目录
3.1.2 Seaborn绘图库
1. 带核密度估计的直方图
2. 二元分布图
一维正态分布
联合分布函数
二元边际分布函数
二维正态分布
3. 热力图
附录
参考
3.1.2 Seaborn绘图库
Seaborn和Matplotlib类似,也是Python数据可视化库。不过,它是基于Matplotlib的数据可视化库。比Matplotlib更强大。提供了用于绘制统计图形的高级界面。
在使用Seaborn绘图库前,我们需要安装Seaborn库。可以在Pycharm上直接安装。点击Pycharm底部的Terminal终端,执行如下命令安装Seaborn,
pip install seaborn如图: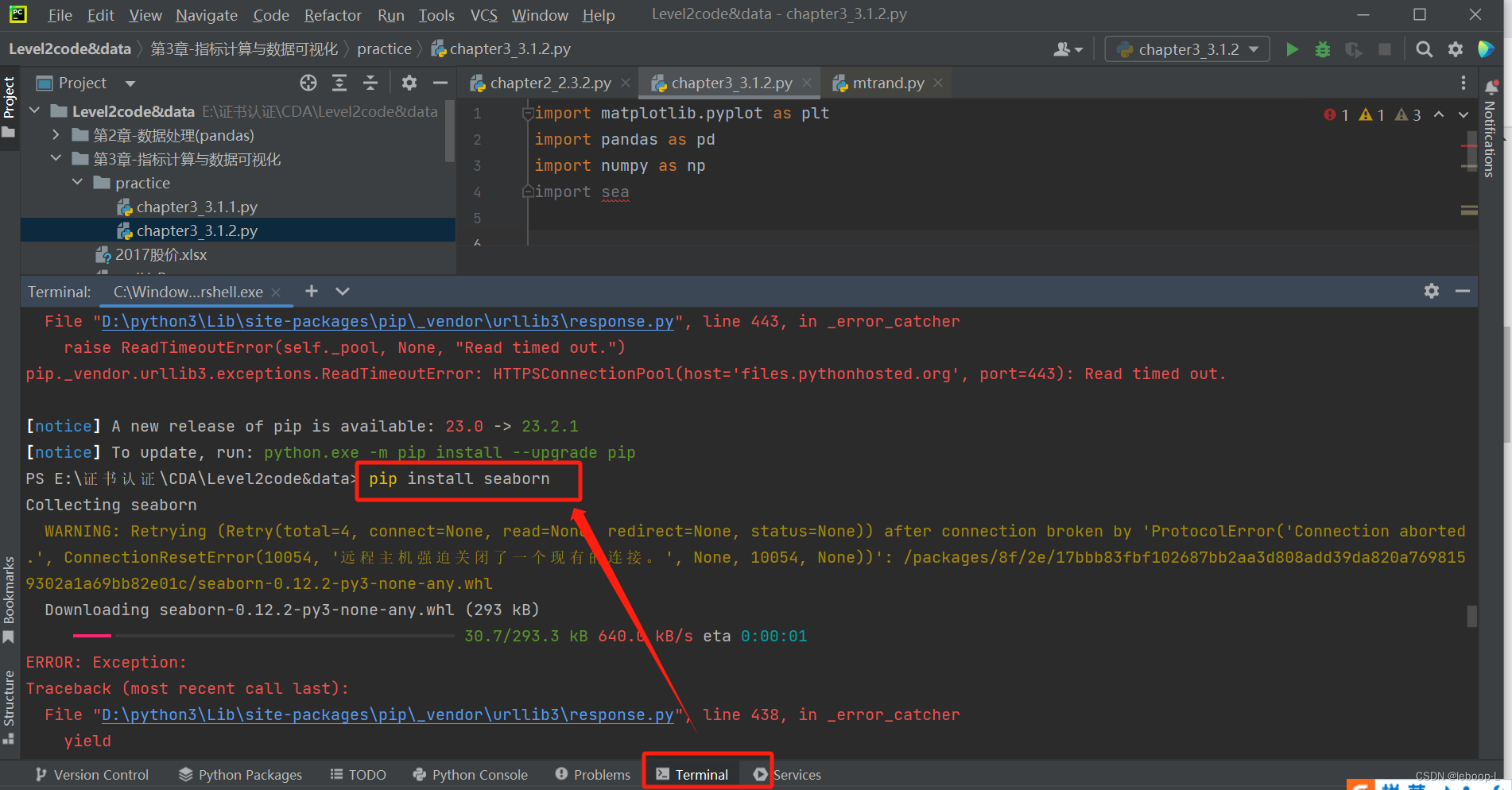
结果发现,经常因为网络原因导致安装超时。下面使用国内清华大学开源软件镜像站来安装,地址如下:
https://pypi.tuna.tsinghua.edu.cn/simple可以使用浏览器查看镜像站,如图:
下面使用镜像站来安装,执行如下命令:
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple安装成功后,如图:
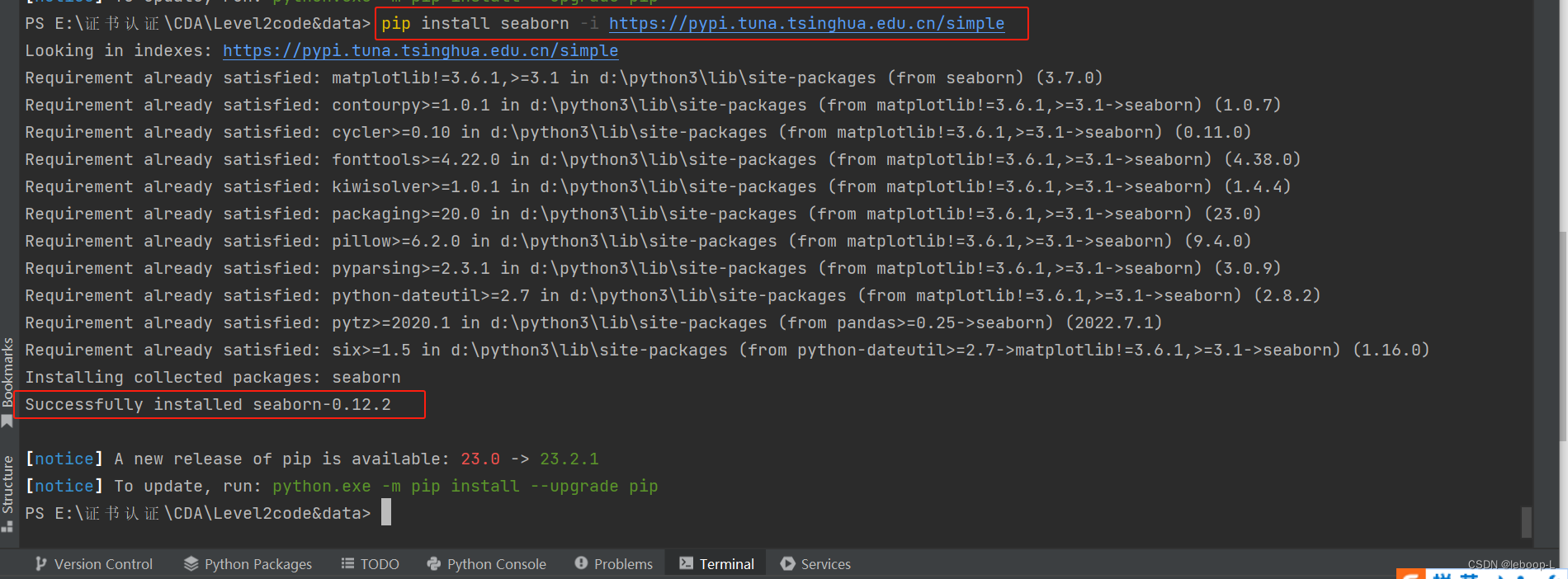
以后安装库的时候,就可以使用这种方式来安装了。
1. 带核密度估计的直方图
直方图通过分箱和计数可视化样例数据,直观展示近似的概率密度函数。Seaborn采用核密度估计概率密度函数。
核密度估计(kernel density estimation)是在概率论中用来估计未知的概率密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。
