Rethinking the Paradigm of Content Constraints in Unpaired Image-to-Image Translation
非成对意象翻译中的内容制约范式再思考
蔡秀定 1 2 、朱瑶瑶 1 2 、苗东 1 2 、付林杰 1 2 、余瑶 1 2
Corresponding author. 通讯作者。
Abstract 摘要
In an unpaired setting, lacking sufficient content constraints for image-to-image translation (I2I) tasks, GAN-based approaches are usually prone to model collapse. Current solutions can be divided into two categories, reconstruction-based and Siamese network-based. The former requires that the transformed or transforming image can be perfectly converted back to the original image, which is sometimes too strict and limits the generative performance. The latter involves feeding the original and generated images into a feature extractor and then matching their outputs. This is not efficient enough, and a universal feature extractor is not easily available. In this paper, we propose EnCo, a simple but efficient way to maintain the content by constraining the representational similarity in the latent space of patch-level features from the same stage of the Encoder and deCoder of the generator. For the similarity function, we use a simple MSE loss instead of contrastive loss, which is currently widely used in I2I tasks. Benefits from the design, EnCo training is extremely efficient, while the features from the encoder produce a more positive effect on the decoding, leading to more satisfying generations. In addition, we rethink the role played by discriminators in sampling patches and propose a discriminative attention-guided (DAG) patch sampling strategy to replace random sampling. DAG is parameter-free and only requires negligible computational overhead, while significantly improving the performance of the model. Extensive experiments on multiple datasets demonstrate the effectiveness and advantages of EnCo, and we achieve multiple state-of-the-art compared to previous methods. Our code is available at https://github.com/XiudingCai/EnCo-pytorch.
在不成对的设置中,缺乏足够的图像到图像翻译(I2I)任务的内容约束,基于GAN的方法通常容易出现模型崩溃。目前的解决方案可以分为两类,基于重建和基于暹罗网络。前者要求变换后或变换后的图像能够完美地转换回原始图像,这有时过于严格,限制了生成性能。后者涉及将原始图像和生成的图像馈送到特征提取器中,然后匹配它们的输出。这是不够有效的,并且通用特征提取器不容易获得。在本文中,我们提出了EnCo,一个简单但有效的方式来保持内容的约束代表相似性的潜在空间的补丁级功能从同一阶段的编码器和解码器的发电机。 对于相似性函数,我们使用简单的MSE损失而不是目前广泛用于I2I任务的对比损失。得益于这种设计,EnCo训练非常高效,而编码器的特征对解码产生了更积极的影响,从而产生了更令人满意的生成。此外,我们重新思考的作用所发挥的鉴别器在采样补丁,并提出了一个歧视性的注意力引导(DAG)补丁采样策略,以取代随机采样。DAG是无参数的,只需要微不足道的计算开销,同时显着提高模型的性能。在多个数据集上的大量实验证明了EnCo的有效性和优势,与以前的方法相比,我们实现了多个最先进的方法。我们的代码可在https://github.com/XiudingCai/EnCo-pytorch上获得。
Introduction 介绍
Image-to-image translation (I2I) aims to convert images from one domain to another with content preserved as much as possible. I2I tasks have received a lot of attention given their wide range of applications, such as style transfer (Ulyanov, Vedaldi, and Lempitsky 2016), semantic segmentation (Yu, Koltun, and Funkhouser 2017; Kirillov et al. 2020), super resolution (Yuan et al. 2018), colorization (Zhang, Isola, and Efros 2016), dehazing (Dong et al. 2020) and image restoration (Liang et al. 2021) etc.
图像到图像翻译(I2I)旨在将图像从一个域转换到另一个域,并尽可能保留内容。I2I任务由于其广泛的应用而受到了广泛的关注,例如样式传输(Ulyanov,Vedaldi和Lempitsky 2016),语义分割(Yu,Koltun和Funkhouser 2017;Kirillov等人,2020年),超分辨率(Yuan等人,2018)、彩色化(Zhang,Isola和Efros,2016)、去雾(Dong等人,2020)和图像恢复(Liang等人,2021)等。
In an unpaired setting, lacking sufficient content constraints for the I2I task, using an adversarial loss (Goodfellow et al. 2014) alone is often prone to model collapse. To ensure content constraints, current generative adversarial networks (GAN)-based approaches can be broadly classified into two categories. One is reconstruction-based solutions. Typical approaches are CycleGAN (Zhu et al. 2017) and UNIT (Liu, Breuel, and Kautz 2017). They propose the cycle consistency or shared-latent space assumption, which requires that the transformed image, or the transforming image, should be able to map back to the original image perfectly. However, these assumptions are sometimes too strict (Park et al. 2020). For instance, the city street view is converted into a certain pixel-level annotated label, but reconverting a label to a city street view has yet countless possibilities. Such ill-posed setting limits the performance of reconstruction-based GANs, leading to unsatisfactory generations (Chen et al. 2020a).
在未配对的环境中,缺乏足够的I2I任务内容约束,单独使用对抗性损失(Goodfellow et al. 2014)往往容易导致模型崩溃。为了确保内容约束,当前基于生成对抗网络(GAN)的方法可以大致分为两类。一种是基于重建的解决方案。典型的方法是CycleGAN(Zhu et al. 2017)和UNIT(Liu,Breuel和考茨2017)。他们提出了循环一致性或共享潜在空间假设,这要求变换后的图像或变换图像应该能够完美地映射回原始图像。然而,这些假设有时过于严格(Park et al. 2020)。例如,城市街道视图被转换为某个像素级注释标签,但将标签重新转换为城市街道视图还有无数可能性。 这种不适定的设置限制了基于重建的GAN的性能,导致不令人满意的生成(Chen et al. 2020a)。
Another solution for content constraints is Siamese networks (Bromley et al. 1993). Siamese networks are weight sharing neural networks that accept two or more inputs. They are natural tools for comparing entity differences. For the I2I task, the input image and the generated image are fed to some Siamese networks separately, and the content consistency is ensured by matching the output features. CUT (Park et al. 2020) re-exploit the encoder of the generator as a feature extractor and propose the PatchNCE loss to maximize the mutual information between the patches of the input and generated images and achieve superior performance over the reconstruction-based methods. Some studies (Mechrez, Talmi, and Zelnik-Manor 2018; Zheng, Cham, and Cai 2021) repurpose the pre-trained VGG network (Simonyan and Zisserman 2015) as a feature extractor to constrain the feature correlation between the source and generated images. Given the strength and flexibility of Siamese networks, such content-constrained methods are increasingly widely used. However, Siamese network-based GANs mean that the source and generated images need to be fed into the Siamese networks again separately, which entails additional computational costs for training. In addition, an ideal Siamese network that can measure the differences in images well, is not always available.
