本科毕业设计(论文)开题报告
| 课题名称 | 基于Spark的音乐推荐与数据分析系统 | ||
| 的设计与实现 | |||
| 课题类型 | 系统设计 | 学院 | 大数据与人工智能学院 |
| 班级 | 专业 | 数据科学与大数据技术 | |
| 指导教师 | 职称 | ||
| 学生姓名 | 学号 | ||
重庆工程学院教务处制
| 1.课题名称、来源、选题依据 | |
| 1.1课题名称 基于Spark的音乐推荐与数据分析系统的设计与实现 1.2课题来源 课题来源于算法研究。 1.3选题依据 互联网在如今的爆发式发展已经改变了我们的生活方式,互联网上资源的爆发式增长让获取有效信息成为了新的难题[1]。用户接触到的信息非常有限。于是很多提出帮助用户快速精准找到所需信息的解决方案诞生了,例如搜索引擎,推荐系统等。 目前大型的音乐门户类网站的歌曲库规模往往包含上千万首的歌曲,这些歌曲被划分成不同的语种、流派、年代、主题、心情、场景等,包含的信息非常的丰富,存在着严重的信息过载[2]。对于系统中每一位音乐用户来说,都不可能去收听曲库内的每一首歌, 很多时候用户的需求往往是“一首或几首好听的歌曲”这种模糊的需求,如何根据用户在系统中产生的行为信息去庞大的歌曲库中挖掘出用户可能感兴趣的音乐,这就需要个性化音乐推荐系统综合考虑用户偏好、时间、地点、环境等各种复杂的特征[3],准确的从上千万的海量歌曲库中挑选出此时此刻最适合这个用户聆听的个性化音乐,给广大的用户带来美的享受,真正做到众口可调。 | |
| 2.课题国内外研究现状和发展趋势 | |
