本文来源公众号“算法金”,仅用于学术分享,侵权删,干货满满。
原文链接:Xorbits,一个超强的 Python 库
1 Xorbits 库介绍
在数据科学和机器学习的世界里,处理大规模数据集和复杂计算的需求日益增长。
这就需要一个既能简化开发流程又能轻松扩展的工具。
今天,我们来聊聊 Xorbits ——一个为数据科学和机器学习领域量身打造的 Python 库。
https://github.com/xorbitsai/xorbits

1.1 Xorbits 简介
Xorbits 是一个开源计算框架,旨在简化数据科学和机器学习工作负载的扩展——从数据预处理到调优、训练和模型服务。
无论是在单机上利用多核心或GPU加速计算,还是扩展到数千台机器支持处理TB级数据和训练或服务大型模型,Xorbits 都能胜任。
Xorbits 提供了一套最佳的库,供数据科学家和机器学习从业者使用。
它能够在不需要深入了解基础设施的情况下扩展任务。
1.2 为什么选择 Xorbits?
-
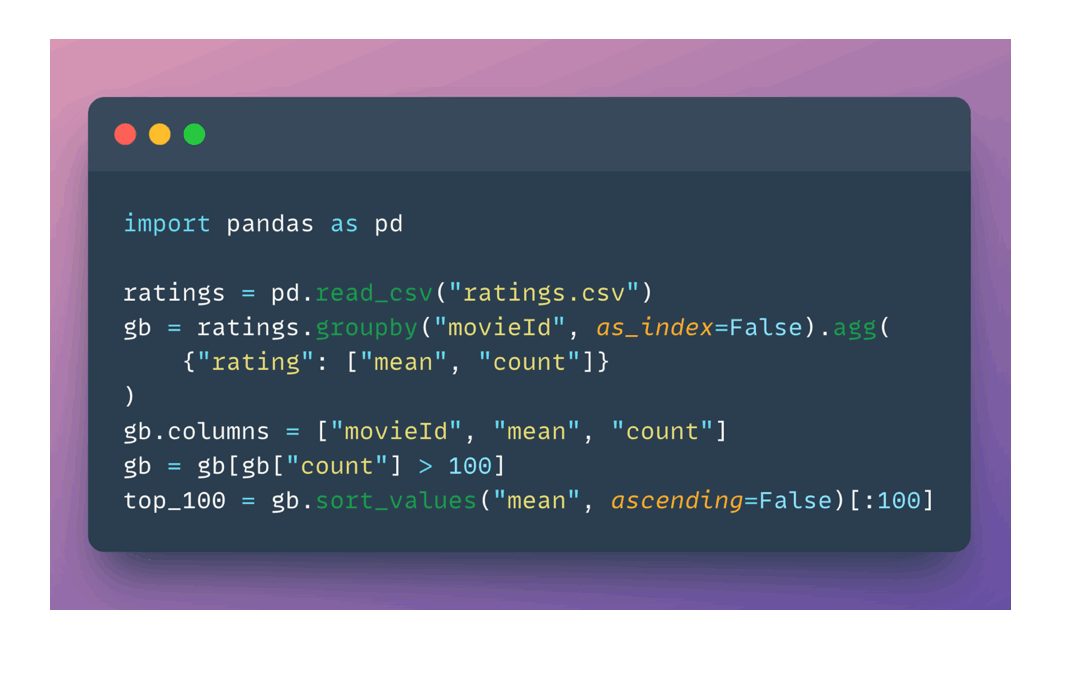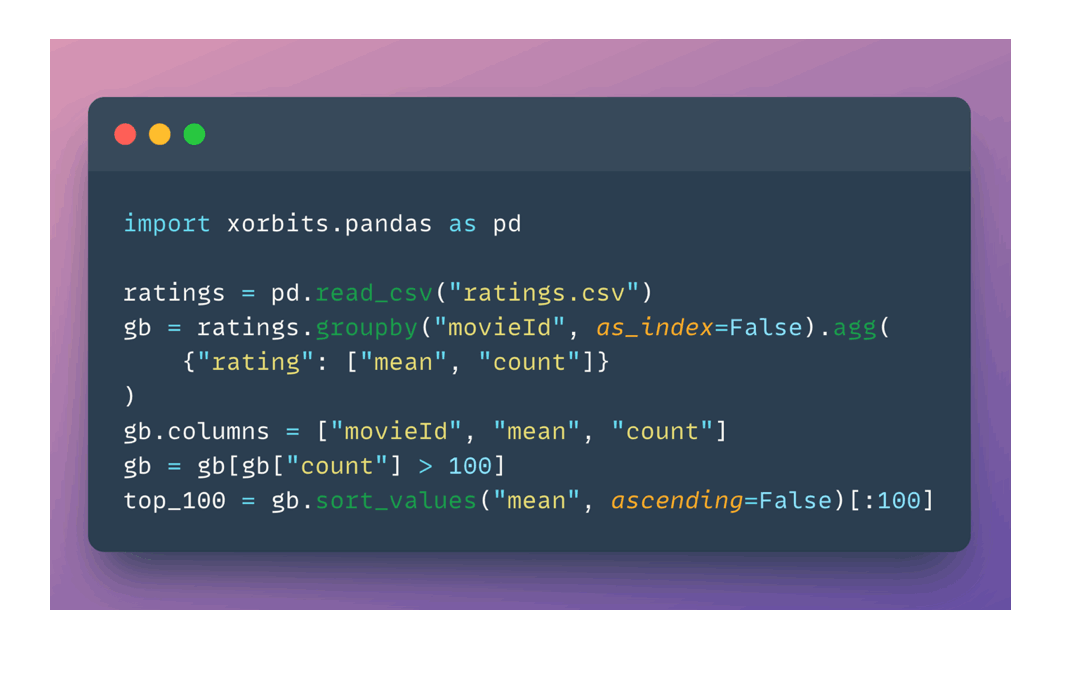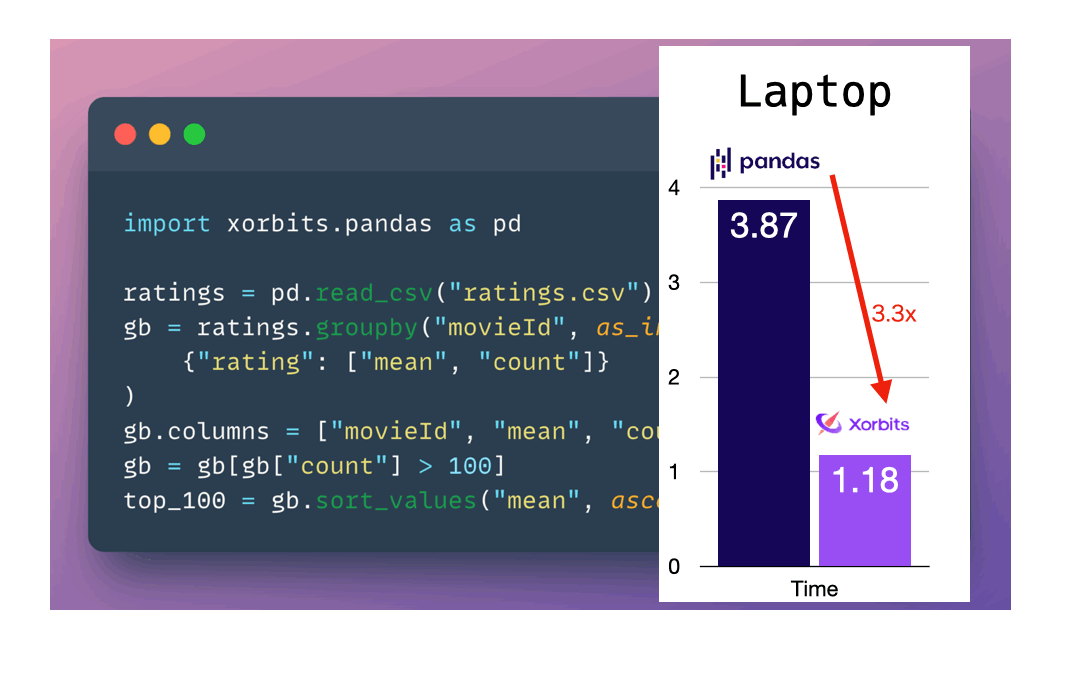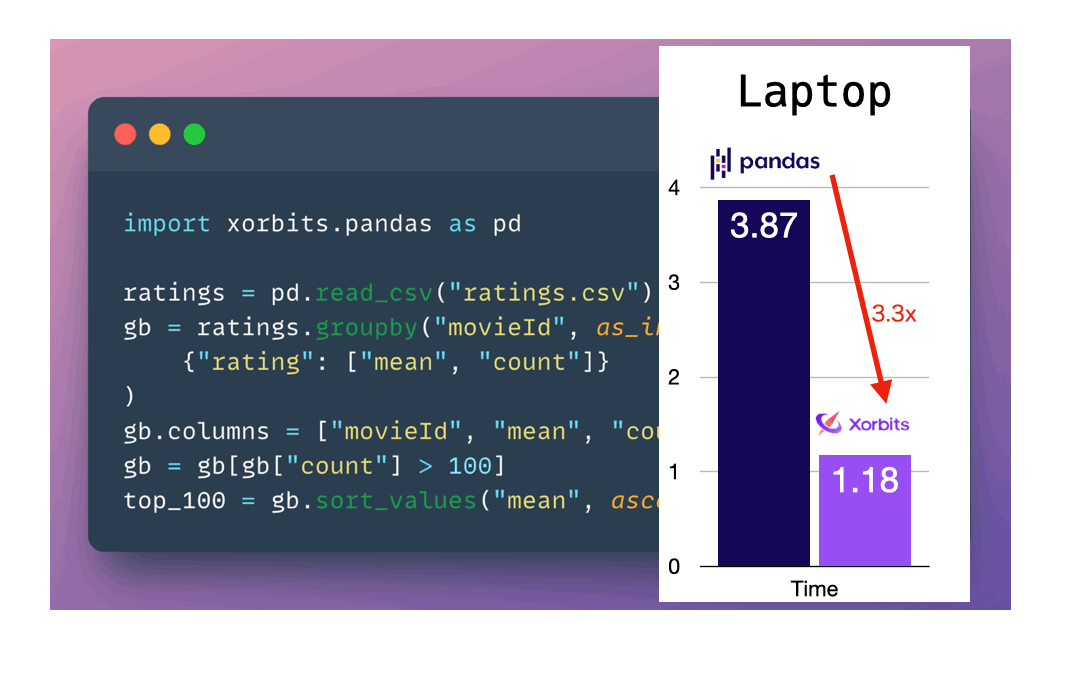
