概述:
Meta开发并发布了Meta-Lama 3大语言模型家族(LLM),Llama 3指令调优模型针对对话用例进行了优化,在常见的行业基准上优于许多可用的开源聊天模型。本文尝试对LLAMA3 在中文语料中尝试进行fine tune 为后续对 通义千问的模型进行比较。
代码实现:
加载依赖
from datasets import load_dataset
from transformers import (AutoModelForCausalLM,AutoTokenizer,BitsAndBytesConfig,HfArgumentParser,AutoTokenizer,TrainingArguments,Trainer,GenerationConfig
)
from tqdm import tqdm
from trl import SFTTrainer
import torch
import time
import pandas as pd
import numpy as np
from huggingface_hub import interpreter_login
from datasets import Dataset, DatasetDict
from functools import partial
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import os
# 禁用权重和偏差
os.environ['WANDB_DISABLED']="true"
数据加载
git clone https://www.modelscope.cn/datasets/DAMO_NLP/lcsts_test_set.git
data_train_pth ='../Fine-tune/data/lcsts_test_set/{}'.format('train.csv')
data_train = pd.read_csv(data_train_pth)data_test_pth = '../Fine-tune/data/lcsts_test_set/{}'.format('test.csv')
data_test = pd.read_csv(data_test_pth)print(data_train.shape)
print(data_test.shape)#这里看到原本的训练集合很大 减少部分的训练集以便更快的看到结果
data_train = data_train.head(2000)data_train = Dataset.from_pandas(data_train)
data_test = Dataset.from_pandas(data_test)print(data_train)
(100000, 2)
(725, 2)
Dataset({
features: [‘text1’, ‘text2’],
num_rows: 2000
})
模型加载
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=False,)
model_name=r'D:\临时模型\Meta-Llama-3-8B-Instruct'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name, device_map=device_map,quantization_config=bnb_config,trust_remote_code=True,use_auth_token=True)tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,padding_side="left",add_eos_token=True,add_bos_token=True,use_fast=False)
tokenizer.pad_token = tokenizer.eos_token数据预处理
#处理的是中文,所以添加中文的提示工程
def create_prompt_formats(sample):"""格式化示例的各个字段('instruction','output')然后使用两个换行符将它们连接起来:参数sample:样本字典"""ROLE_PROMPT = "你是一个文本记录员,擅长归纳文章的内容。"#校色说明INTRO_BLURB = " 需要将了解到的内容进行总结概括并输出。尽可能用最少得字来完事内容的概述"#任务简介INSTRUCTION_KEY = "### 要求:总结以下对话。"RESPONSE_KEY = "### 总结:"END_KEY = "### 结束"blurb = f"\n{INTRO_BLURB}"instruction = f"{INSTRUCTION_KEY}"input_context = f"{sample['text1']}" if sample["text1"] else Noneresponse = f"{RESPONSE_KEY}\n{sample['text2']}"end = f"{END_KEY}"parts = [part for part in [blurb, instruction, input_context, response, end] if part]formatted_prompt = "\n\n".join(parts)sample["text"] = formatted_promptreturn sampledef get_max_length(model):conf = model.configmax_length = Nonefor length_setting in ["n_positions", "max_position_embeddings", "seq_length"]:max_length = getattr(model.config, length_setting, None)if max_length:print(f"Found max lenth: {max_length}")breakif not max_length:max_length = 1024print(f"Using default max length: {max_length}")return max_lengthdef