另一种解决内容约束的方法是连体网络(Bromley et al. 1993)。Siamese网络是一种权重共享神经网络,它接受两个或多个输入。它们是比较实体差异的自然工具。对于I2I任务,将输入图像和生成图像分别馈送到一些Siamese网络,并通过匹配输出特征来确保内容一致性。CUT(Park et al. 2020)重新利用生成器的编码器作为特征提取器,并提出PatchNCE损失,以最大化输入图像和生成图像的补丁之间的互信息,并实现优于基于重建的方法的上级性能。一些研究(Mechrez,Talmi和Zelnik—Manor 2018;Zheng,Cham和Cai 2021)将预训练的VGG网络(Simonyan和Zisserman 2015)重新用作特征提取器,以约束源图像和生成图像之间的特征相关性。 由于连体网络的强度和灵活性,这种内容约束方法越来越广泛地使用。然而,基于暹罗网络的GAN意味着源图像和生成的图像需要再次单独输入暹罗网络,这需要额外的训练计算成本。此外,一个理想的暹罗网络,可以衡量图像的差异,并不总是可用的。
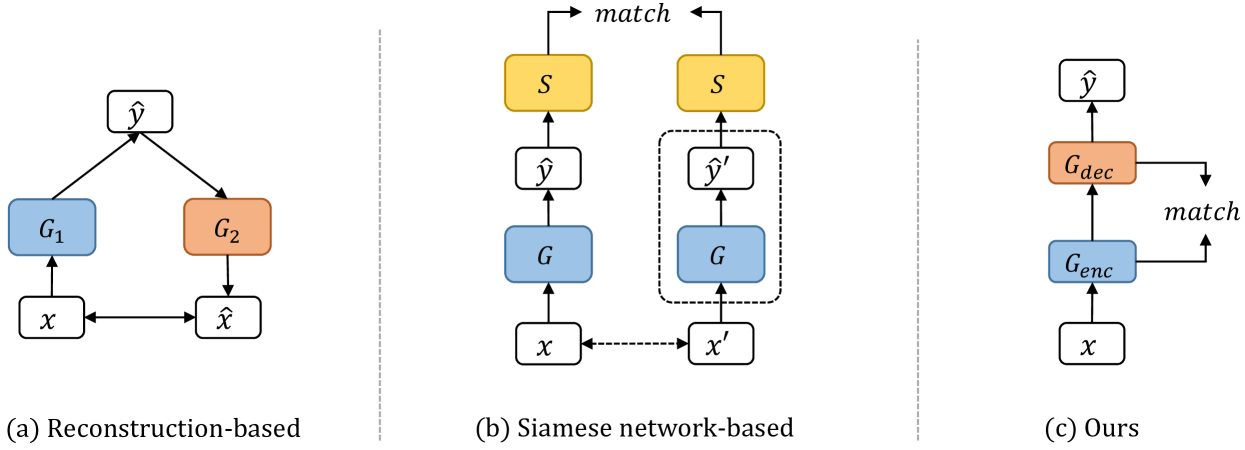
Figure 1:A comparison of different content constraints frameworks. (a) Reconstruction-based methods require that 𝑥↔𝐺2(𝐺1(𝑥)), a ℓ1 loss or ℓ2 loss is always used. Typical methods are CycleGAN (Zhu et al. 2017), UNIT (Zhu et al. 2017), etc. (b) Siamese network-based methods like CUT (Park et al. 2020) or LSeSim (Zheng, Cham, and Cai 2021) complete the content constraint through a defined feature extractor 𝑆, i.e., match(𝑆(𝐺(𝑥),𝑥′)) or match(𝑆(𝐺(𝑥),𝑆(𝐺(𝑥′))), where 𝑥′ is the augmented 𝑥. Note that the augmentation of 𝑥 is optional (dashed box). (c) EnCo completes the content constraint by agreeing on the representational similarity of features from the encoder and decoder of the generator.
图1:不同内容约束框架的比较。(a)基于重建的方法要求始终使用 𝑥↔𝐺2(𝐺1(𝑥)) 、 ℓ1 损失或 ℓ2 损失。典型的方法是CycleGAN(Zhu等人,2017),UNIT(Zhu等人,2017)等(B)基于Siamese网络的方法,如CUT(Park等人,2020)或LSeSim(Zheng,Cham和Cai 2021)通过定义的特征提取器 𝑆 完成内容约束,即, match(𝑆(𝐺(𝑥),𝑥′)) 或 match(𝑆(𝐺(𝑥),𝑆(𝐺(𝑥′))) ,其中 𝑥′ 是增强的 𝑥 。请注意, 𝑥 的增强是可选的(虚线框)。(c)EnCo通过同意来自生成器的编码器和解码器的特征的表示相似性来完成内容约束。
Can we explicitly constrain the content inside the generator network? Inspired by U-Net (Ronneberger, Fischer, and Brox 2015), a popular modern network architecture design that integrates features from different stages of the encoder and the decoder by skip connections, we make the encoding-decoding symmetry assumption for the I2I tasks. We assume that the semantic levels of encoder and decoder features from the same stage are the same (note that the number of encoder and decoder stages are opposite).