无缝扩展工作流:使用 Xorbits,你不需要指定如何分配数据,甚至不需要知道系统有多少核心。你可以继续使用现有的笔记本电脑,并且即使在笔记本电脑上也能从 Xorbits 获得显著的速度提升。
-
处理大数据集:Xorbits 能够利用你所有的计算核心。这对于处理大型数据集特别有益,这些数据集可能会导致 pandas 变慢或内存不足。
-
闪电般的速度:根据我们的基准测试,Xorbits 在速度和可扩展性方面超越了其他流行的 pandas API 框架。
-
利用 Python 生态系统:Xorbits 旨在充分利用整个 ML 生态系统,提供与 pandas 等库的原生集成。
1.3 Xorbits的特点
-
API兼容性:Xorbits 提供了一个熟悉的 Python API,支持多种库,包括 pandas、NumPy、PyTorch、XGBoost 等。通过仅修改一行代码,你的 pandas 工作流就可以无缝地使用 Xorbits 进行扩展。
-
轻松处理大规模数据集:Xorbits 可以扩展到数千台机器,支持处理 TB级数据和训练或服务大型模型,无需深入了解底层基础设施。
-
闪电般的速度:Xorbits 在速度和可扩展性方面的表现超越了其他流行框架,使其成为处理大规模数据科学和机器学习工作负载的理想选择。
2 快速开始
2.1 安装 Xorbits
开始之前,你需要确保 Xorbits 正确安装在你的系统上。
pip install xorbits