preprocess_batch(batch, tokenizer, max_length):"""token处理"""return tokenizer(batch["text"],max_length=max_length,truncation=True,)def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int,seed, dataset):"""格式化并标记它,以便为培训做好准备参数标记器(AutoTokenizer):模型标记器:param max_length (int):从标记器发出的标记的最大数量"""# 在每个示例中添加提示print("开始数据预处理...")dataset = dataset.map(create_prompt_formats)#, batched=True)# 对每一批数据集&进行预处理_preprocessing_function = partial(preprocess_batch, max_length=max_length, tokenizer=tokenizer)dataset = dataset.map(_preprocessing_function,batched=True,remove_columns=['text1', 'text2'],)# 过滤掉input_ids超过max_length的样本dataset = dataset.filter(lambda sample: len(sample["input_ids"]) < max_length)# 打乱数据dataset = dataset.shuffle(seed=seed)return dataset
## 开始处理数据
max_length = get_max_length(original_model)
print(max_length)seed=123train_data = preprocess_dataset(tokenizer, max_length,seed, data_train)
eval_data = preprocess_dataset(tokenizer, max_length,seed, data_test)
Found max lenth: 8192
8192
模型参数调整
output_dir = f'./LLAMA_peft-dialogue-summary-training-{str(int(time.time()))}'
peft_config = LoraConfig(lora_alpha=16, lora_dropout=0.1,r=64,bias="none",#target_modules="all-linear",task_type="CAUSAL_LM",#inplace=False,target_modules=['q_proj','k_proj','v_proj','dense'],
)training_arguments = TrainingArguments(output_dir=output_dir, # 保存训练日志和检查点的目录num_train_epochs=5, # 为其训练模型的历元数。一个epoch通常指的是通过整个训练数据集一次的前向传播和反向传播过程。#num_train_epochs 被设置为3,意味着模型将完整地遍历训练数据集3次。per_device_train_batch_size=1, # 每个设备上每个批次的样本数。gradient_accumulation_steps=8, # 执行向后/更新过程之前的步骤数gradient_checkpointing=True, # 使用渐变检查点保存内存optim="paged_adamw_8bit", #"paged_adamw_8bit"/"paged_adamw_32bit" 用于训练模型的优化器save_steps=400,logging_steps=400, # 记录训练指标的步骤数。它被设置为50,意味着每50个训练步骤,训练指标将被记录一次。learning_rate=2e-4, # 学习率weight_decay=0.001,fp16=True,bf16=False,max_grad_norm=0.3, # 基于QLoRA的最大梯度范数max_steps=2000, #1000, #这个建议设置上,不然会出现很多次的训练轮warmup_ratio=0.03, # 基于QLoRA的预热比group_by_length=True,lr_scheduler_type="cosine", # 使用余弦学习率调度report_to="tensorboard", # 向tensorboard报告指标 可选"none"evaluation_strategy="epoch", # 每个纪元保存检查点 可选"steps" 这个参数设置了评估策略。#代码中设置为"epoch",意味着评估将在每个epoch结束后进行。由于eval_steps也设置为50,这可能意味着评估将在每50个训练步骤或每个epoch#warmup_steps = 1#logging_dir="./logs",#save_strategy="steps",eval_steps=200,#意味着每50个训练步骤,模型将在验证集上进行一次评估。do_eval=True,overwrite_output_dir =True
)
"""
上述参数,模型将在以下情况下停止训练:完成3个epoch的训练,无论eval_steps条件是否满足。
如果训练数据集的大小导致在3个epoch内无法达到50个训练步骤,那么模型将在完成所有训练步骤后停止。
至于评估输出,由于logging_steps和eval_steps都设置为50,这意味着:每50个训练步骤,训练指标将被记录一次。
每50个训练步骤,模型将在验证集上进行一次评估。
"""#training_arguments.config.use_cache = False
#transformers.Trainer
"""
transformers.Trainer:如果你有一个大的数据集,并且需要为你的培训循环或复杂的培训工作流程进行广泛的定制。
使用SFTTrainer:如果你有一个预训练的模型和相对较小的数据集,并且想要更简单、更快的微调体验和高效的内存使用。如果训练数据集较小,可能导致在每个epoch中训练步骤数少于50步,那么eval_steps条件可能不会触发,评估将在每个epoch结束后根据evaluation_strategy参数的设置进行。另外,max_steps参数通常用于设置训练的最大步骤数,以防止训练超过预定的epoch数。