| 2.1国外研究现状 国内的音乐推荐技术发展相对缓慢。大多数音乐网站采用的技术不够成熟,基本上是针对所有用户,大数据成分太少[1]。不过,经过一段时间的发展,国内也涌现出了一些优秀的音乐推荐网站,比如 SongTaste、虾米网和豆瓣网等。SongTaste 是一个社交性质的音乐网站。在它的社区中,每一个用户都可以看到大家最近在收听什么音乐、有什么新的音乐推荐[2]。它的音乐分类相当齐全,而且推荐排行实时更新。另外,根据用户平时推荐的音乐、听歌行为以及音乐收录信息,还能够找到“相似的品味者”,从而更好地做出推荐。豆瓣网也是一个社交性的音乐推荐网站。它主要通过豆瓣小组、新浪微博、MSN、开心网、人人网等互动平台来分享和传播用户喜欢的音乐。虾米网在注册成为网站会员时会让用户选择至少5位艺人进行收藏,以此来初步确定用户欣赏音乐的倾向[3]。另外,用户还可以从大家的推荐中搜索自己喜爱的音乐,或者从品味相似的好友中找到适合自己的音乐[4]。 2.2国内研究现状 国外研究现状:大数据推荐系统的定义是 Resnick 和 Varian 在 1997 年给出的:“它是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”[5]。从最初在电子商务网站的深度剖析,到当下在的音乐、电影、学习资料等不同领域的广泛应用。在三十多年的时间里,大数据推荐系统一直是学术界和工业界的关注的焦点。其优点在于主动性。它能自发地收集并分析用户的行为数据,为用户的兴趣建模,得到用户的兴趣偏好后,匹配系统中资源的特征,为用户做出有效的大数据推荐[6]。同时,推荐引擎要一直监测系统中的项目变化和用户在不同行为下的兴趣特征变迁,针对不同的变动,做出相应推荐策略的调整[7]。各平台为增加用户的黏着性,以及用户对推荐结果的准确度要求,使得推荐系统的核心技术层出不穷[8],比较成熟的推荐技术有:基于内容的推荐、协同过滤(基于相似度的最邻近协同过滤算法、基于潜在因子的矩阵分解推荐算法)、深度学习、基于标签的推荐系统、混合推荐算法等。 