关于核密度估计将放在后续章节,给予证明以及应用。下面我们使用Seaborn的displot()方法绘制直方图,并绘制出估计的概率密度函数。代码:
import matplotlib.pyplot as plt
import numpy as np
import seaborn as snsif __name__ == '__main__':np.random.seed(1)data = np.random.normal(loc=80, scale=20, size=200)print('data=', '\n', data)data_int = data.astype(int)print('data_int=', '\n', data_int)x = np.arange(30, 140, 10) # 生成一个数组,开始是30,结束是140(不包括),步长10,sns.displot(data=data_int, bins=x, kde=True)plt.show()
bins表示分箱。
运行结果,如图:
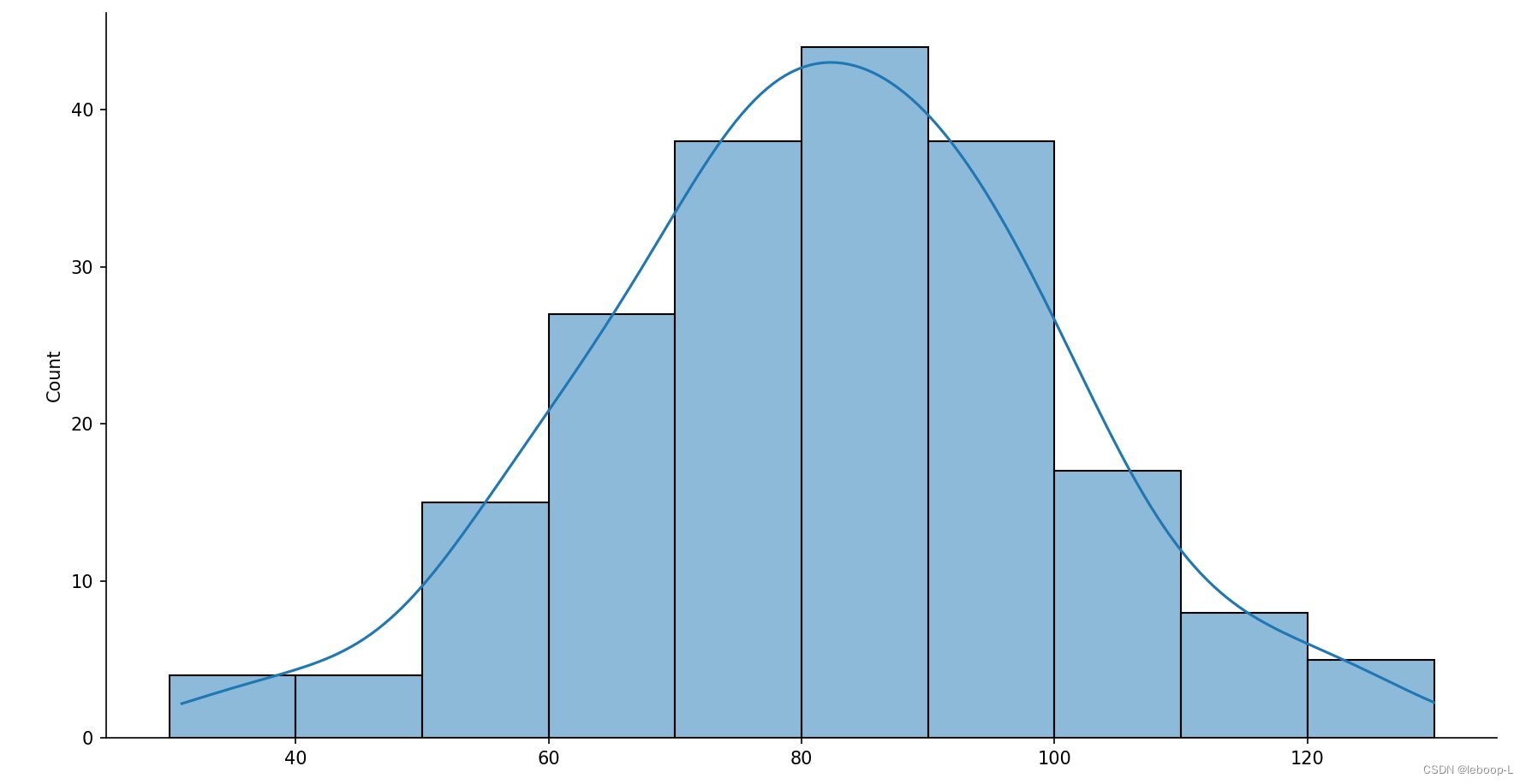
使用同样的样例数据,生成的直方图,如下:
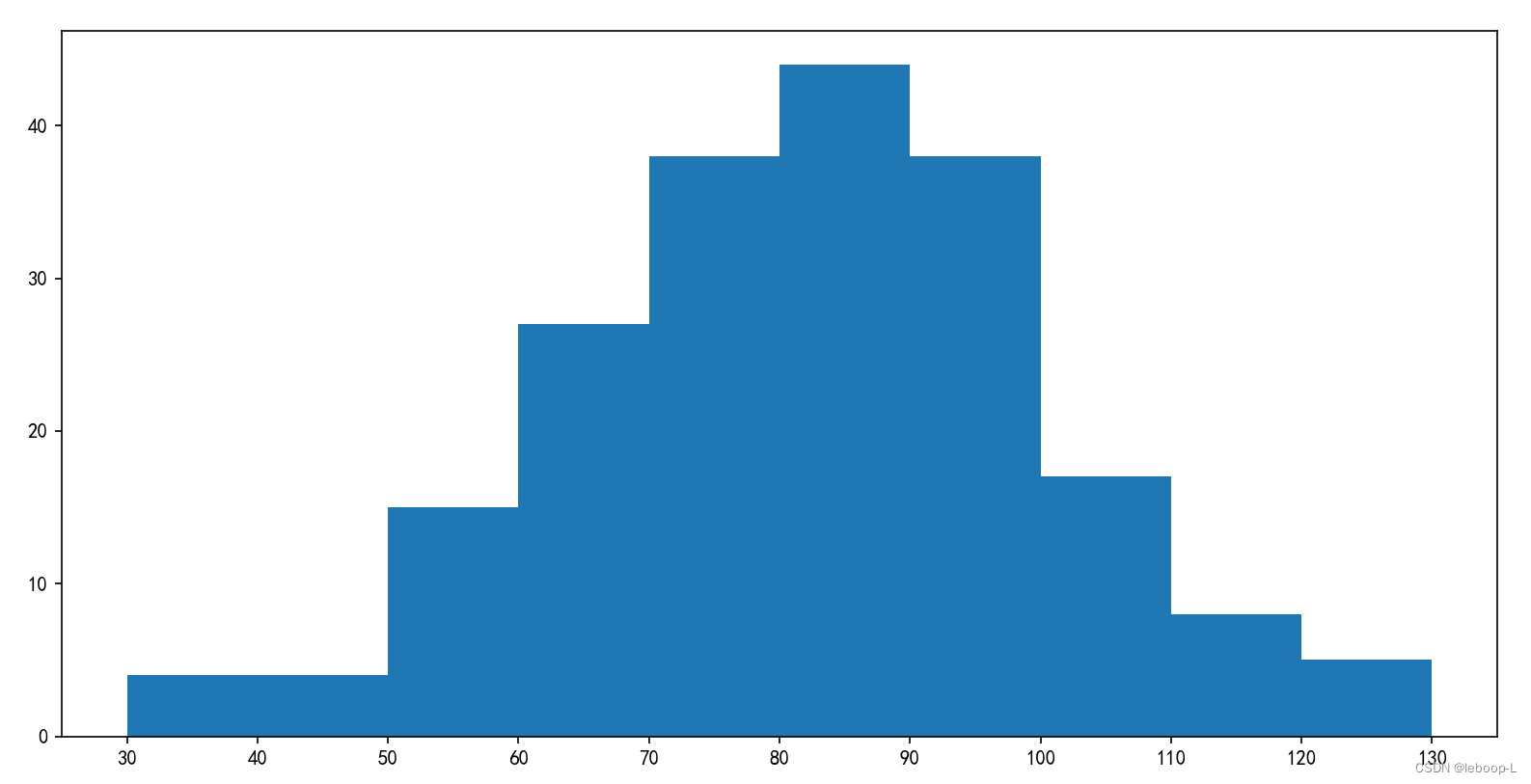
2. 二元分布图
在介绍二元分布图之前,我们先介绍概率统计中,随机变量的联合分布、边际分布的概念。然后以正态分布为例,从一维正态分布,再到二维正态分布,逐步介绍二元分布图的来龙去脉。
(1) 一维正态分布

