01
引言
Apache Kafka 自诞生之日起,就以其卓越的设计和强大的功能,成为了流处理领域的标杆。它不仅定义了现代流处理架构,更以其独特的分布式日志抽象,为实时数据流的处理和分析提供了前所未有的能力。Kafka 的成功,在于它能够满足各种规模企业对于高吞吐量、低延迟数据处理的需求,经过多年的发展铸就了极其丰富的 Kafka 生态,成为了事实上的行业标准。
然而,随着云计算和云原生技术的飞速发展,Kafka 面临的挑战也日益严峻。传统的存储架构已难以适应云环境下用户对更优成本、弹性的诉求,这引发了大家对 Kafka 存储模型的重新思考。分层存储(Tiered Storage)一度被视为可能的解决方案,它试图通过将数据分层存储在不同的介质上,来降低成本并延长数据的生命周期。但实践表明,这种方法并没有彻底解决 Kafka 的痛点,反而增加了系统的复杂性和运维难度。在新时代背景下,随着云计算以及像 S3 这样的现象级云服务的成熟,我们认为,共享存储才是解决 Kafka 原有痛点的“良药”。通过创新的共享存储架构,我们提供了一种比 Tiered Storage 以及 Freight Clusters 更优的存储方案,使得 Kafka 可以继续在云时代引领流系统的发展。我们以存算分离的方式将 Kafka 的存储层替换为了共享的流存储库并复用了其 100% 的计算层代码,保证了对 Kafka API 协议和生态的完全兼容。通过将 Apache Kafka 的存储层对接至对象存储,充分获得了共享存储带来的技术和成本优势,彻底解决了原有 Kafka 在成本、弹性等方面的弊病。本文将详细解读 Kafka 存储架构的演进之路以及我们创新的共享存储架构实现背后的思考,希望给读者带来更多现代化流存储系统设计的启发。
02
本地磁盘上过时的Shared Nothing架构
Apache Kafka,作为一款广泛使用的流处理平台,其背后的存储架构一直是以本地磁盘为中心的 Shared Nothing 架构。然而,随着云计算技术的不断进步,这种传统架构正面临着前所未有的挑战。Shared Nothing 架构指的是系统中没有共享资源,每个节点都拥有自己的存储和计算资源,独立地执行任务。尽管这种架构在某些场景下提供了良好的扩展性和容错性,但它在云环境中的局限性逐渐显现:
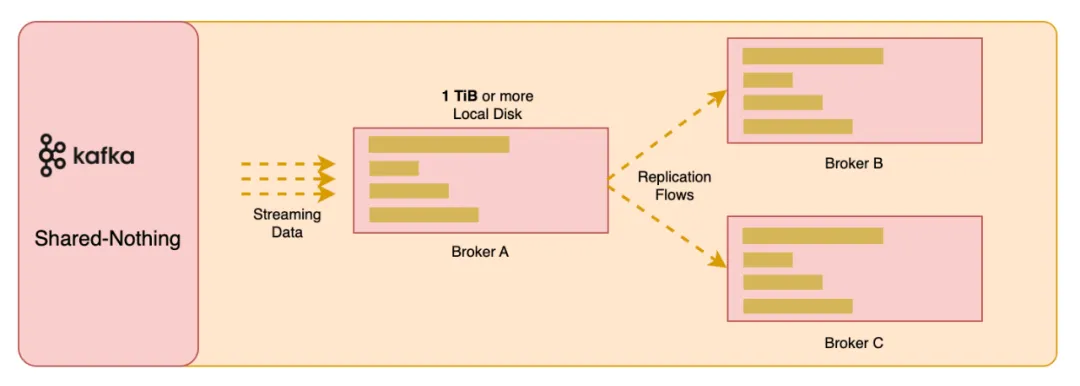
存储成本问题:本地磁盘存储成本高昂,尤其是当考虑到采用三副本时。根据参考资料 [1] 可知,以 EBS GP3 卷为例,尽管单价为 $0.08/GiB/ 月,当 Kafka 使用三副本时,实际成本上升至 $0.24/GiB。若预留 50% 的存储空间以应对数据增长和灾难恢复,总成本翻倍至 $0.48/GiB。这种成本结构对于长期存储大量数据的系统来说是不可持续的。我们也遇到很多客户会将 Kafka 用于长期存储历史数据,并且在必要的时候可以用于回放数据。这种应用场景下,由此引发的成本问题将会愈发显著。
