特征的数据分配给最适合的专家。
- 专家模型:每个专家专注处理特定类型的数据特征,“让专业的人做专业的事”。
- 加权融合:将各个专家的处理结果融合,得到更精准的输出。
MoE 有两个参数:
- 专家数量 (num_local_experts):这决定架构中的专家总数,如 Mixtral-8x7B 有 8 个 7B 专家模型
- 专家数量/tonke (num_experts_per_tok):在每个层中,每个token会被分配到多少个专家模型进行处理。例如,如果num_experts_per_tok为2,那么每个token会被分配给2个专家模型。
Moe 实现俩种方式:
-
MoE(原装训练):从头设计和训练,所有部分都精心协调,更像是制造一辆全新的跑车。
-
frankenMoE(后天组合):基于现有模型进行改装和升级,重点在于如何有效组合和协调,更像是对现有汽车进行高性能改装。
大模型的有性繁殖
mergekit 合并 多个专家模型 的方式
https%3A//github.com/arcee-ai/mergekit%23merge-methods
mergekit 有 7 种合并方式。
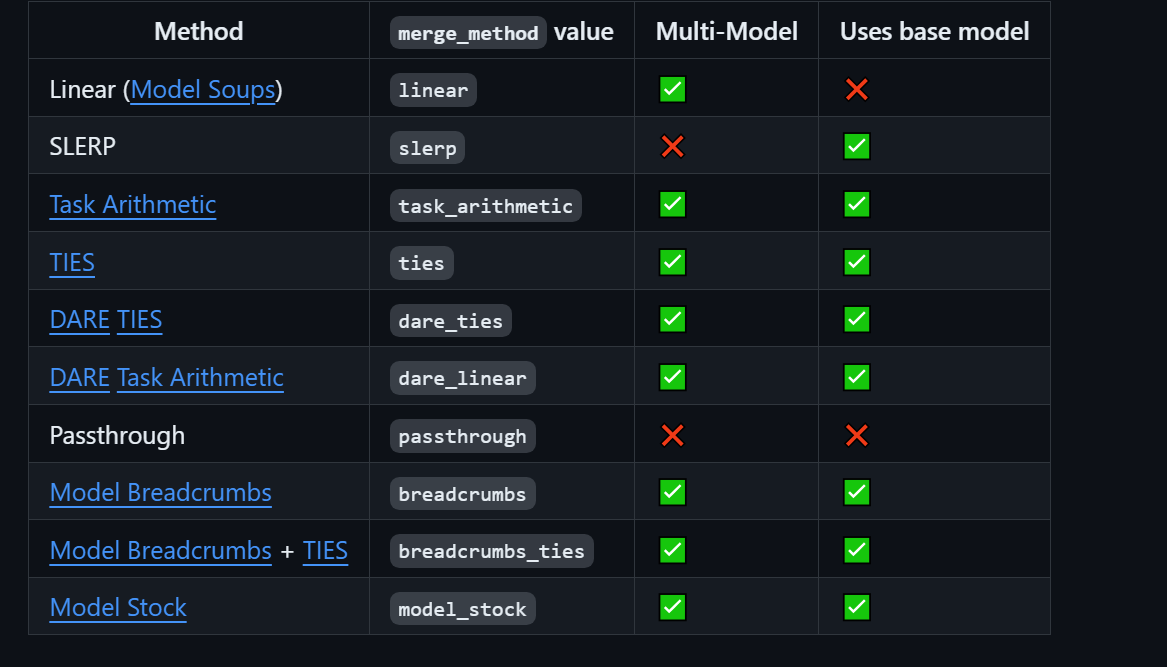
1. SLERP(球面线性插值)
问题:
为什么在某些情况下需要使用球面插值(SLERP)而不是线性插值?
解法:
在某些情况下,线性插值可能无法准确表示数据或模拟对象之间的连续变化,特别是涉及到在球面上的插值时。
为了保持曲线的平滑性和连续性,需要使用球面插值(SLERP)。
概念:
- SLERP是一种在两个向量之间进行平滑插值的方法,保持恒定的变化率,并保留向量所在的球形空间的几何属性。
- 主要用于两个模型的合并,通过插值获得平滑过渡。
步骤:
- 将输入向量归一化为单位长度。
- 使用它们的点积计算这些向量之间的角度。
- 根据角度进行插值,生成新向量。
2. TIES
概念:
- TIES旨在将多个特定任务的模型合并为一个多任务模型。
- 通过修剪冗余参数和解决符号冲突来优化合并过程。
步骤:
- 修剪:只保留最重要的参数,将其余参数重置为零。
- 选择符号:创建统一的符号向量,表示所有模型中最主要的变化方向。
- 不相交合并:平均对齐的参数值,不包括零值。
3. DARE
概念:
- 类似于TIES,但在修剪和重新缩放权重上有所不同。
- 将微调的权重随机重置为原始值,并重新缩放权重以保持模型输出预期不变。
步骤:
- 修剪:随机重置微调的权重为原始值。
- 重新缩放:重新缩放权重,使其与基本模型权重相结合。
4. Passthrough
概念:
- 与其他方法不同,Passthrough通过连接来自不同LLM(大规模语言模型)的层生成模型。
- 适用于创建大参数模型。
步骤:
- 直接连接来自不同模型的层。
- 生成一个新的模型,结合了多个模型的参数。
总结:
- SLERP:适用于在两个模型之间进行平滑插值,保持向量几何属性。
- TIES:通过修剪冗余参数和解决符号冲突来有效合并多个模型。
- DARE:类似TIES,但在权重修剪和重新缩放上有所不同,保持输出预期不变。
- Passthrough:通过连接不同模型的层创建大参数模型,适用于生成更强大的模型。
5. Linear
Linear就是一个简单的加权平均。
mergekit 合并 多个专家模型 实操
mergekit:https://github.com/arcee-ai/mergekit