编程能力,就是解决问题的能力,也是变优秀的能力
From 生物技能树 R语言基础第七节
文章目录
- 1.长脚本管理方式
- if(F){....}
- 分成多个脚本,每个脚本最后保存Rdata,下一个脚本开头清空再加载
- 2.实战项目的组织方式
- 方法(一)
- 方法(二)
- 在这里插入图片描述
- 3.条件和循环
- if条件语句
- if(){ } 如果。。。就。。。
- if(){ } else{ },如果。。。就。。。否则。。。
- 重点:ifelse函数
- ifelse()+str_detect(),王炸
- 多个条件
- case_when
- 练习7-2
- 4.for循环
- 批量画图
- 批量装包
- 5.隐式循环
- 矩阵/数据框的隐式循环-apply()族函数
- lapply(list, FUN, …)
- 思考题:
- 1.如何挑出一个数里最大的5个?
- 课后思考题:
- 2.如何挑出一个表达矩阵里方差最大的1000个基因?(test2.Rdata里有表达矩阵)
- 6.两个数据框的连接
- inner_join:取交集
- full_join:全连接
- left_join:左连接
- right_join:右连接
- 练习7-3:
- 7.表达矩阵画箱线图(难懂)
- 8.一些顶呱呱的函数
- 遇到报错困惑
- 找不到文件
- 找不到函数
- 不存在包
- 找不到对象
- R语言重点
- 1.match-----
- 2.一些搞文件的函数----
1.长脚本管理方式
if(F){…}
1.if(F){....},则{ }里的代码被跳过
if(T){....},则{ }里的代码被运行
凡是带有{ }的代码,均可以被折叠。
if(F){a=1b=a^2d=a+b+a^2
}if(T){a=1b=a^2d=a+b+a^2
}
#凡是带有{ }的代码,均可以被折叠。
使用情况 1:例如下载数据的代码,保留但不反复运行

分成多个脚本,每个脚本最后保存Rdata,下一个脚本开头清空再加载

save(pd,exp,gpl,file = "steplouput.Rdata")
#把第一个脚本产生的几个有效变量存下来了,存到Rdata里边,下次直接load Rdata
rm(list = ls()) #每个脚本运行之前都记得清空环境变量哦
为什么用Rdata而不是表格文件来衔接
1.变量,自带变量名称,不需要赋值,也没有参数
2.表格文件,需要赋值,读取参数的不同会导致读取结果不同,不能在后续代码里同等处理。
3.Rdata可以一次保存多个变量,下次只需要一次load就能得到多个数据。
4.Rdata不仅可以保存数据框,还可以保存其他任何数据结构。
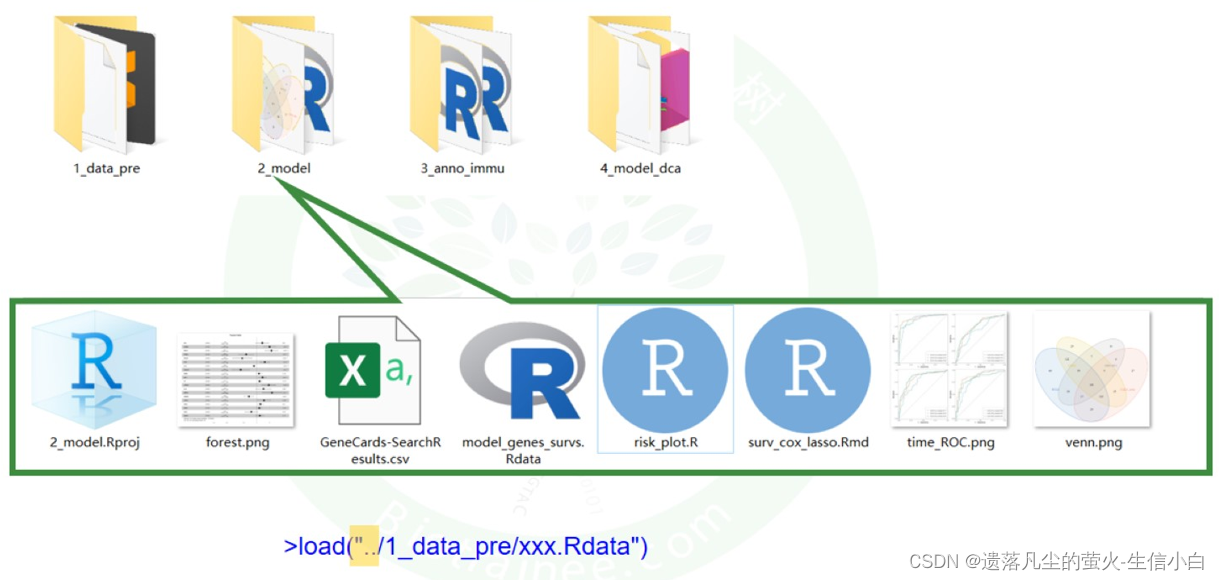
2.实战项目的组织方式
方法(一)

方法(二)
每一步设置一个文件夹,每一个文件夹里都有一个project,一个文件夹和另一个文件夹作为工作目录的时候就涉及到工作目录的切换了
#相对路径,不推荐使用绝对路径
../ 工作目录的上一级,可以访问隔壁文件夹的project
3.条件和循环
if条件语句
if(){ } 如果。。。就。。。
(1)只有if没有else,那么条件是FALSE时就什么都不做
提示:if()的括号里是一个逻辑值,不可以是多个逻辑值组成的向量
i = -1
if (i<0) print('up')[1] "up"if (i>0) print('up')
理解下面代码
就是之前用来装包的代码
if(!require(tidyr)) install.packages('tidyr')
if(){ } else{ },如果。。。就。。。否则。。。
(2)有else
i = -1
if (i>0){print('+')
} else {print("-")
}
重点:ifelse函数

> ifelse(i>0,"+","-")
[1] "-"
> x = rnorm(3)
> x
[1] -1.6343950 0.1812335 0.4729793