一维正态分布的概率密度函数,含有一个随机变量x,均值为,方差
。
正态分布的概率密度函数图像示意图,如下:
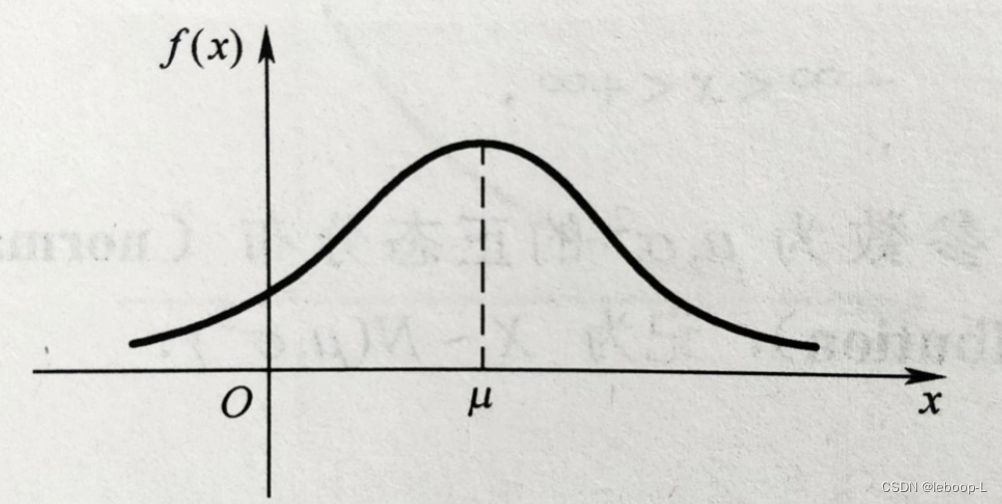 关于均值
关于均值对称。当均值和方差取如下值时,正态分布变为标准正态分布。

标准正态分布的概率分布函数图像,如图:
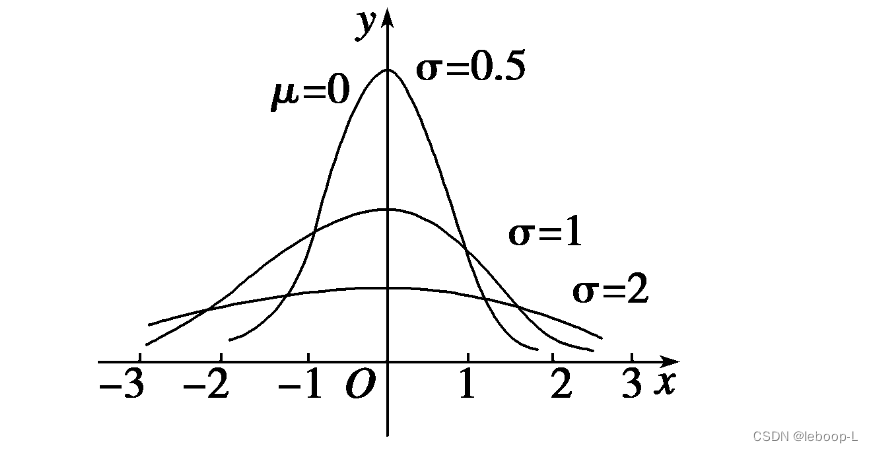
图中绘制了,不同正态分布的概率密度函数曲线。
(2)联合分布函数

当n=2,就是二元(维)联合分布函数。 后面仅讨论二元的情况。
注意:这里不是概率密度函数,而是分布函数。
(3)二元边际分布函数

可以看到,边际分布可以从联合分布得到。例如随机变量X的边际分布,其实就是随机变量X的概率分布。
(4)二维正态分布

注:f(x,y)是概率密度函数,不是概率分布。
下面我们将二维正态分布的概率密度函数转换成矩阵的形式:

为了更直观理解,下面绘制二维正态分布概率密度函数图像。首先需要安装scipy库。命令如下:
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple安装成功后,如图:
绘制代码如下:
import matplotlib.pyplot as plt
import numpy as np
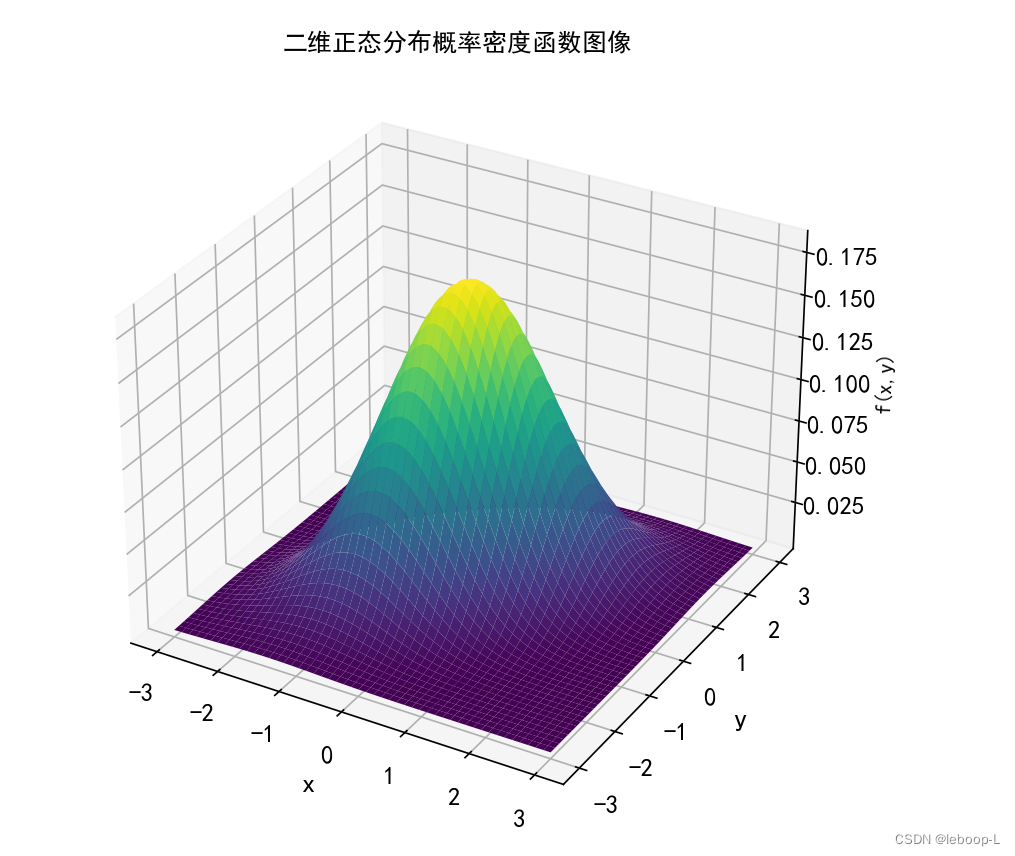