我们可以显式地约束生成器网络内部的内容吗?受U—Net(Ronneberger,Fischer和Brox 2015)的启发,U—Net是一种流行的现代网络架构设计,通过跳过连接集成了编码器和解码器的不同阶段的功能,我们为I2I任务做出了编码—解码对称性假设。我们假设来自同一阶段的编码器和解码器特征的语义级别是相同的(注意,编码器和解码器阶段的数量是相反的)。
Based on the assumption, we present EnCo, a simple but efficient way to constrain the content by agreeing on the representational similarity in the latent space of features from the same stage of the Encoder and deCoder of the generator. Specifically, we map the multi-stage intermediate features of the network to the latent space through a projection head, in which we aim to bring closer the representation of the same-stage features from the encoder and decoder, respectively. To prevent the networks from falling into a collapse solution, where the projection learns to output constants to minimize the similarity loss, we stop the gradient of the feature branch from the encoder, as well as add a prediction head for the decoder branch. It is worth mentioning that we find that negative samples are not necessary for the EnCo framework for the content constraint. As a result, we use a simple mean squared error loss instead of the contrastive loss that is widely used in current I2I tasks. This eludes the problems associated with negative sample selection (Hu et al. 2022).
基于这一假设,我们提出了EnCo,一种简单但有效的方式来约束内容,通过同意在潜在空间中的特征的表示相似性,从同一阶段的编码器和解码器的生成器。具体来说,我们通过投影头将网络的多级中间特征映射到潜在空间,我们的目标是分别使编码器和解码器的同级特征的表示更接近。为了防止网络陷入崩溃解决方案,其中投影学习输出常数以最小化相似性损失,我们停止编码器的特征分支的梯度,并为解码器分支添加预测头。值得一提的是,我们发现,负样本是不必要的EnCo框架的内容约束。因此,我们使用简单的均方误差损失,而不是当前I2I任务中广泛使用的对比损失。 这避免了与阴性样本选择相关的问题(Hu等人,2022)。
Benefits from the design, the training of EnCo is efficient and lightweight, as the content constraint is accomplished inside the generative network and no reconstruction or Siamese networks are required. To train more efficiently, similar to CUT, we sample patches from the intermediate features of the generative network, and perform patch-level features matching instead of the entire feature map-level. An ensuing question is from which locations we sample the patches. A simple approach is random sampling, which has been adopted by many methods (Park et al. 2020; Han et al. 2021; Zheng, Cham, and Cai 2021). However, this may not be the most efficient (Hu et al. 2022). We note that the discriminator provides key information for the truthfulness of the generated images. However, most of the current GAN-based approaches ignore the potential role of the discriminator in sampling patches (if involved). To this end, we propose a parameter-free discriminative attention-guided patch sampling strategy (DAG). DAG takes advantage of the discriminative information provided by the discriminator and attentively selects more informative patches for optimization. Experimentally, we show that our proposed patch sampling strategy can accelerate the convergence of model training and improve the model generation performance with almost negligible computational effort.
得益于这种设计,EnCo的训练是高效和轻量级的,因为内容约束是在生成网络内部完成的,不需要重建或连体网络。为了更有效地训练,类似于CUT,我们从生成网络的中间特征中采样补丁,并执行补丁级特征匹配,而不是整个特征映射级。随之而来的问题是我们从哪些位置采样补丁。一种简单的方法是随机抽样,已被许多方法采用(Park等人,2020; Han等人,2021; Zheng,Cham和Cai,2021)。然而,这可能不是最有效的(Hu等人,2022)。我们注意到,所生成的图像的真实性,提供了关键信息。然而,目前大多数基于GAN的方法忽略了采样补丁中的潜在作用(如果涉及)。 为此,我们提出了一个无参数的歧视性注意引导补丁采样策略(DAG)。DAG充分利用了神经网络提供的判别信息,并仔细选择信息量更大的补丁进行优化。实验表明,我们提出的补丁采样策略可以加速模型训练的收敛,提高模型生成性能,几乎可以忽略不计的计算工作量。
- •
We propose EnCo, a simple yet efficient way for content constrains by agreeing on the representational similarity of features from the same stage of the encoder and decoder of the generator in the latent space.
·我们提出了EnCo,这是一种简单而有效的内容约束方法,通过同意潜在空间中来自生成器的编码器和解码器的同一阶段的特征的表示相似性。 - •
We rethink the potential role of discriminators in patch sampling and propose a parameter-free DAG sampling strategy. DAG improves the generative performance significantly while only requiring an almost negligible computational cost.
·我们重新思考了判别器在斑块采样中的潜在作用,并提出了一种无参数的DAG采样策略。DAG显著提高了生成性能,同时只需要几乎可以忽略不计的计算成本。 - •
Extensive experiments on several popular I2I benchmarks reveal the effectiveness and advantages of EnCo. We achieve several state-of-the-art compared to previous methods.
·在几个流行的I2I基准测试上进行的大量实验揭示了EnCo的有效性和优势。与以前的方法相比,我们实现了几个国家的最先进的。
Related Works 相关作品
Image-to-Image Translation Image-to-image translation (Isola et al. 2017; Wang et al. 2018; Zhu et al. 2017; Park et al. 2020; Wang et al. 2021) aims to transform images from the source domain to the target domain with the semantic content preserved. Pix2Pix (Isola et al. 2017) was the first framework to accomplish the I2I task using paired data with an adversarial loss (Goodfellow et al. 2014) and a reconstruction loss. However, paired data across domains are infeasible to be collected in most settings. Methods such as CycleGAN (Zhu et al. 2017), DiscoGAN (Kim et al. 2017) and DualGAN (Yi et al. 2017) extend the I2I task to an unsupervised setting based on cycle consistency assumption that the generated image should be able to be converted back to the original image again. In addition, UNIT (Liu, Breuel, and Kautz 2017) and MUNIT (Huang et al. 2018) propose to learn a shared-latent space in which the hidden variable, i.e., the encoded image, can be decoded as both the target image and the original image. These methods can be classified as reconstruction-based solutions, and they implicitly assume that the process of conversion should be able to reconvert to the original image. However, perfect reconstruction is unlikely to be possible in many cases, which can potentially limit the performance of the generative networks (Park et al. 2020). In addition, such methods usually require additional auxiliary generators and discriminators.