> ifelse(x>0,"+","-")
[1] "-" "+" "+"
ifelse()+str_detect(),王炸
library(stringr)
samples = c("tumor1","tumor2","tumor3","normal1","normal2","normal3")
k1 = str_detect(samples,"tumor");k1
[1] TRUE TRUE TRUE FALSE FALSE FALSE
ifelse(k1,"tumor","normal")
[1] "tumor" "tumor" "tumor" "normal" "normal" "normal"
#此刻代码也不会报错,但是输出错误
samples = c("tumor1","tumor2","tumor3","normal1","normal2","normal3")
k2 = str_detect(samples,"normal");k2
[1] FALSE FALSE FALSE TRUE TRUE TRUE
ifelse(k2,"tumor","normal")
[1] "normal" "normal" "normal" "tumor" "tumor" "tumor"
#更改为
ifelse(k2,"normal","tumor")
[1] "tumor" "tumor" "tumor" "normal" "normal" "normal"
多个条件
#else后面直接跟if就可以实现多个条件
i = 0
if (i>0){print('+')
} else if (i==0) {print('0')
} else if (i< 0){print('-')
}[1] "0"
#两个==是比较运算
或者写嵌套,一样的效果
ifelse(i>0,"+",ifelse(i<0,"-","0"))[1] "0"
case_when
#让代码变得容易读,最后一种情况~前面写T就行
x = c(-1,-1,4,5,2,0)
case_when(x > 0 ~ "A",x == 0 ~ "0",T ~ "B")[1] "B" "B" "A" "A" "A" "0"
练习7-2
1.加载deg.Rdata,根据a、b两列的值,按照以下条件生成向量x:
#a< -1 且b<0.05,则x对应的值为down;
#a>1 且b<0.05,则x对应的值为up;
#其他情况,x对应的值为no
#统计up、down、no各出现了多少次
#提示:ifelse函数
#方法一
load("deg.Rdata")
k1 = deg$a < -1 & deg$b < 0.05
k2 = deg$a > 1 & deg$b < 0.05
x = table(case_when(k1 ~ "down",k2 ~ "up",T ~ "no"))
x
#也可以
load("deg.Rdata")
k1 = deg$a < -1 & deg$b < 0.05;table(k1)
k2 = deg$a > 1 & deg$b < 0.05;table(k2)
x = case_when(k1 ~ "down",k2 ~ "up",T ~ "no")
table(x)
#方法二
x = table(ifelse(k1,"down",ifelse(k2,"up","no")));x#运行结果down no up 1059 28863 853
4.for循环
#对x里的每个元素i进行同一操作
格式:for( i in x){CODE}
for( i in 1:4){print(i)
}## [1] 1
## [1] 2
## [1] 3
## [1] 4
i遍历x的值,当运行完最后一个x的值的时候,就会停下
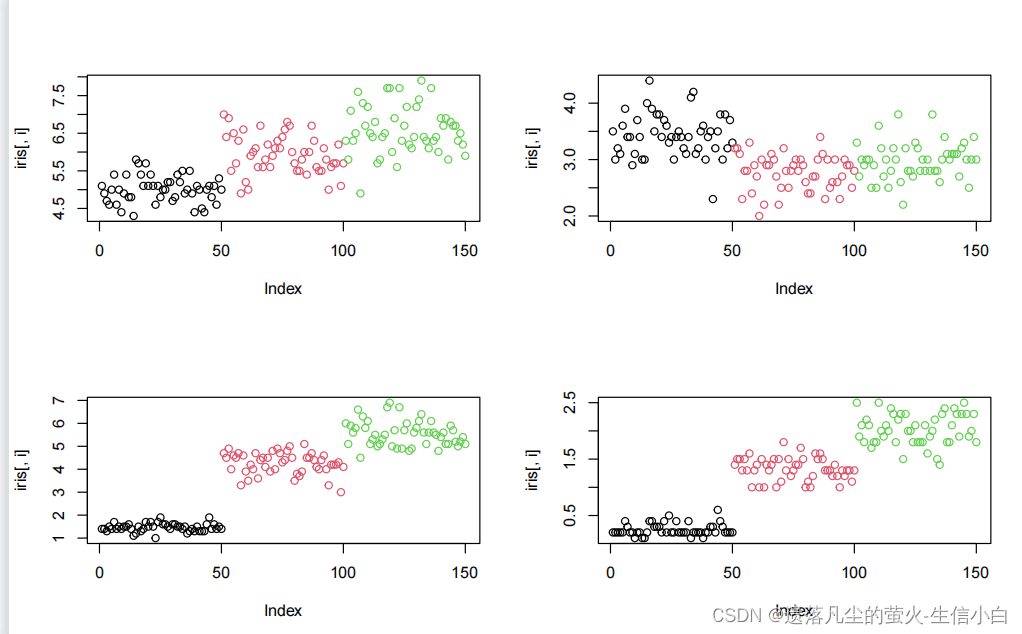
批量画图
#批量画图,#把画板分隔成4块,#用4列画4张图
par(mfrow = c(2,2))
for(i in 1:4){plot(iris[,i],col = iris[,5])