2.2 使用 Xorbits 处理数据集
Xorbits 让处理大型数据集变得简单。
如果你熟悉 pandas,那么使用 Xorbits 会感觉非常自然。
以下是一个简单的例子,展示了如何使用 Xorbits 来加载和处理数据集:
import xorbits.pandas as xpd# 加载数据集
data = xpd.read_csv('your_dataset.csv')# 进行数据处理
data['new_column'] = data['existing_column'] + 10# 显示处理后的数据
print(data.head())
这个例子展示了如何使用 Xorbits 的 pandas 接口来读取CSV文件,进行简单的数据处理,并打印结果。
这与传统的 pandas 用法非常相似,但背后的计算却可以自动扩展到多核心或整个集群。
2.3 扩展机器学习工作负载
Xorbits 的强大之处在于其能够无缝扩展机器学习工作负载。
无论是数据预处理、模型训练还是模型服务,Xorbits 都能提供必要的速度和灵活性。
2.4 部署 Xorbits 集群
对于需要在云端或大型集群上部署模型的高级用户,Xorbits 提供了详细的指南来帮助你部署 Xorbits 集群。
这使得在更大规模上运行数据科学和机器学习工作负载成为可能。
3 效果图
3.1 性能对比
将 Xorbits 与 Dask、Spark 上的 Pandas API 在 ~100 GB 数据集性能对比