图像到图像翻译(Isola et al. 2017; Wang et al. 2018; Zhu et al. 2017; Park et al. 2020; Wang et al. 2021)旨在将图像从源域转换到目标域,并保留语义内容。Pix 2 Pix(Isola et al. 2017)是第一个使用具有对抗性损失(Goodfellow et al. 2014)和重建损失的配对数据完成I2 I任务的框架。然而,在大多数情况下,跨域的配对数据是不可行的。CycleGAN(Zhu et al. 2017)、DiscoGAN(Kim et al. 2017)和DualGAN(Yi et al. 2017)等方法将I2 I任务扩展到基于循环一致性假设的无监督设置,即生成的图像应该能够再次转换回原始图像。此外,UNIT(Liu,Breuel,and考茨2017)和MUNIT(Huang et al. 2018)提出学习一个共享潜在空间,其中隐藏变量,即编码图像可以被解码为目标图像和原始图像。这些方法可以归类为基于重建的解决方案,它们隐含地假设转换过程应该能够重新转换为原始图像。然而,在许多情况下,完美的重建是不可能的,这可能会限制生成网络的性能(Park et al. 2020)。此外,这种方法通常需要额外的辅助发生器和鉴别器。
Siamese Networks for Content Constraints Another solution for content constraints can be attributed to Siamese network-based approaches, and they can effectively address the challenges posed by reconstruction-based ones. Siamese networks usually consist of networks with shared weights that accept two or more inputs, extract features, and compare differences. The selection of Siamese networks for content constraints can be different. For instance, the Siamese network of DistanceGAN and GcGAN is their generator. They require that the distances between the input images and the distances between the output images after generation should be consistent. CUT reuses the encoder of the generator as the Siamese network and proposes PatchNCE loss, aiming to maximize the mutual information between the patches of the input and output images. DCL (Han et al. 2021) extends CUT to a dual-way settings that exploiting two independent encoders and projectors for input and generated images respectively, but doubles the number of network parameters. Some recent studies have also attempted to re-purposed the pre-trained VGGNet (Simonyan and Zisserman 2015) as a perceptual loss to require that the input and output images should be visually consistent (Zheng, Cham, and Cai 2021). There may be a priori limitations in these methods, such as the frozen network weights of the loss function cannot adapt to the data and thus may not be the most appropriate (Zheng, Cham, and Cai 2021). Our work is quite different from the current approaches, as shown in Figure 1, where we impose constraints inside the generative network, i.e., between the encoder and decoder, without requiring additional networks for reconstruction or feature extraction. Therefore, EnCo has a higher training efficiency.
内容约束的暹罗网络内容约束的另一种解决方案可以归因于基于暹罗网络的方法,它们可以有效地解决基于重建的方法所带来的挑战。暹罗网络通常由具有共享权重的网络组成,这些网络接受两个或更多个输入,提取特征并比较差异。用于内容约束的连体网络的选择可以不同。例如,DistanceGAN和GcGAN的Siamese网络是它们的生成器。它们要求输入图像之间的距离和生成后的输出图像之间的距离应该一致。CUT重用生成器的编码器作为Siamese网络,并提出PatchNCE损失,旨在最大化输入和输出图像的补丁之间的互信息。DCL(Han et al. 2021)将CUT扩展到双向设置,利用两个独立的编码器和投影仪分别用于输入和生成图像,但网络参数的数量增加了一倍。最近的一些研究也试图重新利用预先训练的VGGNet(Simonyan和Zisserman 2015)作为感知损失,要求输入和输出图像在视觉上保持一致(Zheng,Cham和Cai 2021)。这些方法可能存在先验限制,例如损失函数的冻结网络权重无法适应数据,因此可能不是最合适的(Zheng,Cham和Cai 2021)。我们的工作与当前的方法完全不同,如图1所示,我们在生成网络内部施加约束,即,在编码器和解码器之间,而不需要用于重构或特征提取的附加网络。因此,EnCo具有更高的培训效率。
Contrastive Learning Recently, contrastive learning (CL) has achieved impressive results in the field of unsupervised representation learning (Hjelm et al. 2018; Chen et al. 2020b; He et al. 2020; Henaff 2020; Oord, Li, and Vinyals 2018). Based on the idea of discriminative, CL aims to bring closer the representation of two correlated signals (known as positive pair) in the embedding space while pushing away the representation of uncorrelated signals (known as negative pair). CUT first introduced contrastive learning to the I2I task and has been continuously improved since then (Han et al. 2021; Hu et al. 2022; Zhan et al. 2022). QS-Attn (Hu et al. 2022) improved the negative sampling strategy of CUT, by computing the 𝑄𝐾𝑉 matrix to dynamically selects relevant anchor points as positive and negatives. MoNCE (Zhan et al. 2022) proposed modulated noise contrastive estimation loss to re-weight the pushing force of negatives adaptively according to their similarity to the anchor. However, the performance of CL-based GANs approaches is still affected by the negative sample selection and poor negative may lead to slow convergence and even counter-optimization (Robinson et al. 2020). Therefore, some studies have raised the question whether using of the negative is necessary. BYOL (Grill et al. 2020) successfully trained a discriminative network using only positive pairs with a moment encoder. SimSiam (Chen and He 2020) pointed out that the stopping gradient is an important component for successful training without negatives, thus removing the moment encoder. EnCo is trained without negatives and only considerate the same stage features from the encoder and decoder of the generator as a positive pair, ensuring content consistency.