from scipy.stats import multivariate_normalif __name__ == '__main__':plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号# 定义均值和协方差矩阵mean = np.array([0, 0]) # 均值.covariance = np.array([[1, 0.5], [0.5, 1]]) # 协方差矩阵.# 创建一个网格,x和y都是从(-3,3)范围,500个点.x, y = np.meshgrid(np.linspace(-3, 3, 500), np.linspace(-3, 3, 500))pos = np.dstack((x, y))# 计算二维正态分布的概率密度值pdf_values = multivariate_normal.pdf(pos, mean=mean, cov=covariance)# 绘制三维概率密度图像fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')ax.tick_params(axis="both", labelsize=12)ax.plot_surface(x, y, pdf_values, cmap='viridis')ax.set_xlabel('x', fontsize=13)ax.set_ylabel('y', fontsize=13)ax.set_zlabel('f(x,y)')ax.set_title('二维正态分布概率密度函数图像')plt.show()
运行结果,如图:
有了以上的知识储备,下面绘制二元分布图就容易理解多了。下面生成二元分布图的样例数据,代码如下:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as snsif __name__ == '__main__':plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号 np.random.seed(0)mean, cov = [0, 1], [(1, 0.5), (0.5, 1)] # python可以一次给多个变量赋值,使用逗号隔开.data = np.random.multivariate_normal(mean=mean, cov=cov, size=200)df = pd.DataFrame(data=data, columns=['x', 'y'])print('df=', '\n', df)代码中,样例数据是使用
data = np.random.multivariate_normal(mean=mean, cov=cov, size=200)
二维正态分布生成的。总共生成200行2列数据,第一个列名x表示随机变量x,第二列列名表示随机变量y。
mean = [0,1],对应二维正态分布,。
cov = [(1, 0.5), (0.5, 1)],对应二维正态分布。
运行结果,如图:

可以如下绘制随机变量x和随机变量y的联合图,代码如下:
sns.jointplot(x='x', y='y', data=df)
plt.show()运行结果,如图:
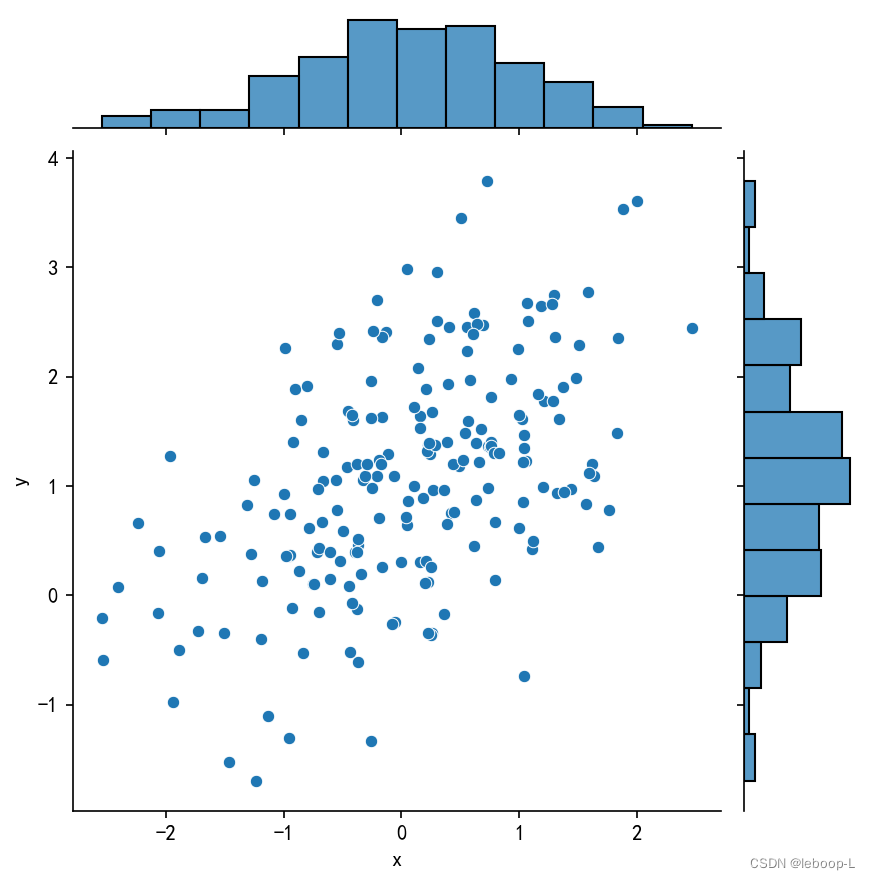
从图中可以看到,联合图有两部分组成:
(1)中间部分是一个散点图,描述了随机变量x和随机变量y之间的关系,