运维复杂性**:**Shared Nothing 架构虽然为 Kafka 提供了分布式处理的能力,但在运维实践中却带来了显著的复杂性。这种架构要求每个节点独立管理自己的存储,使得作为计算节点的 Broker 强耦合本地存储,由此引发了一系列问题。水平扩展 Kafka Broker 时,分区数据迁移是一个资源密集型的过程。在分区迁移的过程中,会大量占用网络带宽和磁盘 I/O 从而影响正常的读写。如果有大量的分区数据,这一过程将会持续数小时甚至数天 [2],严重影响 Kafka 集群整体的可用性。
性能瓶颈:Kafka 的本地磁盘 I/O 限制在处理历史数据的冷读操作时尤为明显 [3][4]。由于本地磁盘的 I/O 吞吐量有限,当系统需要从磁盘读取大量历史数据时,会与处理实时数据流的 I/O 操作发生冲突。这种资源争用不仅降低了系统的响应速度,还可能导致服务延迟,影响到整体的数据处理性能。例如,在使用 Kafka 进行日志分析或数据回放时,冷读操作的高延迟会直接影响到分析结果的实时性 [14]。
缺乏弹性:Shared Nothing 架构的 Kafka 集群在弹性伸缩方面存在不足。每个 Broker 节点强耦合本地磁盘,这种设计限制了集群对动态工作负载的适应能力以及完成自动弹性 [5]。当数据流量突增时,由于没法快速完成分区数据的迁移,Kafka 集群难以快速扩展资源以应对需求,同样,在负载减少时也难以及时缩减资源,这导致了资源利用率低下和成本浪费。用户无法利用公有云的资源共享、随用随还的特性,只能重新回归传统 IDC 机房预留资源的做法,导致闲置资源浪费。即使由人完成水平扩缩容,由于涉及分区数据的复制,这仍然是一个高危操作。由于缺乏弹性,没法快速对集群做 Scale In/Out,因此也就无法做到真正的 pay-as-you-go,云上 Spot 实例的应用和真正的 Serverless 也无从谈起。

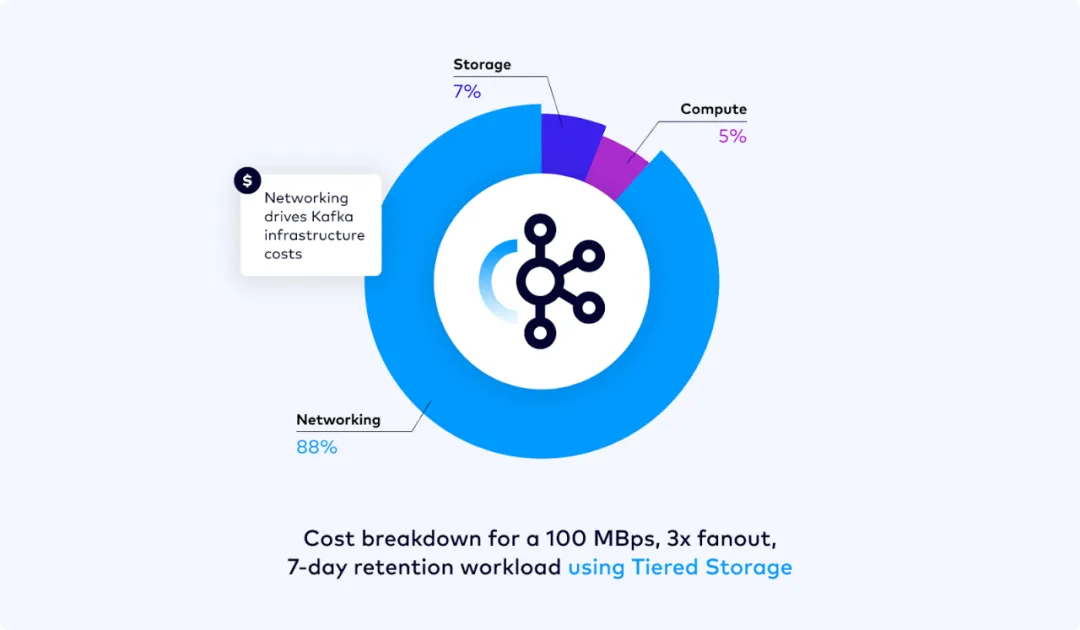
- 多 AZ 网络流量成本:云厂商对于用户在多个 AZ 之间进行网络传输会收取大量的费用,在 Confluent 的博客中对 Kafka 的成本进行分析发现网络成本的占比可达 80% 以上 [6]。如果部署一个支持多 AZ 容灾、三副本的 Kafka 集群,基于本地磁盘的 Shared Nothing 架构在客户端对 Kafka 集群进行读写以及扩缩容时,由于分区数据的跨 AZ 数据复制,将产生大量的网络 I/O 及由此引发的成本支出,是一种非常不经济的做法。
03
分层存储无法拯救 Kafka
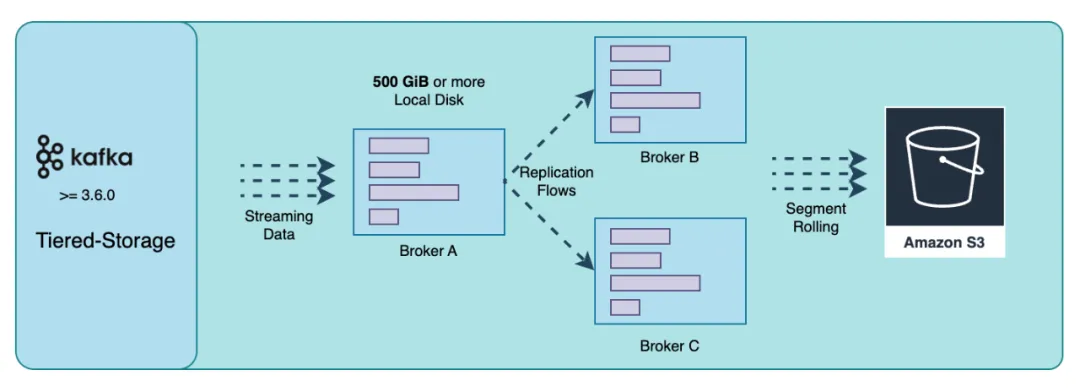
分层存储(Tiered Storage)的概念在 Apache Kafka 社区中已经讨论多年,但直到 3.7 版本,Kafka 本身仍未提供成熟的生产级分层存储能力。尽管如此,一些 Kafka 供应商,如 Confluent 和 Aiven,已经推出了自己的分层存储解决方案。这些方案利用了对象存储的低成本优势,将旧数据从昂贵的本地磁盘迁移到对象存储中,以期减少长期存储的成本。然而,这些分层存储方案的尝试并没有彻底解决 Kafka 面临的一些核心痛点问题:
多 AZ 之间的网络流量费用问题:Tiered Storage 本质还是基于 Kafka 本地存储日志的方案,Broker 和 Local Disk 之间的关系并没有变化。通过将一些历史数据转移到了 S3,降低了成本和分区数据复制的数据量,仍然是治标不治本的方案。Kafka 分层存储的实现要求分区最后的一个 Log Segment 仍然必须在本地磁盘上,因此在 Tiered Storage 方案中,Broker 仍然是有状态的。当分区的最后一个日志段数据量很大时,仍然不可避免地在水平扩缩容时需要大量的分区数据复制。
运维复杂性:尽管采用了分层存储,但 Kafka 的运维复杂性不但没有得到简化,反而在原来的架构上又引入了对象存储带来的额外复杂度。采用分层存储并没有真正将 Broker 从 Local Disk 中解耦出来。扩缩容和分区迁移过程中的数据迁移仍是复杂且容易出错的任务。例如 Confluent 的 Dedicated 集群即使使用了分层存储,在扩缩容时仍然会耗费数个小时甚至更久的时间 [7]。
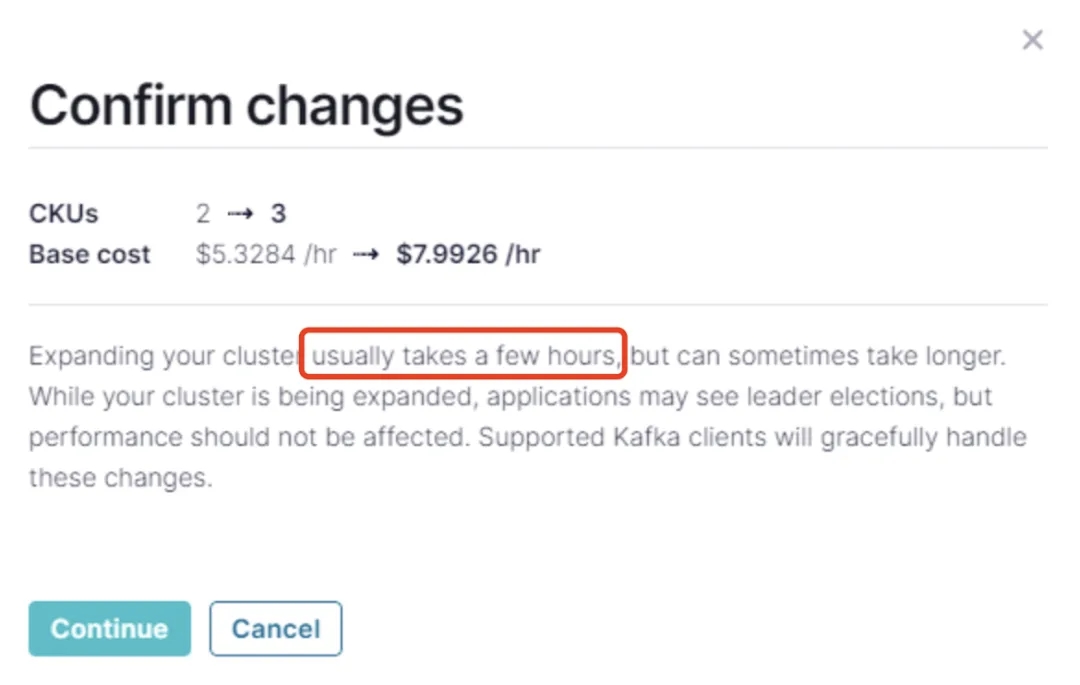
- 高昂的基础设施成本:正如前文提到的,即使采用分层存储,你仍然可能在本地磁盘上保有大量的数据。而很多时候,Workload 是很难预测的。为了保证峰值吞吐时能够正常工作,用户仍然需要预留大量的本地磁盘空间(在云上即是云盘)。由于云盘 [1] 高昂的成本,这将大大提升存储的成本。
通过以上分析我们可以知道,分层存储虽然一定程度上解决了历史数据的存储成本问题,以及降低了一些情况下分区数据迁移的数据量,但是其仍然没有从根本上解决 Kafka 的痛点。过去基于 Local Disk 的 Shared Nothing 架构所存在的存储成本、弹性等问题依然存在。
04
直接写 S3 也无法拯救 Kafka

尽管将数据直接写入 S3 的对象存储是一个吸引人的解决方案 [6] ,但它并不是解决 Kafka 问题的万能钥匙。这种方法虽然可以解决 Shared Nothing 架构上的弹性和成本问题,但是它牺牲了延迟。如果我们可以有一个兼顾延迟和弹性的方案,为什么我需要妥协呢?对于流系统而言,延迟是十分重要的 [8]。对于诸如金融交易、在线游戏、流媒体等场景,延迟是十分重要且不可妥协的指标。延迟直接与用户的使用体验、数据处理效率、企业的商业竞争力息息相关。放弃延迟将使得流系统丧失关键的应用场景,这也与 Kafka 设计时追求低延迟的初衷相违背。
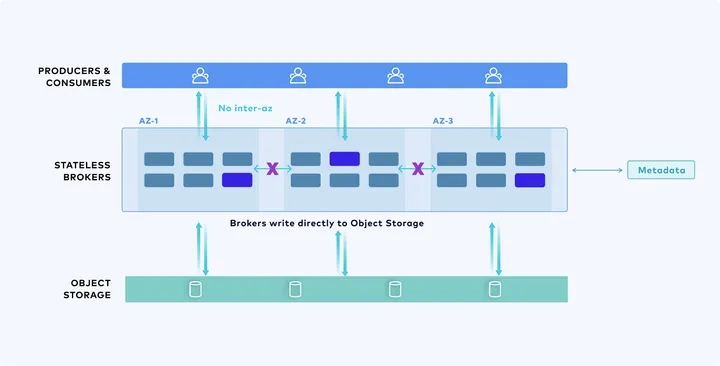