最近,对比学习(CL)在无监督表示学习领域取得了令人印象深刻的成果(Hjelm et al. 2018;Chen et al. 2020 b;He et al. 2020;Henaff 2020;Oord,Li和Vinyals 2018)。基于判别的思想,CL旨在使嵌入空间中两个相关信号(称为正对)的表示更接近,同时推开不相关信号(称为负对)的表示。CUT首先将对比学习引入I2I任务,此后一直在不断改进(Han et al. 2021;Hu et al. 2022;Zhan et al. 2022)。QS—Attn(Hu et al. 2022)通过计算 𝑄𝐾𝑉 矩阵来动态选择相关锚点作为阳性和阴性,从而改进了CUT的阴性采样策略。MoNCE(Zhan等人,2022)提出了调制噪声对比估计损失,以根据其与锚的相似性自适应地重新加权底片的推力。 然而,基于CL的GANs方法的性能仍然受到负样本选择的影响,并且不良的负可能导致收敛缓慢甚至反优化(罗宾逊等人2020)。因此,一些研究提出了是否有必要使用否定的问题。BYOL(Grill et al. 2020)成功地训练了一个仅使用正对和矩编码器的判别网络。SimSiam(Chen and He 2020)指出,停止梯度是成功训练而没有负数的重要组成部分,因此删除了矩编码器。EnCo在没有否定的情况下进行训练,并且只考虑来自生成器的编码器和解码器的相同阶段特征作为肯定对,以确保内容一致性。
Methods 方法
Main Idea 主要思想
Given an image from the source domain 𝑥∈𝒳, our goal is to learn a mapping function (also called a generator) 𝐺𝒳→𝒴 that converts the image from the source domain to the target domain 𝒴, i.e., 𝑦^=𝐺𝒳→𝒴(𝑥), and with as much content semantic information preserved as possible.
给定来自源域 𝑥∈𝒳 的图像,我们的目标是学习将图像从源域转换到目标域 𝒴 的映射函数(也称为生成器) 𝐺𝒳→𝒴 ,即, 𝑦^=𝐺𝒳→𝒴(𝑥) ,并尽可能多地保留内容语义信息。
Traditional content constraint methods based on Siamese networks, such as CUT, intend to constrain the content consistency of an image after generation with the source image. EnCo aims to constrain the content consistency of features generated in the intermediate process from the source image to the target image. Our approach is more efficient to train and achieves better performance. The overall architecture is shown in Figure 2 and contains the generator 𝐺, the discriminator 𝐷, the projection head ℎ, and the prediction head 𝑔. We decompose the generator into two parts, the encoder and the decoder, each of which consists of 𝐿-stage sub-networks. For any input source domain image 𝑥, after passing through 𝐿-stage sub-networks of the encoder, a sequence of features of different semantic levels are produced, i.e., {ℎ𝑙}1𝐿={𝐺𝑒𝑛𝑐𝑙(ℎ𝑙−1)}1𝐿. where 𝑥=ℎ0. Then feeding the output of the last stage of the encoder, i.e., ℎ𝐿, into the decoder, we can also obtain a sequence of features of different semantic levels in the decoder {ℎ𝑙}𝐿+12𝐿={𝐺𝑑𝑒𝑐𝑙(ℎ𝑙−1)}𝐿+12𝐿, where 𝑦^=ℎ2𝐿. For the I2I task, we make the encoding-decoding symmetry assumption that the semantic levels of the encoder and decoder features 𝑓𝑙 and 𝑓2𝐿−𝑙 from the same stage are the same (note that the number of stages of the encoder and decoder is opposite). For brevity, we abbreviate 2𝐿−𝑙 as 𝑙~ and denote (𝑓𝑙,𝑓𝑙~) as a pair of same-stage features in the following.
传统的基于Siamese网络的内容约束方法,如CUT,旨在约束生成后的图像与源图像的内容一致性。EnCo旨在约束从源图像到目标图像的中间过程中生成的特征的内容一致性。我们的方法更有效地训练,并实现更好的性能。整个架构如图2所示,包含生成器 𝐺 、预测头 𝐷 、投影头 ℎ 和预测头 𝑔 。我们将生成器分解为两部分,编码器和解码器,每个部分由 𝐿 级子网络组成。对于任何输入源域图像 𝑥 ,在通过编码器的 𝐿 级子网络之后,产生不同语义级别的特征序列,即,七号。 𝑥=ℎ0 的地方。然后将编码器的最后一级的输出,即, ℎ𝐿 ,输入到解码器中,我们还可以在解码器 {ℎ𝑙}𝐿+12𝐿={𝐺𝑑𝑒𝑐𝑙(ℎ𝑙−1)}𝐿+12𝐿 中获得不同语义级别的特征序列,其中 𝑦^=ℎ2𝐿 。对于I2 I任务,我们进行编码-解码对称性假设,即来自同一阶段的编码器和解码器特征 𝑓𝑙 和 𝑓2𝐿−𝑙 的语义级别相同(注意,编码器和解码器的阶段数量相反)。为了简洁起见,我们将 2𝐿−𝑙 表示为 𝑙~ ,并将 (𝑓𝑙,𝑓𝑙~) 表示为下面的一对相同阶段的特征。
Figure 2:(a) The overview of EnCo framework. EnCo constrain the content by agreeing on the representational similarity in the latent space of features from the same stage of the encoder and decoder of the generator. (b) The architecture of the projection. (c) The architecture of the prediction.
图2:(a)EnCo框架概述。EnCo通过同意来自生成器的编码器和解码器的相同阶段的特征的潜在空间中的表示相似性来约束内容。(b)投影的架构。(c)预测的架构。
We consider that the content of the transformed image can be preserved by constraining (𝑓𝑙,𝑓𝑙~). However, this direct approach may degrade the optimization of the generative network. With this view, we propose to guarantee the content constraint by constraining the representational similarity of the encoder and decoder features of the generator in the latent space.