2.3发展趋势 综上所述,Spark在处理音乐数据方面有一些独特的技术优势。例如,Spark的MLlib库提供了多种机器学习算法,可以用于处理音乐数据,包括协同过滤、分类、聚类等。此外,Spark的流处理技术也可以用于实时音乐推荐。随着人工智能和机器学习技术的不断发展,Spark在音乐推荐方面的应用也将不断加强。例如,Spark可以使用深度学习算法来对音乐数据进行更深入的分析和处理,以提高音乐推荐的精准度和用户满意度。 | |
| 3.本课题的目的及意义 | |
| |
| 4.本课题的任务、重点内容、研究方法、实现途径、进度计划 | |
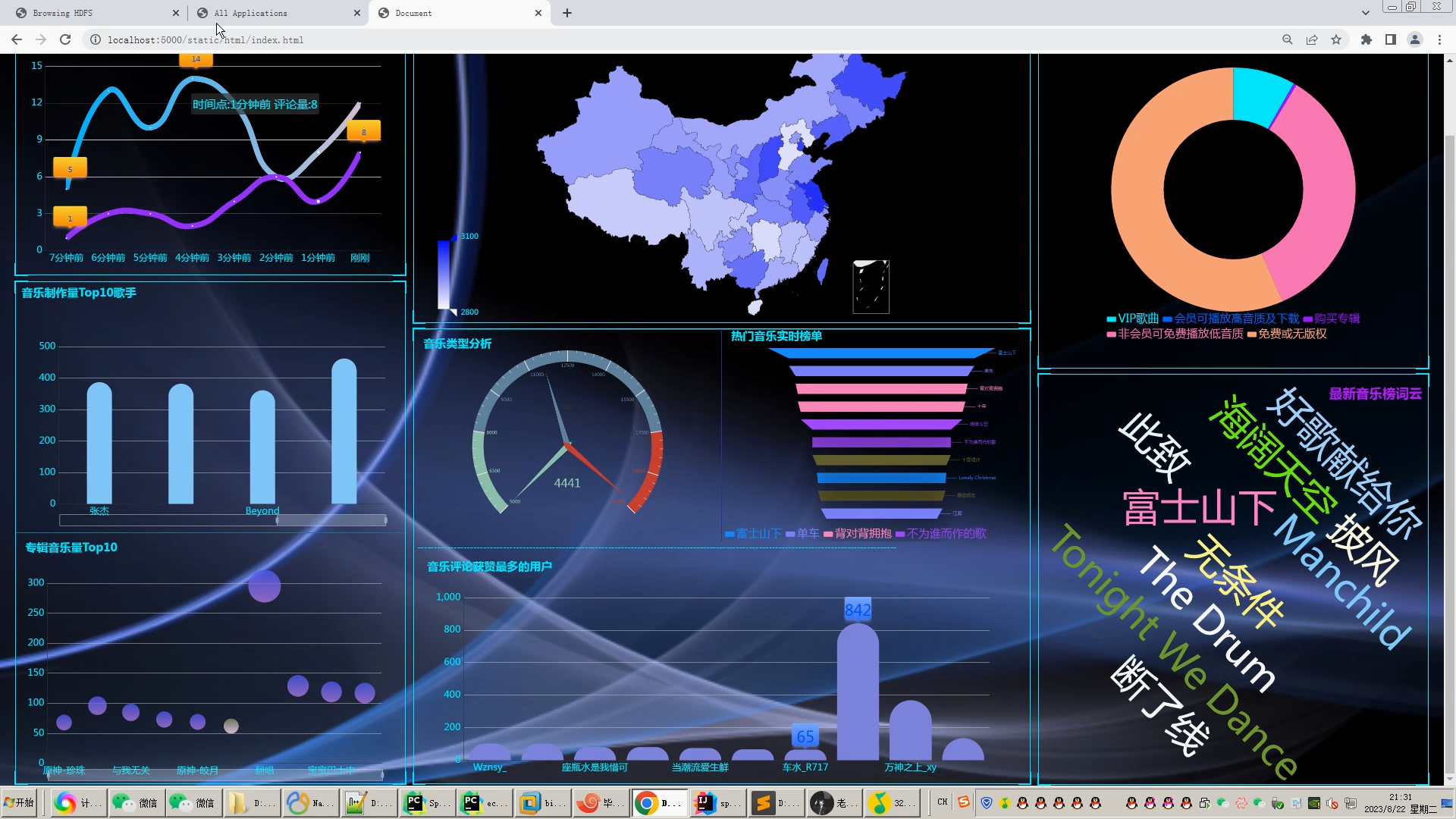
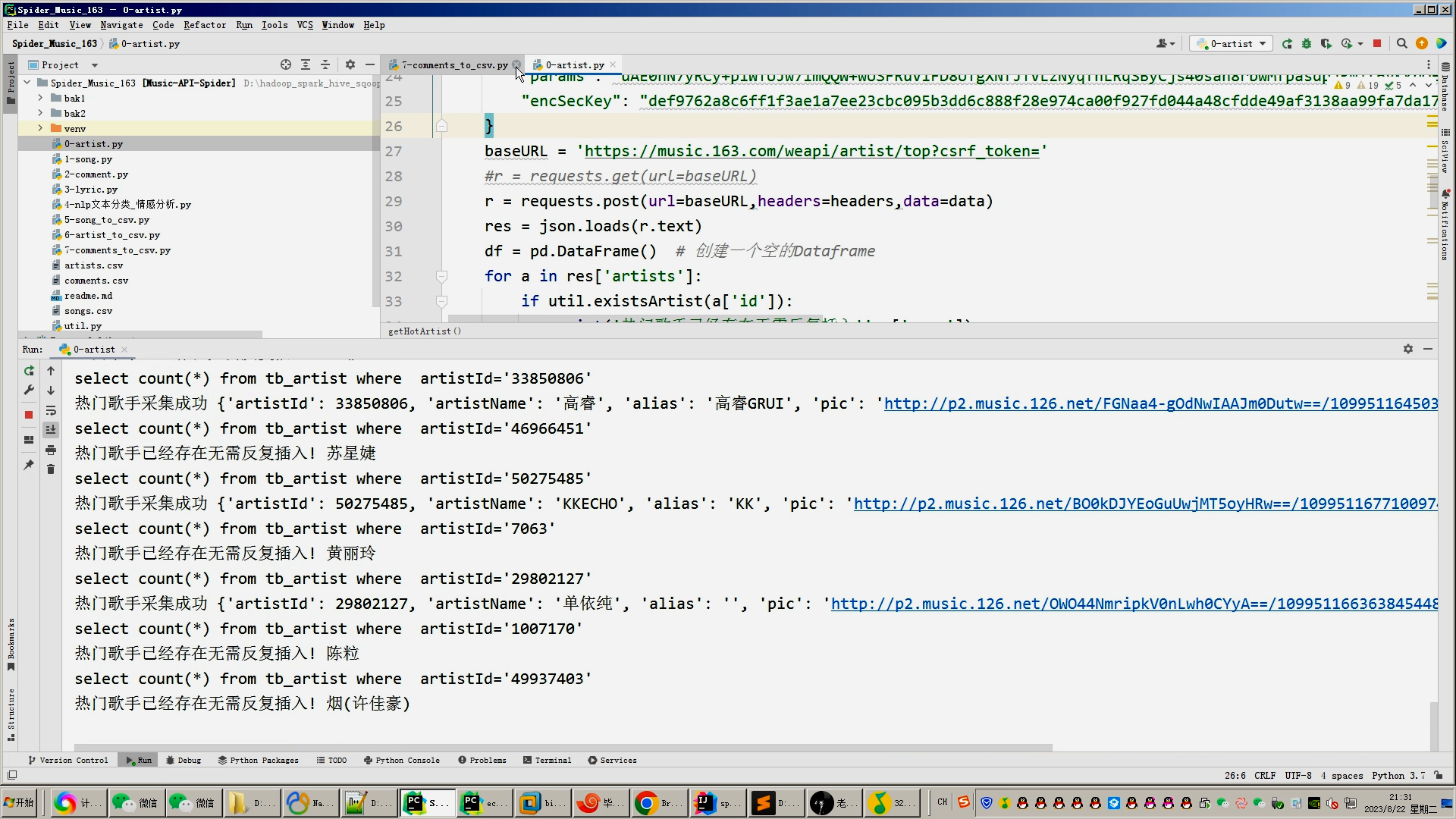
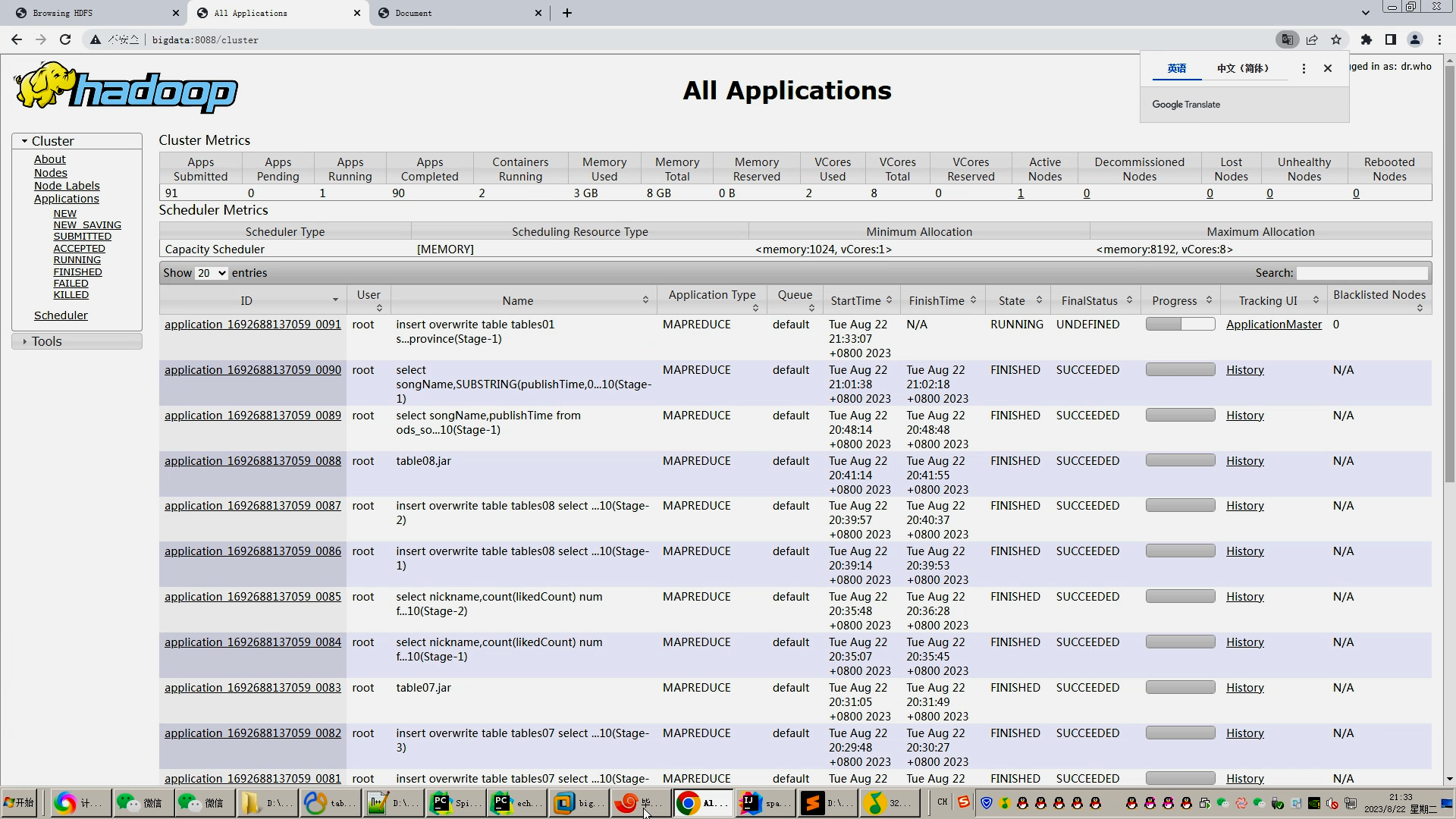
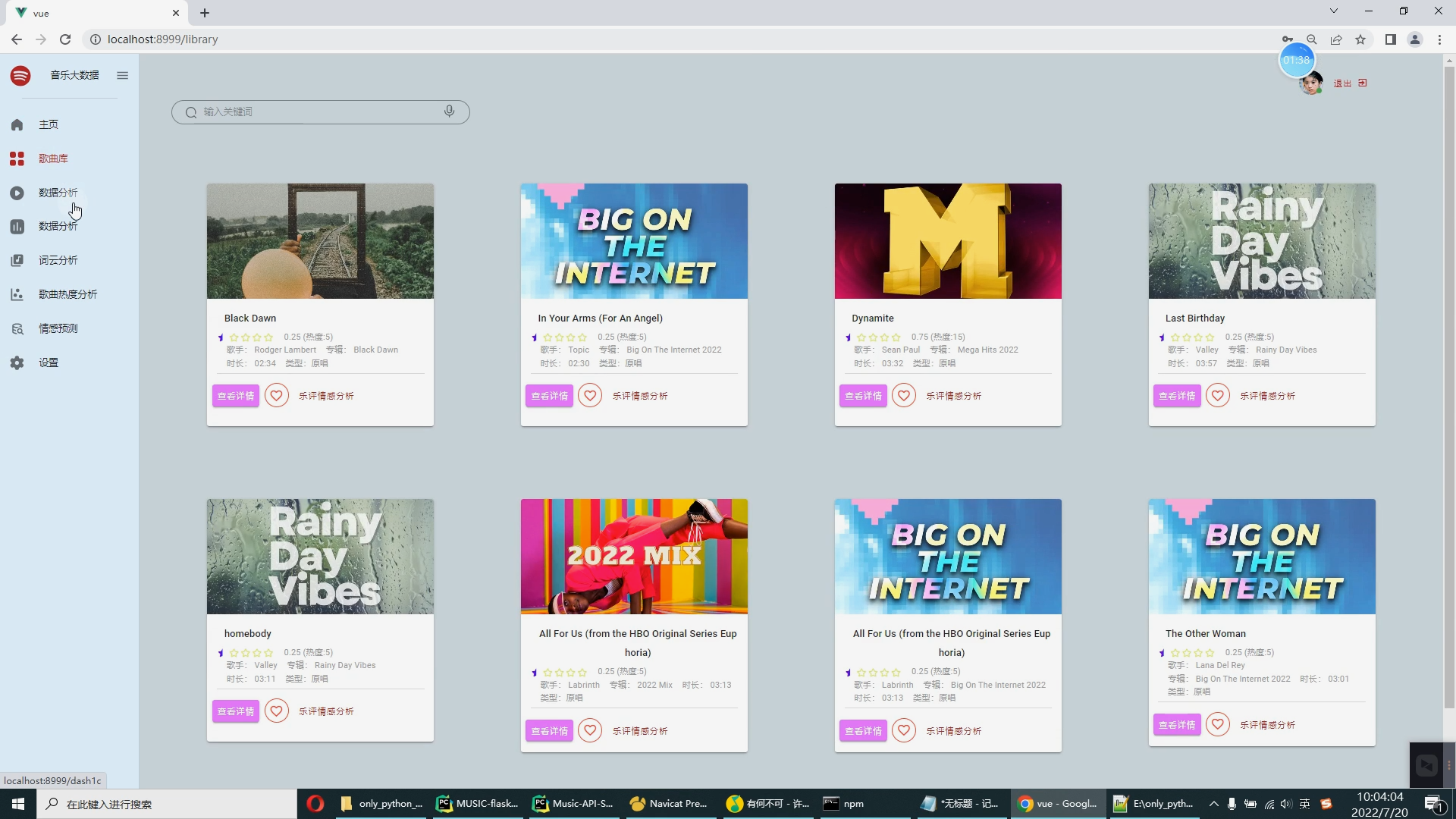
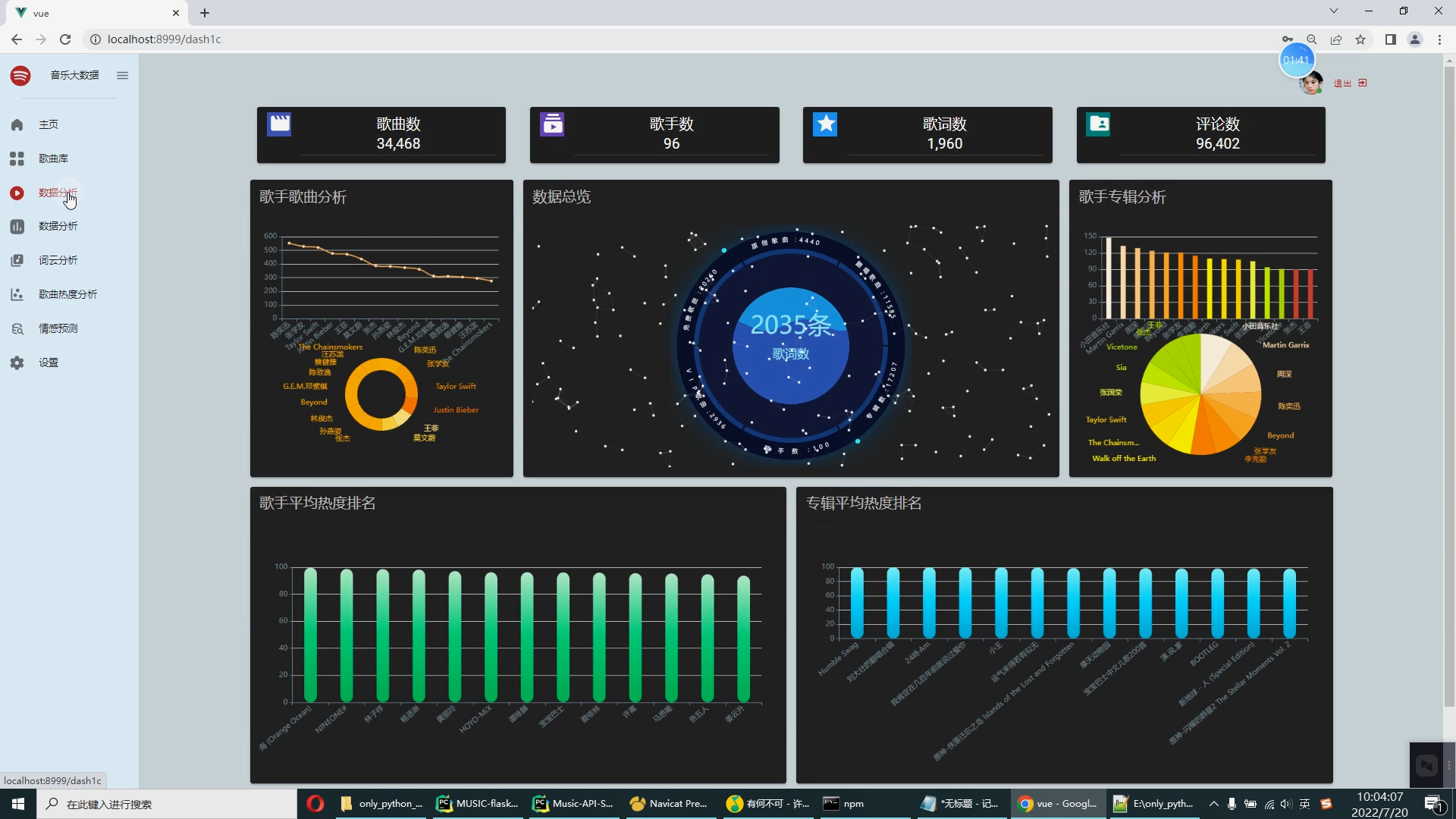
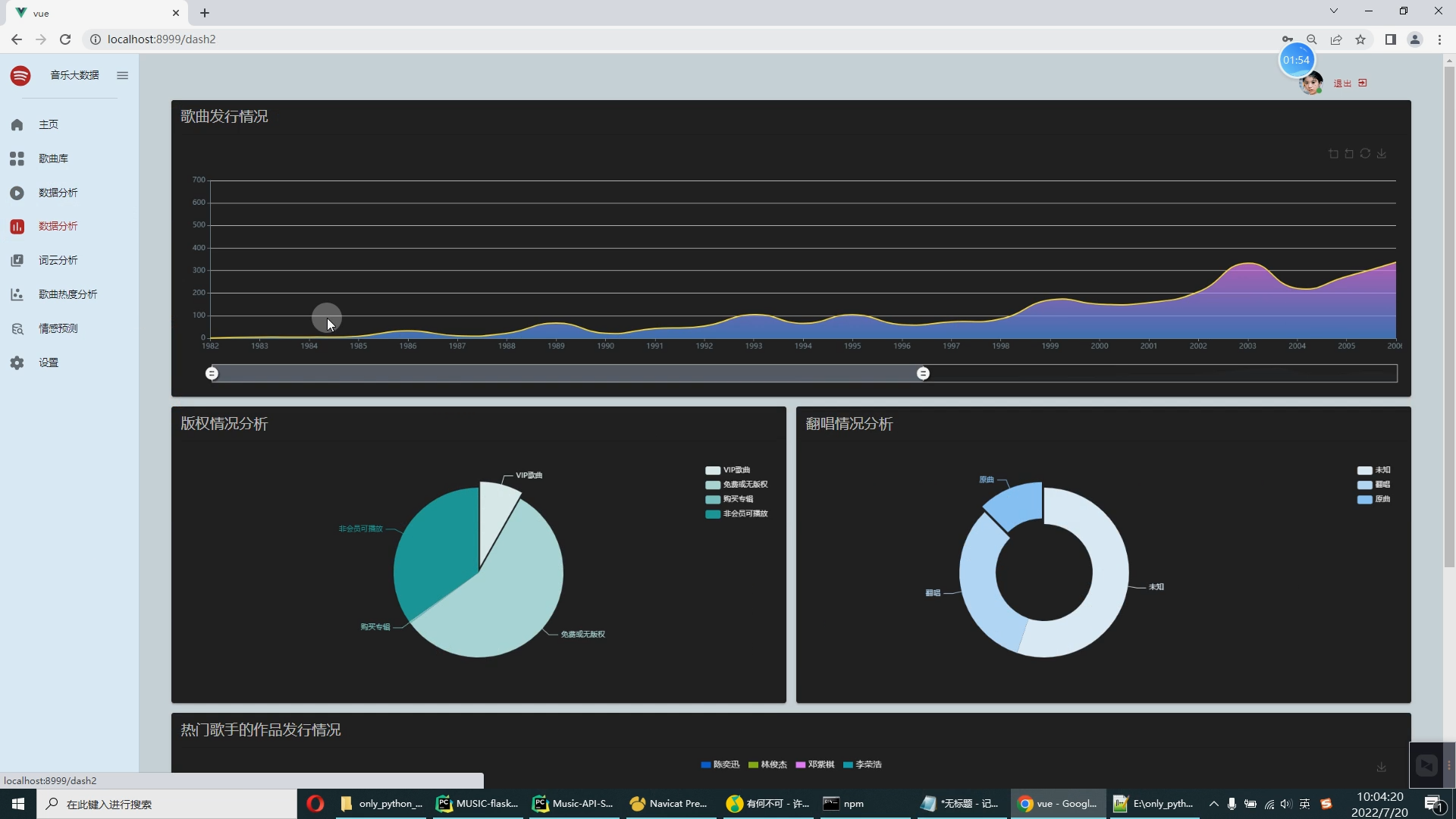
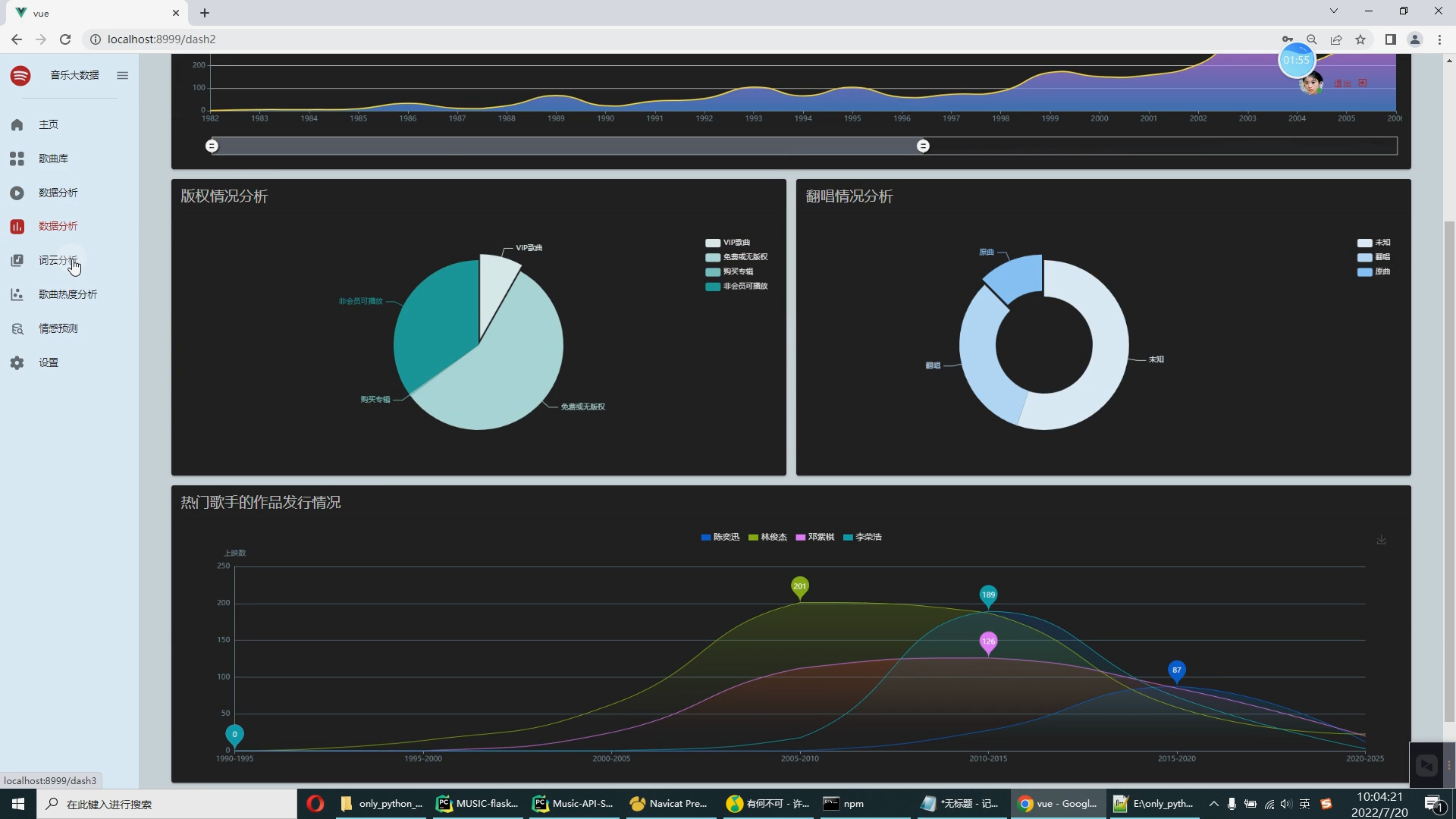
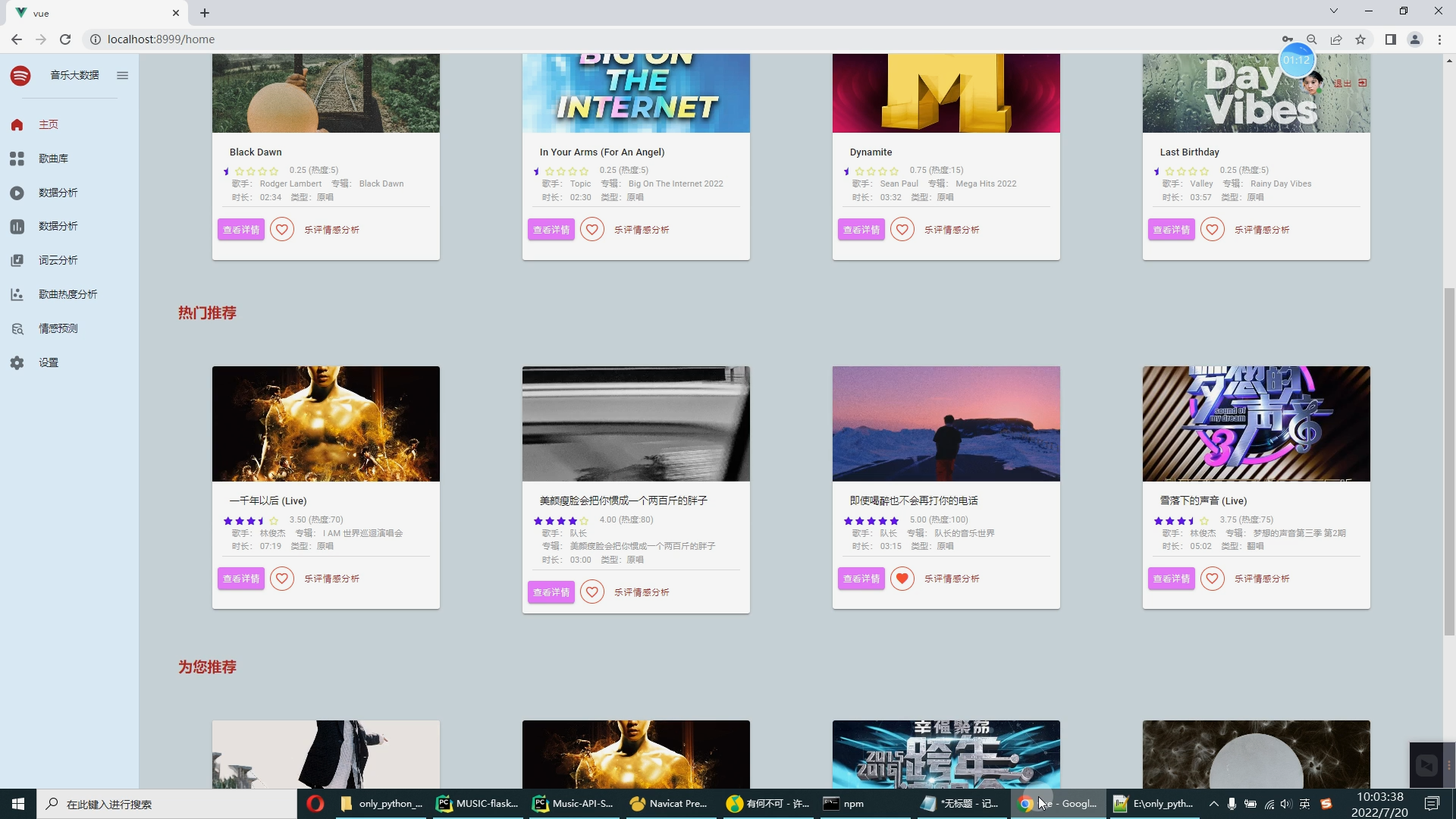
| 4.1课题任务 系统实现用户对音乐评分的搜集(python爬虫爬取数据),后端使用大数据推荐算法构造,前端使用Vue框架搭建大数据音乐推荐系统。系统数据库使用了关系型数据库MySQL。前端收集过用户行为数据后传到后端使用基于用户的协同过滤算法来推荐出用户可能喜欢的音乐。采用BS架构,使用Java程序设计语言、MySQL数据库、Spark实时分析、Java开发工具IDEA编写程序、Tomcat模拟服务器、Java的JDK8运行环境、Navicat等工具开发而来。 4.2重点内容