直接写对象存储虽然解决了 Kafka 有状态 Broker 引发的一系列诸如弹性、跨 AZ 网络费用等诸多问题,但这显然不是 Shared Storage 架构上最优的存储方案。一般而言,直接写 S3 将会导致 600ms 以上的 [9] 延迟,这在很多实时性场景都是不可接受的。在设计系统时,我们需要确保高频使用路径具有最低的延迟和最优的性能。在 Kafka 的使用场景中,读取热数据是一个高频路径,我们需要确保其拥有最低的延迟和最优的性能。当前,仍然有大量客户使用 Kafka 来替代传统的消息队列系统,如 RabbitMQ。这些应用场景对延迟都有极高的敏感度,百毫秒级的延迟可能会导致消息处理产生不可接受的延迟,从而影响业务流程和用户体验。虽然直接写入 S3 在某些场景下可能提供了一种成本效益高的存储解决方案,但它并没有解决 Kafka 在高频数据处理路径上的低延迟需求。为了保持 Kafka 作为流处理平台的竞争力,必须在设计中平衡成本和性能,特别是在高频数据路径上,以确保用户体验和系统性能不受影响。因此,寻找一种既能降低成本、提升 Kafka 弹性能力又能保持低延迟的存储方案成为了我们对 Kafka 创新的重要目标。
05
共享存储上的创新
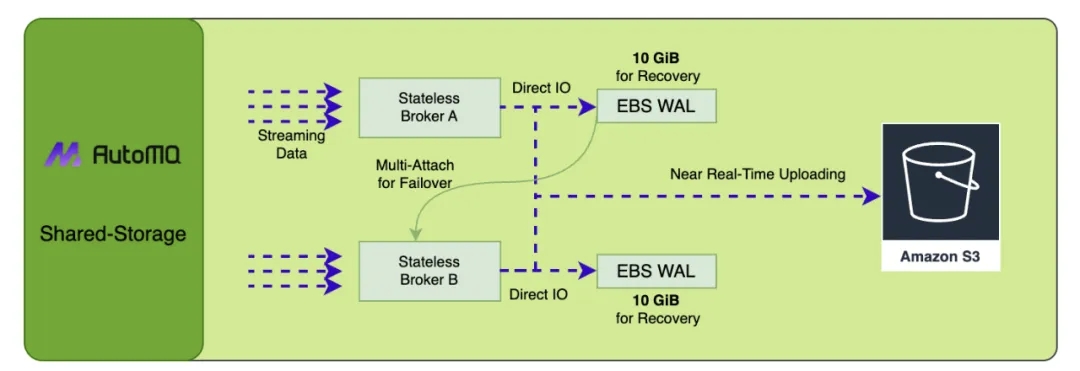
我们的项目 AutoMQ[10] 通过合理利用一小块 EBS 盘作为 WAL 来配合 S3 提供了一种创新的共享存储架构。这种存储架构不仅享有直接写 S3 所拥有的全部优点,即优秀的弹性、没有 AZ 间数据复制、低成本,同时还不会牺牲延迟。上图揭示了这种存储架构的实现细节。当 WAL 数据通过 Direct IO 持久化成功后,消费者可以立即从内存 Cache 中读取已经持久化的流数据。由于只是将近期的 WAL 数据存储到 EBS 上,历史数据仍然是从 S3 进行读取,所以在这种存储架构只需要一块非常小的 EBS(通常是 10GB),EBS 的存储成本在总体存储成本的占比中是微乎其微的。而当 Broker 计算节点崩溃时,可以通过多重挂载技术在毫秒级内重新挂载 EBS 卷,将 EBS 上的 WAL 数据进行恢复。

EBS + S3 ≠ Tiered Storage
如果不仔细了解我们存储架构的优势,很容易将这种创新的共享存储架构与 Tiered Storage 弄混。分层存储中的 Broker 本质上仍然是一个有状态的 Broker,其强耦合本地磁盘。而我们的 Shared Storage 架构中 Broker 与 EBS 实际上是解耦的。当计算节点崩溃时,利用 EBS 多重挂载 [11] 和 NVME reservations[12] 能力,可以在毫秒级完成故障转移与恢复。AutoMQ 的 Shared Storage 存储架构将 EBS 视为共享存储来设计。EBS 卷可以在 EC2 故障时,通过多重挂载技术快速挂载至其他节点,以业务无感的方式继续提供读写服务。从这个角度来看,EBS 跟 S3 一样都是共享存储,而非有状态的本地磁盘。对于 EBS 来说,其与 Broker 完全解耦,因此在 AutoMQ 中,Broker 是无状态的。EBS 与 S3 本质都是云提供的存储服务,通过充分利用云存储的特性,我们可以在 Broker 之间无缝地共享 EBS 卷,形成我们创新的 Shared Storage 架构。