代码中,max_steps被设置为1000,这个值远大于由num_train_epochs和per_device_train_batch_size参数隐式定义的训练步骤数。
因此,除非训练数据集非常大,否则这个参数在上下文中可能不会起作用。
如果max_steps的值大于完成所有epoch所需步骤数的总和,训练将在完成所有epoch后停止,而不是在达到max_steps指定的步骤数时停止。
"""
trainer = SFTTrainer(model=original_model,args=training_arguments,#train_dataset=train_data,eval_dataset=eval_data,peft_config=peft_config,# 模型配置文件dataset_text_field="text",tokenizer=tokenizer,max_seq_length=1024,packing=False,dataset_kwargs={"add_special_tokens": False,"append_concat_token": False,}
)"""
#可选
trainer = transformers.Trainer(model=peft_model,train_dataset=train_data,eval_dataset=eval_data,args=training_arguments,data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
"""
output_dir ( str) – 将写入模型预测和检查点的输出目录。
overwrite_output_dir(bool,可选,默认为False) – 如果为True,则覆盖输出目录的内容。如果output_dir指向检查点目录,请使用它继续训练 。
do_train ( bool,可选, 默认为False) – 是否运行训练。
do_eval ( bool,可选, 默认为False) – 是否在开发集上运行评估。
do_predict ( bool,可选, 默认为False) – 是否在测试集上运行预测。
evaluate_during_training (bool,可选,默认为False) – 是否在每个记录步骤的训练期间运行评估。
per_device_train_batch_size ( int,可选,默认为 8)– 用于训练的每个 GPU/TPU 核心/CPU 的批量大小。
per_device_eval_batch_size(int,可选,默认为 8) – 用于评估的每个 GPU/TPU 核心/CPU 的批处理大小。
gradient_accumulation_steps – (int,可选,默认为 1):在执行向后/更新传递之前累积梯度的更新步骤数。
Learning_rate ( float,可选,默认为 5e-5) – Adam 的初始学习率。
Weight_decay ( float,可选,默认为 0) – 要应用的权重衰减(如果不为零)。
adam_epsilon ( float,可选,默认为 1e-8) – Adam 优化器的 Epsilon。
max_grad_norm ( float,可选,默认为 1.0) – 最大梯度范数(用于梯度裁剪)。
num_train_epochs ( float,可选,默认为 3.0) – 要执行的训练周期总数。
max_steps ( int,可选,默认为 -1) – 如果设置为正数,则为要执行的训练步骤总数。覆盖 num_train_epochs.
Warmup_steps ( int,可选,默认为 0) – 用于线性预热的步数,从 0 到learning_rate。
logging_dir ( str,可选) – Tensorboard 日志目录。默认为运行/CURRENT_DATETIME_HOSTNAME。
logging_first_step ( bool,可选, 默认为False) – 是否记录并评估第一个global_step。
logging_steps ( int,可选,默认为 500) – 两个日志之间的更新步骤数。
save_steps ( int,可选,默认为 500) – 两次检查点保存之前的更新步骤数。
save_total_limit ( int,可选) – 如果传递一个值,将限制检查点的总数。删除 中较旧的检查点 output_dir。
no_cuda(bool,可选,默认为False) – 是否不使用 CUDA,即使它可用或不可用。
seed(int,可选,默认为 42) – 用于初始化的随机种子。
fp16(bool,可选,默认为False) – 是否使用 16 位(混合)精度训练(通过 NVIDIA apex)而不是 32 位训练。
fp16_opt_level(str,可选,默认为 'O1') – 对于fp16训练,在 [‘O0’、‘O1’、‘O2’ 和 ‘O3’] 中选择顶点 AMP 优化级别。请参阅apex 文档的详细信息。
local_rank ( int,可选, 默认为 -1)– 在分布式训练期间,进程的排名。
tpu_num_cores ( int,可选) – 在 TPU 上训练时,TPU 核心的数量(由启动器脚本自动传递)。
debug ( bool,可选,默认为False) – 在 TPU 上训练时,是否打印调试指标。
dataloader_drop_last ( bool,可选, 默认为False) – 是否删除最后一个不完整的批次(如果数据集的长度不能被批次大小整除)。
eval_steps ( int,可选,默认为 1000) – 两次评估之间的更新步骤数。
past_index ( int,可选,默认为 -1) – TransformerXL或 :docXLNet <…/model_doc/xlnet> 等模型可以利用过去的隐藏状态进行预测。如果此参数设置为正整数,则将 Trainer使用相应的输出(通常为索引 2)作为过去状态,并在关键字参数下的下一个训练步骤中将其馈送到模型mems。
模型运行
trainer.train()
#模型保存
trainer.save_model()
#保存token