4.3研究方法
4.4实现途径
4.5本课题的进度时间安排; ①2023.11.13-2023.12.10:完成开题报告。 ②2023.12.11-2023.12.18:完成音乐数据爬取与处理工作。 ③2023.12.19-2023.12.26:完成数据仓库设计。 ④2023.12.27-2024.01.11:完成Hive和Hadoop、Spark的环境搭建工作。 ⑤2024.01.12-2024.02.25:完成推荐算法与数据可视化功能开发。 ⑥2024.02.01-2024.02.29:完成毕业设计(论文)初稿。 ⑦2024.03.01-2024.03.15:中期检查及项目功能完善。 ⑧2024.03.16-2024.04.14:功能完善以及毕业设计(论文)定稿查重。 ⑨2024.04.15-2024.04.30:毕业设计(论文)评阅,根据评阅老师意见修改论文,完善设计。 ⑩2024.05.01-2024.05.26:毕业设计(论文)答辩。 | |
| 5.完成本课题所需工作条件(如工具书、计算机、实验、调研等)及解决办法 | |
| 本课题所需工作条件 ①Windows10系统电脑一台、16G内存、8核处理器 ②编辑器:Python 3.8、Anaconda 3、PyCharm、VMware、IDEA ③Navicat Premium 15 ④MySQL、Hive、Hadoop、Azkaban、Spark | |
| 参考文献 | |