EBS 是云服务而不仅仅是一个物理卷
我们一直在努力构建下一代真正云原生的流系统,其可以充分挖掘出公有云服务的全部潜力。一个真正的云原生系统很关键的特征就是将公有云上具有规模化和技术红利的云服务的充分利用起来。这其中的关键是我们需要从过去传统面向硬件的软件思维转变为面向云服务设计。EBS 云服务本质是一个分布式存储,底层不仅实现了类似于 HDFS、Bookekeeper 等系统的多副本技术,同时由于其云上大规模应用,具有较低的边际成本,因此公有云厂商在其上投入了大量产研成本。例如 Alibaba Cloud 在云存储上已经累计投资了十多年来优化存储技术,有 1500W 行以上的 C++ 代码来支持这些进步;AWS 也利用 Nitro Card[13] 这种软硬一体化技术甚至重写了适用于局域网的网络协议烧录在硬件中从而为云存储提供高持久性、可靠性、低延迟的云存储服务。认为云存储仍然不如本地磁盘可靠或者存在延迟问题,已经是一种落伍的观念。当前主流云厂商提供的云盘服务都是足够成熟的,站在巨人的肩膀上而不是重复其造轮子,可以更好地赋能云原生软件的创新。
如何解决 EBS 昂贵的问题
文章[1]对比了一个 3 副本的 Kafka 集群在 S3 与 EBS 单位 GB 的存储成本可以相差 24 倍。如果用户拥有规模较大的集群且需要对数据进行较长时间的保留,EBS 的存储成本将会在 Kafka 集群整体 TCO 中占有非常大的比重。对云存储介质的不合理使用会导致存储成本的急剧上升。EBS 与 S3 是完全面向两种不同读写场景设计的云存储服务。EBS 用于低延迟、高 IOPS 的读写场景;S3 则用于冷数据低成本存储、吞吐优先、延迟不敏感的读写场景。结合不同云存储服务的特征,因地制宜地使用他们才可以在兼顾性能、可用性的同时具有最佳的成本效益。我们的 Shared Storage 存储架构设计在遵循“高频使用路径需要具有最低的延迟和最优性能”的设计原则基础上,充分考虑了 EBS 和 S3 的存储特性差异,巧妙地结合了两种存储的优势特性,提供了低延迟、高吞吐、低成本和容量“无限”的的流存储能力。Kafka 写入最新的热数据并且被消费者立即读取是一个高频读写路径,利用 EBS 本身的持久性、低延迟、虚拟存储(可以申请非常小的一块空间)的特性,结合 Direct I/O 等工程技术手段,数据以极低的延迟完成持久化。当完成持久化以后,消费者即可从内存 Cache 中读取已经被持久化的数据完成整个读写流程,在高频读写路径上提供了个位数毫秒级的延迟。由于只是将 EBS 作为 WAL 用于 Recovery,我们只需要 5~10GB 左右的 EBS 存储空间。以 10GB 的 AWS GP3 存储卷为例,每个月(30)天的存储成本仅为 0.8 美元。这样,我们不仅充分利用了 EBS 持久化、低延迟的特性,同时解决了直接写 S3 方案所拥有的延迟问题。