}
批量装包
#批量装包
pks = c("tidyr","dplyr","stringr")
for(g in pks){if(!require(g,character.only = T))install.packages(g,ask = F,update = F)
}
5.隐式循环
矩阵/数据框的隐式循环-apply()族函数
1.apply 处理矩阵或数据框
apply(X, MARGIN, FUN, …)
其中X是数据框/矩阵名
MARGIN为1表示行,为2表示列,FUN是函数
对x的每一行/每一列进行FUN函数
rm(list = ls())
test<- iris[1:6,1:4]apply(test, 2, mean) ##对每一列求平均值
apply(test, 1, sum) ##对每一行求总和,结果是一个向量,上面的一行是向量的名字
lapply(list, FUN, …)
对列表/向量中的每个元素实施相同的操作
lapply(1:4,rnorm)## [[1]]
## [1] -0.844006
##
## [[2]]
## [1] 1.3602517 0.2277469
##
## [[3]]
## [1] 0.5345012 -0.7476097 -0.8925600
##
## [[4]]
## [1] -0.8469975 0.2791090 -0.5900125 0.3493904
#输出结果是list
思考题:
1.如何挑出一个数里最大的5个?
方法一:x = rnorm(30);xx <- sort(x,decreasing = T)head(x,5)}方法二:x = rnorm(30);xsort(x)tail(sort(x),5)#[1] 2.430152 2.030683 1.338829 1.095946 0.754246
找topn差异基因的思路,有时候依靠排序就能很好的解决
课后思考题:
2.如何挑出一个表达矩阵里方差最大的1000个基因?(test2.Rdata里有表达矩阵)
1.计算每个基因的方差
2.每个基因的方差排序
3.最后1000个数字所对应的基因
#统计元素
x = list(a = 1:10,b = rnorm(16),c = seq(1,3,0.1))
lapply(x,length)##$a
[1] 10
##$b
[1] 16
##$c
[1] 21
#查看数据类型x = list(a = 1:10,b = rnorm(16),c = seq(1,3,0.1))
lapply(x,class)##$a
[1] "integer"
##$b
[1] "numeric"
##$c
[1] "numeric"
x = list(a = 1:10,b = rnorm(16),c = seq(1,3,0.1))
sapply(x,sum)##> sapply(x,sum)a b c
55.0000000 -0.4830007 42.0000000
6.两个数据框的连接
inner_join:取交集
> test1 <- data.frame(name = c('jimmy','nicker','Damon','Sophie'),
+ blood_type = c("A","B","O","AB"))
> test1name blood_type
1 jimmy A
2 nicker B
3 Damon O
4 Sophie AB
> test2 <- data.frame(name = c('Damon','jimmy','nicker','tony'),
+ group = c("group1","group1","group2","group2"),
+ vision = c(4.2,4.3,4.9,4.5))
> test2name group vision
1 Damon group1 4.2
2 jimmy group1 4.3
3 nicker group2 4.9
4 tony group2 4.5