我们认为可以通过约束 (𝑓𝑙,𝑓𝑙~) 来保留变换图像的内容。然而,这种直接方法可能会降低生成网络的优化。有了这个观点,我们建议通过约束潜在空间中生成器的编码器和解码器特征的表示相似性来保证内容约束。
As shown in Figure 2, for any pair of same-stage features (𝑓𝑙,𝑓𝑙~), we map them to the 𝐾-dimensional latent space by a shared two-layer projection head ℎ(⋅) to obtain 𝑧𝑙≜ℎ(𝑓𝑙) and 𝑧𝑙~≜ℎ(𝑓𝑙~). Inspired by (Grill et al. 2020), we further add a prediction head 𝑔(⋅) to 𝑧𝑙~ to enhance the non-linear expression of 𝑧𝑙~, and obtain 𝑝𝑙~≜𝑔(𝑧𝑙~).
如图2所示,对于任何一对同级特征 (𝑓𝑙,𝑓𝑙~) ,我们通过共享的双层投影头 ℎ(⋅) 将它们映射到 𝐾 维潜在空间,以获得 𝑧𝑙≜ℎ(𝑓𝑙) 和 𝑧𝑙~≜ℎ(𝑓𝑙~) 。受(Grill et al. 2020)的启发,我们进一步在 𝑧𝑙~ 中添加预测头 𝑔(⋅) ,以增强 𝑧𝑙~ 的非线性表达,并获得 𝑝𝑙~≜𝑔(𝑧𝑙~) 。
To avoid collapsing or expanding, we ℓ2-normalize both 𝑧𝑙 and 𝑝𝑙~ and map them to the unit sphere space to obtain 𝑧𝑙¯≜𝑧𝑙/‖𝑧𝑙‖2 and 𝑝¯𝑙~≜𝑝𝑙~/‖𝑝𝑙~‖2. Finally, we define the following mean-squared error loss aiming to constrain the representational similarity of a pair of same-stage normalized hidden variables from the encoder and decoder,
为了避免折叠或膨胀,我们对 𝑧𝑙 和 𝑝𝑙~ 进行 ℓ2 -归一化,并将它们映射到单位球面空间,以获得 𝑧𝑙¯≜𝑧𝑙/‖𝑧𝑙‖2 和 𝑝¯𝑙~≜𝑝𝑙~/‖𝑝𝑙~‖2 。最后,我们定义了以下均方误差损失,旨在约束来自编码器和解码器的一对同级归一化隐变量的表示相似性,
| ℒ(𝑧𝑙~,𝑧𝑙)=‖𝑝¯𝑙~−𝑧𝑙¯‖22=2−2⋅〈𝑔(𝑧𝑙~),𝑧𝑙〉‖𝑔(𝑧𝑙~)‖2⋅‖𝑧𝑙‖2. | (1) |
To prevent a collapse solution, i.e., the networks learn to output constants to minimize the loss. Following (Chen and He 2020), we solve this problem by introducing the key component of stopping gradient. We modify Eq. (1) as follows,
为了防止崩溃解决方案,即,网络学习输出常数以最小化损失。根据(Chen和He 2020),我们通过引入停止梯度的关键分量来解决这个问题。我们修改Eq. (1)如下所述,
| ℒ(𝑧𝑙~,𝚜𝚝𝚘𝚙𝚐𝚛𝚊𝚍(𝑧𝑙)). | (2) |
This means that during optimization, 𝑧𝑙 is constant and 𝑧𝑙~ is expected to be able to predict 𝑧𝑙 through the prediction head 𝑔(⋅). Therefore, 𝑧𝑙~ cannot vary too much from 𝑧𝑙, in such a way that the content constraint is achieved.
这意味着在优化期间, 𝑧𝑙 是恒定的,并且 𝑧𝑙~ 被期望能够通过预测头 𝑔(⋅) 预测 𝑧𝑙 。因此, 𝑧𝑙~ 不能以实现内容约束的方式与 𝑧𝑙 变化太多。
Multi-stage, Patch-based Content Constraints
多阶段、基于补丁的内容约束
Consider a more efficient training approach, given features pair (𝑓𝑙,𝑓𝑙~), we sample 𝑆 patches from different positions of 𝑓𝑙~, feed to the projection and prediction head, and obtain the set 𝐪𝐥~={𝑞𝑙~(1),⋯,𝑞𝑙~(𝑆)}, where the subscript indicates which stage to sample and the superscript denotes where to sample from the feature map. Similarly, we can sample from the same position, from 𝑓𝑙, and feed to the projection to get 𝐤𝐥={𝑘𝑙~(1),⋯,𝑘𝑙(𝑆)}. We implement content constraints on patch-level features, rather than the entire feature map-level. Therefore, we just need to use 𝐤𝐥,𝐪𝐥~ to replace 𝑧𝑙,𝑧𝑙~ in Eq. (2), respectively, and get
考虑一种更有效的训练方法,给定特征对 (𝑓𝑙,𝑓𝑙~) ,我们从 𝑓𝑙~ 的不同位置采样 𝑆 块,馈送到投影和预测头,并获得集合 𝐪𝐥~={𝑞𝑙~(1),⋯,𝑞𝑙~(𝑆)} ,其中下标表示要采样的阶段,上标表示从特征图的哪里采样。类似地,我们可以从相同的位置,从 𝑓𝑙 采样,并馈送到投影以获得 𝐤𝐥={𝑘𝑙~(1),⋯,𝑘𝑙(𝑆)} 。我们在补丁级别的功能上实现内容约束,而不是整个功能映射级别。因此,我们只需要使用 𝐤𝐥,𝐪𝐥~ 来替换等式中的 𝑧𝑙,𝑧𝑙~ 。(2),并得到
| ℒ(𝐪𝐥~,𝚜𝚝𝚘𝚙𝚐𝚛𝚊𝚍(𝐤𝐥)). | (3) |
We can further extend Eq. (3) to a multi-stage version, i.e.,
我们可以进一步扩展Eq。(3)到多级版本,即,
| ℒMultiStage(𝐺,ℎ,𝑔,𝐗)=𝔼𝑥∼𝐗∑𝑙𝕃∑𝑠𝕊𝑙ℒ(𝑞𝑙~(𝑠),𝚜𝚝𝚘𝚙𝚐𝚛𝚊𝚍(𝑘𝑙(𝑠))), | (4) |
where, 𝕃 is the set of chosen same-stage pairwise features to calculate the mean-squared error loss, and 𝕊𝑙 is the set of sampled positions of patches from (𝑓𝑙,𝑓𝑙¯).