如何解决 AWS EBS 无法多可用区容灾的问题
在公有云中,AWS EBS 是较为特殊的,因为其不像其他云厂商一样提供 Regional EBS。Azure[17]、GCP[16] 以及 Alibaba Cloud(据悉2024年6月推出)都推出了 Regional EBS。在这些云上,我们的 Shared Storage 存储方案都可以无缝衔接 Regional EBS 提供 AZ 级的容灾,充分兑现云存储服务的技术红利。而在 AWS EBS 上,我们通过双写分别处于不同 AZ 的 EBS 以及 S3 Express One Zone 来支持 AZ 级别的容灾。
06
总结
随着云计算和云原生理念的发展,Kafka 确实面临着巨大的挑战,但是 Kafka 不会死 [15] ,他会继续保持成长和发展。而我们也相信,共享存储架构也一定会为 Kafka 生态注入新的活力,引领 Kafka 真正进入云原生时代。
参考资料
[1] Cloud Disks are (Really!) Expensive: https://www.warpstream.com/blog/cloud-disks-are-expensive
[2] Making Apache Kafka Serverless: Lessons From Confluent Cloud: https://www.confluent.io/blog/designing-an-elastic-apache-Kafka-for-the-cloud/#self-balancing-clusters
[3] How AutoMQ addresses the disk read side effects in Apache Kafka: https://www.automq.com/blog/how-automq-addresses-the-disk-read-side-effects-in-apache-Kafka
[4] Broker performance degradation caused by call of sendfile reading disk in network thread:https://issues.apache.org/jira/browse/Kafka-7504
[5] Is there anyway to activate auto scaling or some form of auto scaling with Strimzi? : https://github.com/orgs/strimzi/discussions/6635
[6] Introducing Confluent Cloud Freight Clusters: https://www.confluent.io/blog/introducing-confluent-cloud-freight-clusters/