tokenizer.save_pretrained(output_dir)
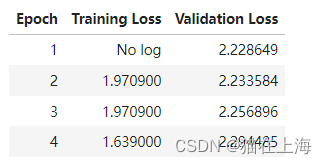
效果不非常理想。测试集上基本没有下降。
人工测试
模型保存
import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer,BitsAndBytesConfigdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#路径是输出的模型路径
finetuned_model = "F:\python_code\AIGC\Finetune\LLAMA_peft-dialogue-summary-training-1715510377\checkpoint-250"
compute_dtype = getattr(torch, "float16")
tokenizer = AutoTokenizer.from_pretrained(r"D:\临时模型\Meta-Llama-3-8B-Instruct")bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=False,)model = AutoPeftModelForCausalLM.from_pretrained(finetuned_model,torch_dtype=compute_dtype,quantization_config=bnb_config,return_dict=False,low_cpu_mem_usage=True,device_map=device,
)merged_model = model.merge_and_unload()merged_model.save_pretrained("./merged_summary_model_3",safe_serialization=True, max_shard_size="2GB")
tokenizer.save_pretrained("./merged_summary_model_3")
比对测试
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM,BitsAndBytesConfig
#from transformers import
import time
import pandas as pd
from datasets import Datasetcompute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type='nf4',bnb_4bit_compute_dtype=compute_dtype,bnb_4bit_use_double_quant=False,)model_name=r'F:\python_code\AIGC\Finetune\merged_summary_model_3'
#model_name=r'D:\临时模型\Meta-Llama-3-8B-Instruct'device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name, device_map=device_map,quantization_config=bnb_config,trust_remote_code=True,use_auth_token=True)tokenizer = AutoTokenizer.from_pretrained(model_name,trust_remote_code=True,padding_side="left",add_eos_token=True,add_bos_token=True,use_fast=False)
tokenizer.pad_token = tokenizer.eos_tokendata_test_pth = '../Fine-tune/data/lcsts_test_set/{}'.format('test.csv')
data_test = pd.read_csv(data_test_pth)
data_test = Dataset.from_pandas(data_test)seed = 123def gen(model,p, maxlen=100, sample=True):toks = tokenizer(p, return_tensors="pt") #token转换#构建模型的对话摸索res = model.generate(**toks.to("cuda"), max_new_tokens=maxlen, do_sample=sample,num_return_sequences=1,temperature=0.1,num_beams=1,top_p=0.95,).to('cpu')return tokenizer.batch_decode(res,skip_special_tokens=True)from transformers import set_seed
seed = 42
set_seed(seed)index = 10prompt = data_test[index]['text1']
summary = data_test[index]['text2']#指导:总结以下对话。\n{prompt}\n输出:\n
formatted_prompt = f"总结以下对话.并使用中文回答\n{prompt}\n总结:\n"#输入模型 提示词 ,maxlen
res = gen(original_model,formatted_prompt,100,)#print(res[0])
output = res[0].split('\n')[3]
dash_line = '-'.join('' for x in range(100))#分割符
print(dash_line)
print(f'输入提示词:\n{formatted_prompt}')
print(dash_line)
print(f'目标值:\n{summary}\n')
print(dash_line)
print(f'模型输出:\n{output}')
PEFT结果

原始模型结果

感觉和没有训练过的模型输出基本一致。还是需要使用中文类型的模型进行fine tune。
以上是本文的全部内容。