其中, 𝕃 是用于计算均方误差损失的所选同级成对特征的集合,并且 𝕊𝑙 是来自 (𝑓𝑙,𝑓𝑙¯) 的贴片的采样位置的集合。
Discriminative Attention-guided Patch Sampling Strategy
区分性注意引导的块采样策略
We further propose an efficient discriminative attention-guided (DAG) patch sampling strategy to replace the current widely used random sampling strategy used in Eq. (4). The idea of DAG is simple. DAG mainly takes good advantage of the important information from the discriminator: the truthfulness of the generated images, and attentively selects more informative patches for optimization.
我们进一步提出了一个有效的判别注意力引导(DAG)补丁采样策略,以取代目前广泛使用的随机采样策略中使用的方程。(4). DAG的概念很简单。DAG主要利用了图像的重要信息:生成图像的真实性,并仔细选择更多的信息块进行优化。
Assuming that a total of 𝐾 patches would be sampled, for any pairwise features (𝑓𝑙,𝑓𝑙~), DAG proceeds as follows: 1) obtaining the attention scores: interpolating the output of the discriminator to the same resolution size as 𝑓𝑙 and 𝑓𝑙~, thus each position on 𝑓𝑙 receives a attention score; 2) oversampling: uniformly sampling 𝑘𝐾(𝑘>1) patches from 𝑓𝑙~, where 𝑘 is the oversampling ratio; 3) ranking: sorting all sampled patches in ascending order according to their corresponding attention scores; 4) importance sampling: selecting the top 𝛽𝐾(0≤𝛽≤1) patches with the highest scores, where 𝛽 is the importance sampling ratio; 5) Covering: uniformly sample the remaining (1−𝛽)𝐾 patches. Note that the DAG is parameter-free, while requiring only an almost negligible computational cost.
假设将对总共 𝐾 个块进行采样,对于任何成对特征 (𝑓𝑙,𝑓𝑙~) ,DAG如下进行:1)获得注意力分数:将QR的输出内插到与 𝑓𝑙 和 𝑓𝑙~ 相同的分辨率大小,因此 𝑓𝑙 上的每个位置接收注意力分数; 2)过采样:从 𝑓𝑙~ 中均匀地采样 𝑘𝐾(𝑘>1) 块,其中 𝑘 是过采样率; 3)排序:根据它们对应的注意力分数将所有采样块以升序排序; 4)重要性采样:选择具有最高分数的前 𝛽𝐾(0≤𝛽≤1) 块,其中 𝛽 是重要性采样率; 5)覆盖:对剩余的 (1−𝛽)𝐾 贴片进行均匀采样。请注意,DAG是无参数的,同时只需要几乎可以忽略不计的计算成本。
Figure 3:Results of qualitative comparison. We compare EnCo with existing methods on the Horse→Zebra, Cat→Dog, and Cityscapes datasets. EnCo achieves more satisfactory visual results. For example, in the case of Cat→Dog, EnCo generates a clearer nose for the dog. And in the case of Cityscapes, EnCo successfully generates the traffic cone represented in yellow in the semantic annotation, while the other methods yielded only suboptimal results.
图3:定性比较结果。我们将EnCo与现有方法在马 → 斑马,猫 → 狗和城市景观数据集上进行比较。EnCo获得了更令人满意的视觉效果。例如,在猫 → 狗的情况下,EnCo为狗生成更清晰的鼻子。在Cityscapes的情况下,EnCo成功地生成了语义注释中以黄色表示的交通锥,而其他方法只产生了次优的结果。
| Method | CityScapes | Cat→Dog 猫 → 狗 | Horse→Zebra 马 → 斑马 | |||||
|---|---|---|---|---|---|---|---|---|
| mAP↑ | pixAcc↑ | classAcc↑ | FID↓ FID编号0# | FID↓ FID编号0# | FID↓ FID编号0# | Mem(GB)↓ 内存(GB) ↓ | sec/iter↓ 秒/iter ↓ | |
| CycleGAN (Zhu et al. 2017) CycleGAN(Zhu等人,2017) | 20.4 | 55.9 | 25.4 | 68.6 | 85.9 | 66.8 | 4.81 | 0.40 |
| MUNIT (Huang et al. 2018) MUNIT(Huang等人,2018) | 16.9 | 56.5 | 22.5 | 91.4 | 104.4 | 133.8 | 3.84 | 0.39 |
| \cdashline1-9 GCGAN (Fu et al. 2019) \cdashline1-9 GCGAN(Fu等人,2019) | 21.2 | 63.2 | 26.6 | 105.2 | 96.6 | 86.7 | 2.67 | 0.62 |
| CUT (Park et al. 2020) CUT(Park等人,2020) | 24.7 | 68.8 | 30.7 | 56.4 | 76.2 | 45.5 | 3.33 | 0.24 |
| DCLGAN (Han et al. 2021) DCLGAN(Han等人,2021) | 22.9 | 77.0 | 29.6 | 49.4 | 60.7 | 43.2 | 7.45 | 0.41 |
| FSeSim (Zheng, Cham, and Cai 2021) FSeSim(Zheng,Cham和Cai 2021) | 22.1 | 69.4 | 27.8 | 54.3 | 87.8 | 43.4 | 2.92 | 0.17 |
| MoNCE (Zhan et al. 2022) MoNCE(Zhan等人,2022) | 25.6 | 78.4 | 33.0 | 54.7 | 74.2 | 41.9 | 4.03 | 0.28 |
| QS-Attn (Hu et al. 2022) QS-Attn(Hu等人,2022) | 25.5 | 79.9 | 31.2 | 53.5 | 72.8 | 41.1 | 2.98 | 0.35 |
| \cdashline1-9 EnCo (Ours) \cdashline1-9 EnCo(我们的) | 28.4 | 77.3 | 37.2 | 45.4 | 54.7 | 38.7 | 2.83 | 0.14 |
Table 1:Comparison with baselines on unpaired image translation. We compare our approach to the state-of-the-art methods on three datasets. We show multiple metrics, where the ↑ indicates higher is better and the ↓ indicates lower is better. It is worth noting that our method outperforms all baselines on the FID metric and shows superior results on the Cityscapes for the semantic segmentation metric. Also, our method shows a fast training speed.