> library(dplyr)
> inner_join(test1,test2,by="name")name blood_type group vision
1 jimmy A group1 4.3
2 nicker B group2 4.9
3 Damon O group1 4.2
>
full_join:全连接
##全连接:取并集,多出来的行空着NA
> full_join(test1,test2,by="name")name blood_type group vision
1 jimmy A group1 4.3
2 nicker B group2 4.9
3 Damon O group1 4.2
4 Sophie AB <NA> NA
5 tony <NA> group2 4.5
left_join:左连接
左边表里的留下,右边表里的舍去
#左连接:以左边的数据框为准,右边多余的去掉,并连接
> left_join(test1,test2,by="name")
> name blood_type group vision
1 jimmy A group1 4.3
2 nicker B group2 4.9
3 Damon O group1 4.2
4 Sophie AB <NA> NA
right_join:右连接
#右连接:以右边的数据框为准,左边多余的去掉,并连接
right_join(test1,test2,by="name")
name blood_type group vision
1 jimmy A group1 4.3
2 nicker B group2 4.9
3 Damon O group1 4.2
4 tony <NA> group2 4.5
练习7-3:
- 加载test1.Rdata,将两个数据框按照probe_id列连接在一起,按共同列取交集
load("test1.Rdata")
library(dplyr)
inner_join(dat,ids,by="probe_id")
- 找出logFC最小的10个基因和logFC最大的10个基因(symbol列就是基因名)
load("test1.Rdata")
library(dplyr)
#取交集两种方式
x = inner_join(dat,ids,by="probe_id")
或
x = merge(dat,ids,by="probe_id")
#正在对数据框 x 根据 logFC 列进行排序,并把排序后的数据框重新赋值给变量 x。
x = arrange(x,logFC)
#取出最大的前十个
head(x$symbol,10)
#取出最小的后十个
tail(x$symbol,10)
7.表达矩阵画箱线图(难懂)
#在R语言中,set.seed() 函数用于设置随机数生成器的种子set.seed(10086)
rnorm(10)
# 表达矩阵#设置随机种子
set.seed(10086)
#生成了随机数矩阵,共6列,
创建一个6列3行的矩阵,包含从正态分布中抽取的18个随机数
exp = matrix(rnorm(18),ncol = 6)
#取整函数,或取小数点后几位,2为取小数点后2位
exp = round(exp,2)
#生成行名和列名
rownames(exp) = paste0("gene",1:3)
colnames(exp) = paste0("test",1:6)
#让1~3列数据都+1
exp[,1:3] = exp[,1:3]+1
exp
##输出结果print(exp)test1 test2 test3 test4 test5 test6
gene1 1.55 1.49 1.80 -0.37 -1.82 -1.62
gene2 -1.74 0.37 2.08 2.11 -0.22 1.42
gene3 1.57 1.25 1.32 2.49 0.58 -0.8
接下来进行变形的操作,让exp这个矩阵变成ggplot2可以接受的格式
首先需要把表达矩阵(宽型数据)变成长型数据:把所有的信息都置于同一行上