(2)散点图的顶部和右边是两个直方图,它们描述的是两个边际分布,顶部是二维正态分布的x的边际分布,右边是二维正态分布的y的边际分布。x的边际分布是一个的标准正态分布。y的边际分布是一个
的正态分布。
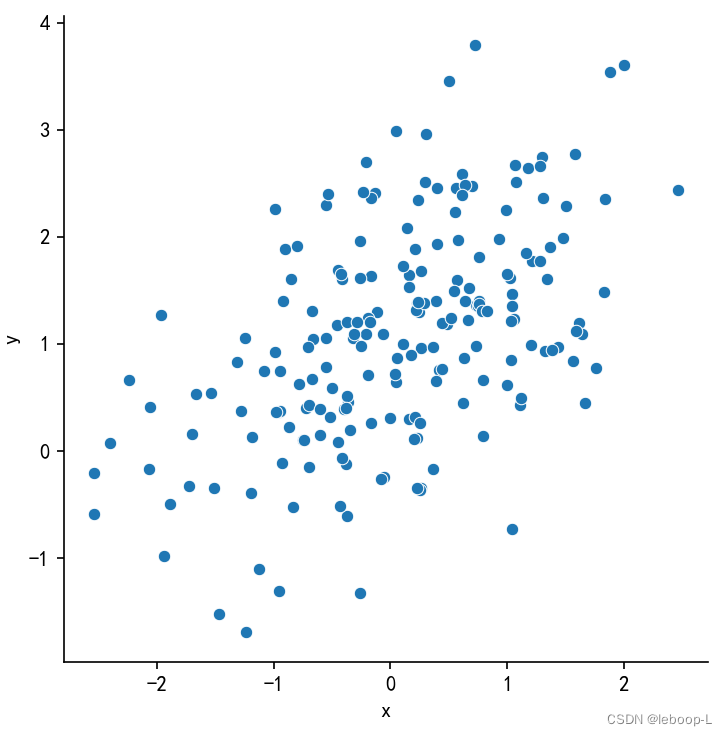
如果不需要绘制边际分布,可以如下处理:
sns.relplot(x='x', y='y', data=df)plt.show()运行结果,如图:
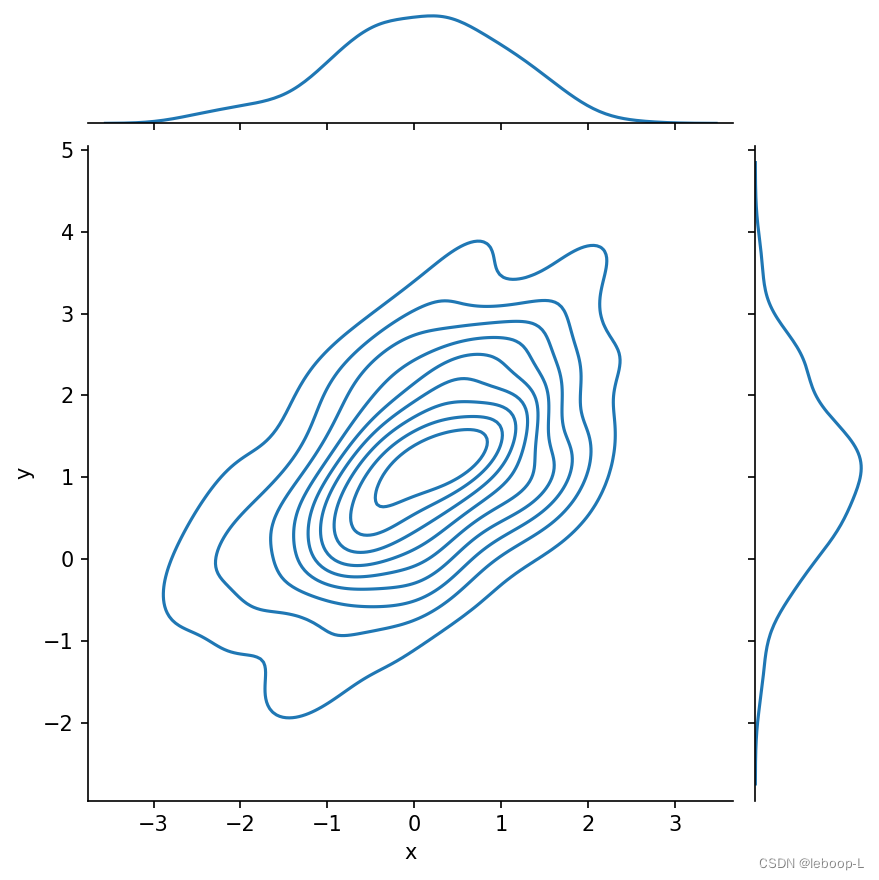
绘制带核密度估计的二元分布图,代码如下:
sns.jointplot(x='x', y='y', data=df, kind='kde')plt.show()运行结果如下:
3. 热力图
热力图用于可视化变量之间的关系强弱。可以是多个变量。生成样例数据,代码如下:
np.random.seed(0)data = np.random.uniform(low=-1, high=1, size=(7, 7))index = list('abcdefg')columns = list('ABCDEFG')df = pd.DataFrame(data=data, index=index, columns=columns)print('df=', '\n', df)运行结果:
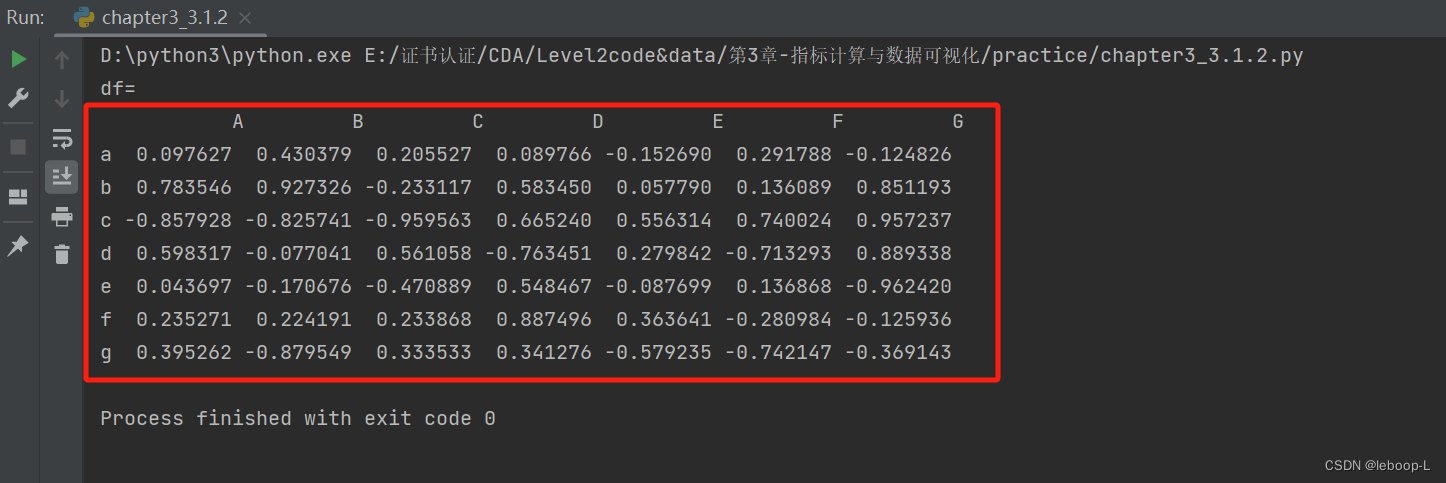
从运行结果来看, 总共生成7行7列数据,a~g表示7个行变量,A~G表示7个列变量。数值表示行变量和列变量的相关性大小,例如g和G两个变量对应的值-0.369143,表示两个变量呈现负相关性。
代码中使用了uniform()方法,它是均为分布,什么是均匀分布呢?