[7] Resize a Dedicated Kafka Cluster in Confluent Cloud: https://docs.confluent.io/cloud/current/clusters/resize.html
[8] Why is low latency important?:https://redpanda.com/guides/Kafka-performance/Kafka-latency
[9] Public Benchmarks and TCO Analysis: https://www.warpstream.com/blog/warpstream-benchmarks-and-tco
[10] AutoMQ: https://github.com/AutoMQ/automq
[11] AWS EBS Multi-Attach: https://docs.aws.amazon.com/ebs/latest/userguide/ebs-volumes-multi.html
[12] NVME reservations: https://docs.aws.amazon.com/ebs/latest/userguide/nvme-reservations.html
[13] Nitro card for Amazon EBS: https://d1.awsstatic.com/events/Summits/reinvent2023/STG210_Behind-the-scenes-of-Amazon-EBS-innovation-and-operational-excellence.pdf
[14] How AutoMQ addresses the disk read side effects in Apache Kafka: https://www.automq.com/blog/how-automq-addresses-the-disk-read-side-effects-in-apache-Kafka
[15] Kafka is dead, long live Kafka: https://www.warpstream.com/blog/Kafka-is-dead-long-live-Kafka
[16] GCP Regional Persistent Disk: https://cloud.google.com/compute/docs/disks/high-availability-regional-persistent-disk
[17] Azure ZRS Disk: https://learn.microsoft.com/en-us/azure/virtual-machines/disks-deploy-zrs\?tabs=portal
END
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
关注我们,一起学习更多云原生技术干货!