表1:未配对图像平移与基线的比较。我们将我们的方法与三个数据集上的最先进方法进行比较。我们展示了多个指标,其中 ↑ 表示越高越好, ↓ 表示越低越好。值得注意的是,我们的方法在FID指标上优于所有基线,并在Cityscapes上显示出语义分割指标的上级结果。此外,我们的方法显示出快速的训练速度。
Full Objective 完整目标
In addition to the MultiStage loss presented above, we also use an adversarial loss to complete the domain transfer, and we add an identity mapping loss as a regularization term to stabilize the network training.
除了上面介绍的MultiStage损失,我们还使用对抗损失来完成域转移,并添加身份映射损失作为正则化项来稳定网络训练。
Generative adversarial loss We use LSGAN loss (Mao et al. 2017) as the adversarial loss to encourage the generated images that are as visually similar to images in the target domain as possible, which is formalized as follows,
生成性对抗损失我们使用LSGAN损失(Mao et al. 2017)作为对抗损失,以鼓励生成的图像尽可能与目标域中的图像在视觉上相似,形式化如下,
| ℒGAN=𝔼𝑦∼𝑌[𝐷(𝑦)2]+𝔼𝑥∼𝑋[(1−𝐷(𝐺(𝑥)))2]. | (5) |
Identity mapping loss In order to stable the training and accelerate the convergence, we add an identity mapping loss.
为了稳定训练和加速收敛,我们添加了一个恒等映射损失。
| ℒidentity(𝐺)=𝔼𝑦∼𝑌‖𝐺(𝑦)−𝑦‖1. | (6) |
We only use this regular term in the first half of the training phase because we find that it impacts the generative performance of the network to some extent.
我们只在训练阶段的前半部分使用这个正则项,因为我们发现它在一定程度上影响了网络的生成性能。
Overall loss Our final objective function is as follows:
总损失我们的最终目标函数如下:
| ℒtotal(𝐺,𝐷,ℎ,𝑔)=ℒGAN(𝐺,𝐷,𝑋,𝑌)+𝜆𝑁𝐶𝐸ℒMultiStage(𝐺,ℎ,𝑔,𝑋)+𝜆𝐼𝐷𝑇ℒidentity(𝐺,𝑌), | (7) |
where 𝜆𝑁𝐶𝐸 and 𝜆𝐼𝐷𝑇 are set to 2 and 10, respectively.
其中 𝜆𝑁𝐶𝐸 和 𝜆𝐼𝐷𝑇 分别设置为2和10。
Discussion 讨论
EnCo achieves content consistency by constraining the similarity between representations of the encoder and decoder features at multiple stages in the latent space. In fact, there are two additional perspectives on how EnCo achieves content consistency that we would like to offer. Firstly, in relation to reconstruction-based methods, EnCo requires decoding features that should be able to predict their corresponding encoded features in turn through the prediction MLP, which is somehow similar to the reconstruction-based approach. However, EnCo conducts the reconstruction at the feature level rather than the pixel level, which provides more freedom when enforcing content consistency. EnCo degenerates into a special CycleGAN approach when we only constrain the consistency of the input and generated images, with projection being an identity network and prediction network being another generator. Secondly, EnCo can also be regarded as an implicit and lightweight Siamese network paradigm (similar to CUT), where encoder and decoder features are constrained to have similar representations in the latent space through the shared projection MLP.
EnCo通过在潜在空间中的多个阶段约束编码器和解码器特征的表示之间的相似性来实现内容一致性。事实上,关于EnCo如何实现内容一致性,我们想提供两个额外的观点。首先,关于基于重构的方法,EnCo需要解码特征,这些解码特征应当能够通过预测MLP来依次预测其对应的编码特征,这在某种程度上类似于基于重构的方法。然而,EnCo在特征级而不是像素级进行重构,这在强制内容一致性时提供了更多的自由度。当我们只约束输入和生成图像的一致性时,EnCo退化为一种特殊的CycleGAN方法,投影是一个恒等网络,预测网络是另一个生成器。 其次,EnCo也可以被视为一种隐式和轻量级的连体网络范式(类似于CUT),其中编码器和解码器特征被约束为通过共享投影MLP在潜在空间中具有相似的表示。











![[Cesium for Supermap]加载iserver发布的wms服务](https://img-blog.csdnimg.cn/direct/e1ce7d7be7fe4a519e84a576dd3d36bf.png)

![[AI]-(第1期):OpenAI-API调用](https://img-blog.csdnimg.cn/direct/ac5b636ff9aa442890bd935cb754330a.jpeg#pic_center)