Xorbits 与 Dask
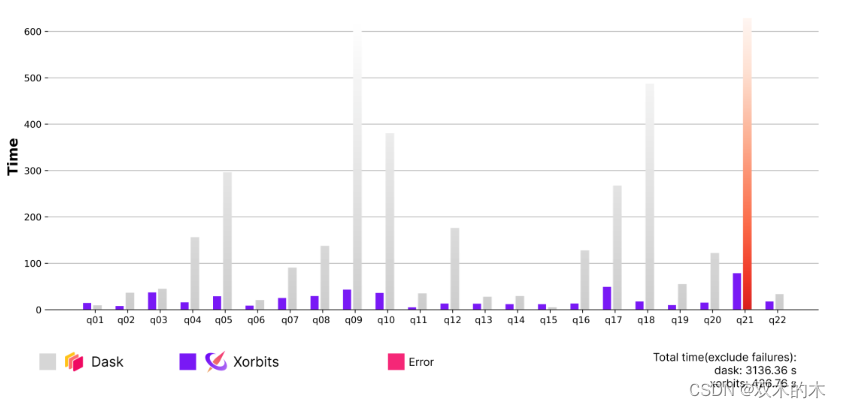
Dask 是一个著名的“类似 Pandas”的框架,用于扩展 Python 工作负载。下图说明了 TPC-H 查询的 Xorbits 和 Dask 的计算时间(不包括 I/O)。
Q21 被排除在外,因为 Dask 内存不足。在所有查询中,发现 Xorbits 比 Dask 快 7.3 倍。
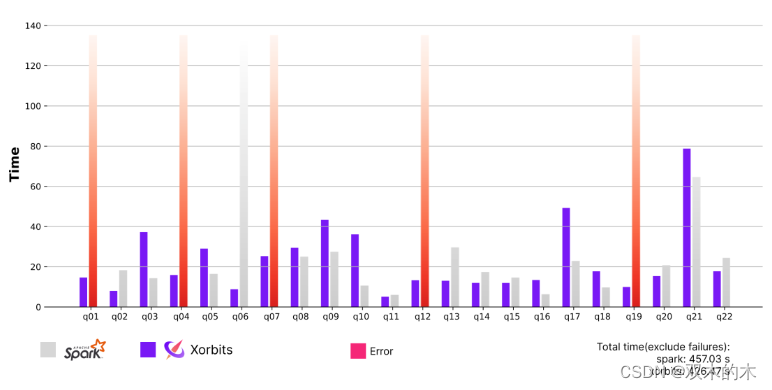
Spark 上的 Xorbits 与 Pandas API
Spark 是一个众所周知的框架,用于快速、大规模的数据处理。
下图说明了 TPC-H 查询(不包括 I/O)的 Xorbits 和 Spark Pandas API 的计算时间。
在所有查询中,这两个系统的性能大致相似,但 Xorbits 提供了更好的 API 兼容性。
Spark Pandas API 在 Q1、Q4、Q7、Q21 上失败,并在 Q20 上耗尽内存。
4 实例
4.1 使用 Xorbits 处理搜索相似文本的嵌入向量
ChatGPT、Midjourney 和 Copilot 等 AI 工具的出现清楚地表明了 AI 程序和服务在各个领域的巨大潜力。
但是,一台从根本上只理解二进制代码(0 和 1)的机器,怎么会拥有如此广泛的知识,尽管它有相当多的缺陷?