在概率论和统计学中,均匀分布也叫矩形分布(分布图形像矩形),它是对称概率分布,在相同长度间隔的分布概率是等可能的。均匀分布由两个参数a和b定义,它们是数轴上的最小值和最大值,通常缩写为U(a,b)。均匀分布的概率密度函数如下:
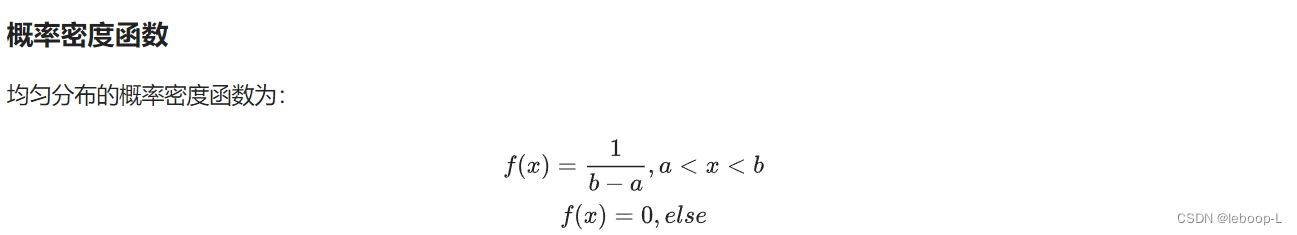
概率密度函数在(a,b)区间是一个常值1/(b-a),所以相同长度间隔t的分布概率都是t/(b-a),是可能的。
概率密度函数图像如下:
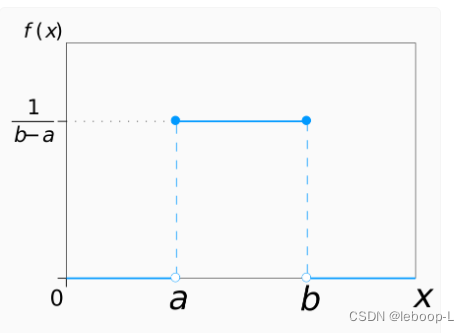
样例数据使用的是np.random.uniform(low=-1, high=1, size=(7, 7)),表示a=-1,b=1,size=(7,7)表示7行7列矩阵,总共49个数。整行代码的意思是:生成一个服从均为分布的7行7列的矩阵,每个数据的范围在(-1,1)之间,且生成每个数据的概率是一样的。这里为啥选用(-1,1)之间呢,这样每个数据可以表示行和列的相关性。例如g和G对应的值为-0.369143,表示g和G两个变量呈现负相关性。直接从上面的样例数据来看,无法直观的看出哪两个变量的相关性更强或更弱。所以,下面通过热力图可视化这些变量的相关性强弱。
plt.figure(figsize=(8, 6))sns.set(font_scale=1.5)# 解决title中文乱码问题,放在sns.set后面.plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号sns.heatmap(df)plt.xlabel('columns', fontsize=13)plt.ylabel('index', fontsize=13)plt.title('热力图')plt.show()plt.title('热力图')使用了中文作为热力图的标题,可能会出现中文显示乱码问题,需要在sns.set()方法设置字体解决中文乱码问题:
plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文注意的是这行代码放在plt.figure(figsize=(8, 6))之前,并不能解决中文乱码。
运行结果,如图:
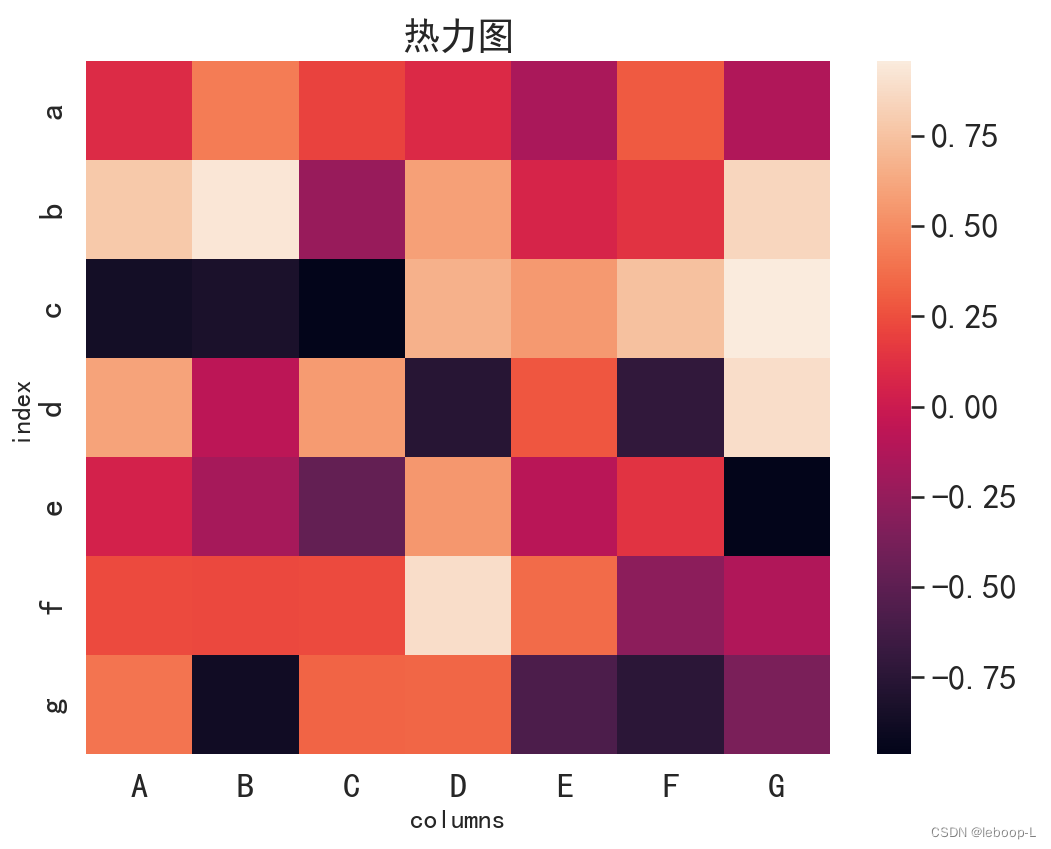
从热力图来看,热力图右边显示的相关性数值和颜色的对照关系,颜色越深相关性数值越小,颜色越浅,相关性数值越大。从图中,很直观的看到b和B,f和D,c和G变量之间的相关性很强。
附录
本节所有代码如下:
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
from scipy.stats import multivariate_normalif __name__ == '__main__':# 带核密度估计的直方图np.random.seed(1)data = np.random.normal(loc=80, scale=20, size=200)print('data=', '\n', data)data_int = data.astype(int)print('data_int=', '\n', data_int)x = np.arange(30, 140, 10) # 生成一个数组,开始是30,结束是140(不包括),步长10,sns.displot(data=data_int, bins=x, kde=True)plt.show()# 二维正态分布图像# 定义均值和协方差矩阵mean = np.array([0, 0])covariance = np.array([[1, 0.5], [0.5, 1]])# 创建一个网格x, y = np.meshgrid(np.linspace(-3, 3, 500), np.linspace(-3, 3, 500))pos = np.dstack((x, y))# 计算二维正态分布的概率密度值pdf_values = multivariate_normal.pdf(pos, mean=mean, cov=covariance)# 