| [1]LAWRENCERD, ALMASIGS, KOTLYARV, et al. Personalization of supermarket product recommendations[ R]. IBM Research Report,2020(7):173-181 [2]徐小伟. 基于信任的协同过滤推荐算法在电子商务推荐系统的应用研究. 东华大学. 2023 [3] 吴正洋. 个性化学习推荐研究. 华南师范大学期刊.2021 [4]李雪. 基于协同过滤的推荐系统研究. 吉林大学. 2020 [5]《数据库系统概论》[M],高等教育出版社. 2020 [6]马建红.JSP应用与开发技术.第三版.清华大学出版社.2022 [7] JavaEE架构设计与开发实践[M],方巍著:清华大学出版社.2022.1 [8] Spring Boot编程思想核心篇[M],小马哥著:电子工业出版社.2023.4 [9] Spring Boot开发实战M].吴胜著:清华大学出版社.2023.6 [10]Oleg Sukhoroslov. Building web-based services for practical exercises in parallel and distributed computing[J]. Journal of Parallel and Distributed Computing.2023. | |
| 指导教师意见 | 该开题报告的实验设计部分详细说明了实验环境、实验数据、实验方法和实验结果等,具有可行性和可操作性。预期成果部分也明确了研究的目标和可能取得的成果,为后续的研究提供了清晰的方向和目标。重点任务明确、研究方法得当、实现途径清晰、进度安排合理。同意开题 签字: 年 月 日 |
| 系(教研室)意见 | 通过研究内容和方法合理,同意开题 系(教研室)主任签字: 年 月 日 |
核心算法代码分享如下:
#Flink连接HDFS上面的CSV文件 使用Flink_SQL分析完入表