答案在于我们人类向这些机器提供信息的方式。尽管机器缺乏人类感知世界的能力,但它们可以处理和理解我们以数字向量形式提供的数据。
这就是嵌入发挥作用的地方。
嵌入本质上是将实体(如单词)描述为多维环境中的向量。换句话说,它是一个数字序列,[.89, .65, .45, ...]这使我们能够以各种方式解释它们,例如通过在多维空间中评估它们的相似性。
在后续步骤中,我们将使用 Xorbits 从文章中生成向量嵌入。数据集包含来自 27 家美国出版物的 2,688,878 篇新闻文章和论文,时间跨度从 2016 年 1 月 1 日到 2020 年 4 月 2 日。
https://components.one/datasets/all-the-news-2-news-articles-dataset/
from sentence_transformers import SentenceTransformer # 导入句子转换器库,用于文本向量化
import xorbits.pandas as pd # 导入pandas库,但是使用xorbits的版本,用于数据处理
import re # 导入正则表达式库,用于文本处理
import torch # 导入PyTorch库,用于深度学习操作# 如果GPU可用,则设置设备为GPU,否则使用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 初始化句子转换模型,并设置使用的设备
model = SentenceTransformer('average_word_embeddings_komninos', device=device)def prepare_data(data) -> pd.DataFrame:'对数据进行预处理并准备好进行插入操作。'# 添加一个id列print("Preparing data...")data["id"] = range(len(data)) # 为数据集每一行分配一个唯一的ID# 为了加快向量计算,仅提取每篇文章的前几句话# 我们对生成data['article']的方式进行了一点优化# 原始版本:# data['article'] = data.article.apply(lambda x: ' '.join(re.split(r'(?<=[.:;])\s', x)[:4]))# 优化后的版本:def helper(x):count = 0idx = -1x = str(x)for match in re.finditer(r'(?<=[.:;])\s', x):count += 1if count == 4:idx = match.start() if match.start() != match.end() else match.start() + 1breakreturn x[:idx]data['article'] = data['article'].fillna('') # 填充空值data['article1'] = data.article.apply(helper) # 应用优化后的文章截取方法s2 = data['title'].str.cat(list(data['article1']), sep="") # 将标题和处理后的文章内容拼接print('Encoding articles...')# 对文章进行编码,将文本转换为向量encoded_articles = s2.apply(lambda x : list(map(float, model.encode(x))))data['article_vector'] = encoded_articles # 将编码后的文章向量存储起来return data# 由于使用完整数据集可能需要更多时间,因此仅使用数据集的一部分
data = pd.read_csv('all-the-news-2-1.csv', nrows=200000) # 读取CSV文件中的前200000行数据
prepared_data = prepare_data(data) # 调用prepare_data函数处理数据
这段代码主要包括数据预处理和使用句子转换器模型对文章进行编码的过程。
-
首先,它通过添加一个唯一的ID列来准备数据。
-
然后,为了加快处理速度,它仅提取每篇文章的前几句话进行后续的向量化处理。
-
接着,它使用
SentenceTransformer模型将处理后的文本转换为向量形式,以便进行进一步的分析或机器学习任务。 -
最后,这些步骤被应用于一个较大的新闻数据集的子集。
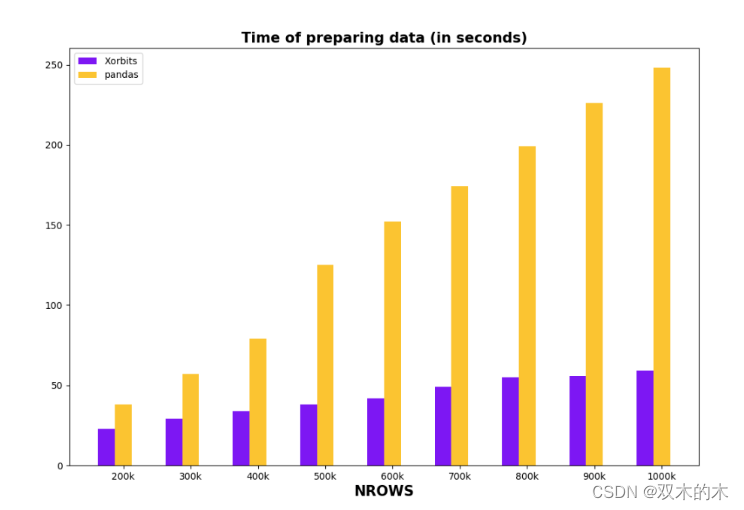
在下面的比较中,我们将评估 Xorbits 和 Pandas 在读取 CSV 文件、处理文本和创建嵌入方面的性能。
下图说明了具有不同行计数(越低越好)的数据框之间的这些比较。
很明显,Xorbits 在数据预处理速度方面比 Pandas 具有明显的优势,尤其是在处理超过 500k 行的数据帧时。
之后,我们可以利用 Pinecone 来存储这些嵌入并检索结果,Pinecone 是一个专门设计用于存储和查询高维向量的向量数据库。
5 总结
Xorbits 为数据科学和机器学习领域的专业人士提供了一个强大、灵活且易于使用的工具,使他们能够轻松扩展其工作流程以满足不断增长的计算需求。
无论你是在处理大型数据集,还是需要在多个核心或机器上加速计算,Xorbits 都能提供所需的速度和灵活性。
现在就开始探索 Xorbits,将你的数据科学和机器学习项目提升到新的高度,冲!
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。