绘制概率密度图像plt.figure(figsize=(8, 8))plt.contourf(x, y, pdf_values, cmap='viridis')plt.colorbar()plt.xlabel('X')plt.ylabel('Y')plt.title('2D Gaussian Probability Density')plt.show()# 定义均值和协方差矩阵mean = np.array([0, 0]) # 均值.covariance = np.array([[1, 0.5], [0.5, 1]]) # 协方差矩阵.# 创建一个网格,x和y都是从(-3,3)范围,500个点.x, y = np.meshgrid(np.linspace(-3, 3, 500), np.linspace(-3, 3, 500))pos = np.dstack((x, y))# 计算二维正态分布的概率密度值pdf_values = multivariate_normal.pdf(pos, mean=mean, cov=covariance)# 绘制三维概率密度图像fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')ax.tick_params(axis="both", labelsize=12)ax.plot_surface(x, y, pdf_values, cmap='viridis')ax.set_xlabel('x', fontsize=13)ax.set_ylabel('y', fontsize=13)ax.set_zlabel('f(x,y)')ax.set_title('二维正态分布概率密度函数图像')plt.show()# 二元分布图np.random.seed(0)mean, cov = [0, 1], [(1, 0.5), (0.5, 1)] # python可以一次给多个变量赋值,使用逗号隔开.data = np.random.multivariate_normal(mean=mean, cov=cov, size=200)df = pd.DataFrame(data=data, columns=['x', 'y'])print('df=', '\n', df)# 联合图,包含直方图sns.jointplot(x='x', y='y', data=df)plt.show()# 联合图,不包括直方图sns.relplot(x='x', y='y', data=df)plt.show()# 带核密度函数估计的二元分布图sns.jointplot(x='x', y='y', data=df, kind='kde')plt.show()# 热力图np.random.seed(0)data = np.random.uniform(low=-1, high=1, size=(7, 7))index = list('abcdefg')columns = list('ABCDEFG')df = pd.DataFrame(data=data, index=index, columns=columns)print('df=', '\n', df)plt.figure(figsize=(8, 6))sns.set(font_scale=1.5)# 解决title中文乱码问题,放在sns.set后面.plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文plt.rcParams["axes.unicode_minus"] = False # 设置显示中文后,负号显示受影响,显示负号sns.heatmap(df)plt.xlabel('columns', fontsize=13)plt.ylabel('index', fontsize=13)plt.title('热力图')plt.show()
参考
Python数据处理之数据可视化(二维、三维)
机器学习算法(二十一):核密度估计 Kernel Density Estimation(KDE)