行名需要+1列另外放置,以防丢失
library(tidyr)
library(tibble)
library(dplyr)
#t() 函数用于转置矩阵,即交换矩阵的行和列。
dat = t(exp) %>%
#将转置后的矩阵转换为数据框(data frame) as.data.frame() %>%
#这个函数将数据框的行名作为一列添加到数据框中。注意,这个函数是 tibble 包提供的,所以确保已经安装并加载了 tibble rownames_to_column() %>%
#mutate() 函数用于添加新的列到数据框中。这里,它添加了一个名为 group 的新列,该列是通过 rep() 函数重复 "control" 和 "treat" 字符串来生成的,每个字符串重复3次。mutate(group = rep(c("control","treat"),each = 3))
分步进行宽变长:
先把矩阵转置
变成数据框
把rownames变成一列
手动设置一下组别
pdat = dat%>% pivot_longer(cols = starts_with("gene"),names_to = "gene",values_to = "count")
print(pdat)
也可以直接用宽变长的函数pivot_longer
cols=指要变成同一列的基因名
names_to指新的基因名那一列的列名
values_to指数值那一列的列名
剩下的内容会跟着一起变化
> print(pdat)
# A tibble: 18 × 4rowname group gene count<chr> <chr> <chr> <dbl>1 test1 control gene1 1.552 test1 control gene2 -1.743 test1 control gene3 1.574 test2 control gene1 1.495 test2 control gene2 0.376 test2 control gene3 1.257 test3 control gene1 1.8 8 test3 control gene2 2.089 test3 control gene3 1.32
10 test4 treat gene1 -0.37
11 test4 treat gene2 2.11
12 test4 treat gene3 2.49
13 test5 treat gene1 -1.82
14 test5 treat gene2 -0.22
15 test5 treat gene3 0.58
16 test6 treat gene1 -1.62
17 test6 treat gene2 1.42
18 test6 treat gene3 -0.81
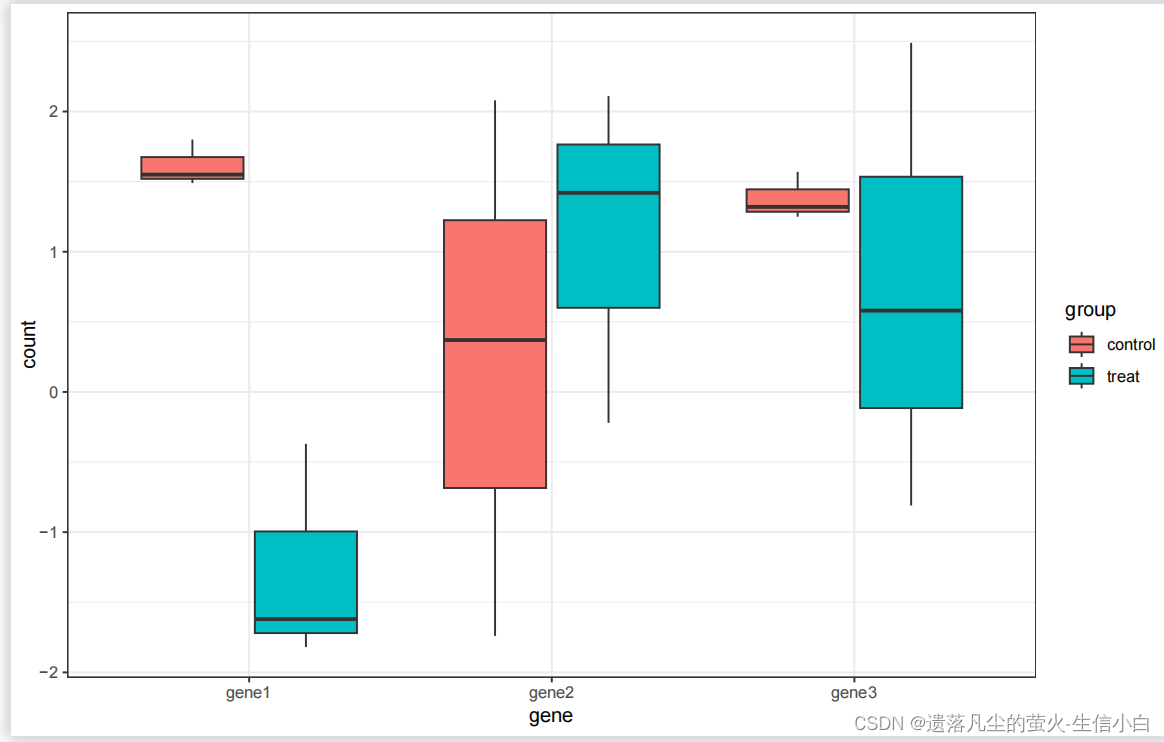
library(ggplot2)
p = ggplot(pdat,aes(gene,count))+geom_boxplot(aes(fill = group))+theme_bw()
p
8.一些顶呱呱的函数
match()
dir()
file.create()
file.exists()
file.remove()
遇到报错困惑
找不到文件
原因:工作目录有问题,应该用project打开Rstudio,在写文件的时候用tab键自动补齐
找不到函数
用tab键自动补齐,检查函数名称,是否在R包里的函数,没有加载R包
不存在包
安装即可
找不到对象
引号,或赋值
R语言重点




![数字集成电路物理设计[陈春章]——知识总结与精炼02](https://img-blog.csdnimg.cn/direct/0a71ce49257f427bac166388e80f795d.png)




![BUUCTF靶场[MISC]荷兰宽带数据泄露、九连环](https://img-blog.csdnimg.cn/direct/2116ffe2e1fc47e7b8fe36740a59ae87.png)