## 启动hadoop
## cd /data/hadoop/sbin
## sh /data/hadoop/sbin/start-all.sh
## 启动hive
## cd /data/hive
## nohup hive --service metastore &
## nohup hive --service hiveserver2 &
import os
from pyflink.common import Row
from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema,DataTypes, FormatDescriptor)
from pyflink.table.expressions import lit, col
from pyflink.table.udf import udtf
import logging
import syslogging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)jars = []
for file in os.listdir(os.path.abspath(os.path.dirname(__file__))):if file.endswith('.jar'):file_path = os.path.abspath(file)jars.append(file_path)str_jars = ';'.join(['file:///' + jar for jar in jars])
table_env.get_config().get_configuration().set_string("pipeline.jars", str_jars)
# table_env.get_config().get_configuration().set_float('taskmanager.memory.network.fraction',0.8)
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.min','8gb')
# table_env.get_config().get_configuration().set_string('taskmanager.memory.network.max','16gb')
table_env.get_config().get_configuration().set_string('parallelism.default','1')
#先读取hadoop_hdfs上的CSV文件
table_env.execute_sql("""create table ods_earthquake(`magnitude` double COMMENT '震级(M)',`stime_long` string COMMENT '发震时刻(UTC+8)',`latitude` string COMMENT '纬度(°)',`longitude` string COMMENT '经度(°)',`depth` bigint COMMENT '深度(千米)',`addr` string COMMENT '参考位置',`stime_short` string COMMENT '年月日',`data_type` string COMMENT '数据类型(用于区分中国外国)',`long_province` string COMMENT 'echarts中国地图省份专用字段(外国是:无(外国))',`stime_year` string COMMENT '年',`stime_month` string COMMENT '月',`stime_clock` string COMMENT '时刻中的时') WITH('connector' = 'filesystem','path' ='hdfs://bigdata:9000/earthquake/ods_earthquake/earthquake_hdfs.csv','format' = 'csv') """)#设置下沉到mysql的表
table_env.execute_sql("""create table table05(`addr` string primary key ,`num` bigint ) WITH('connector' = 'jdbc','url' = 'jdbc:mysql://bigdata:3306/hive_earthquake','table-name' = 'table05','username' = 'root','password' = '123456','driver' = 'com.mysql.jdbc.Driver') """)#数据分析并且导入
#result=table_env.sql_query("select * from ods_zymk limit 10 ")
table_env.execute_sql("""insert into table05select addr , count(*) numfrom ods_earthquakeWHERE data_type <> '外国'GROUP BY addr order by num desclimit 10;""").wait()
#print("表结构",result.get_schema())
#print("数据检查",result.to_pandas())