一,背景
二:常见方法介绍
2.1 UUID
UUID(Universally Unique Identifier)的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符,示例:550e8400-e29b-41d4-a716-446655440000。
2.1.1 优点
性能非常高:本地生成,没有网络消耗。
2.1.2 缺点
不易于存储:UUID 太长,16 字节 128 位,通常以 36 长度的字符串表示,很多场景不适用。
信息不安全:基于 MAC 地址生成 UUID 的算法可能会造成 MAC 地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
ID 作为主键时在特定的环境会存在一些问题,比如做 DB 主键的场景下,UUID就非常不适用:
① MySQL 官方有明确的建议主键要尽量越短越好[4],36 个字符长度的 UUID不符合要求。
② 对 MySQL 索引不利:如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能。在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS 使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
可以直接使用 jdk 自带的 UUID,原始生成的是带中划线的,如果不需要,可自行去除,例如下面代码:
public static void main(String[] args) {for (int i = 0; i < 5; i++) {String rawUUID = UUID.randomUUID().toString();//去除“-”String uuid = rawUUID.replaceAll("-", "");System.out.println(uuid);}}2.2 雪花算法及其衍生
这种方案大致来说是一种以划分命名空间(UUID 也算,由于比较常见,所以单独分析)来生成 ID 的一种算法,Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 把 64-bit 分别划分成多段,分开来标示机器、时间等,比如在 snowflake 中的 64-bit 分别表示如下图所示:
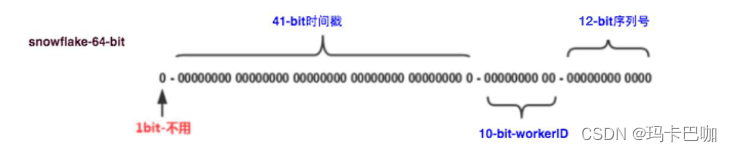
第 0 位: 符号位(标识正负),始终为 0,没有用,不用管。第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41毫秒(约 69 年)
第 42~52 位 :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整),这样就可以区分不同集群/机房的节点,这样就可以表示 32 个 IDC,每个 IDC 下可以有 32 台机器。
第 53~64 位 :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
理论上 snowflake 方案的 QPS 约为 409.6w/s,这种分配方式可以保证在任何一个 IDC 的任何一台机器在任意毫秒内生成的 ID 都是不同的。
三 分布式 ID 微服务
从上面的分析可以看出,每种方案都各有优劣,我们现在参考美团 Leaf 方案实现自己的分布式Id。
3.1 美团 Leaf 方案实现
原 MySQL 方案每次获取 ID 都得读写一次数据库,造成数据库压力大。改为批量获取,每次获取一个 segment(step 决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
3.1.1 优点
Leaf 服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。ID 号码是趋势递增的 8byte 的 64 位数字,满足上述数据库存储的主键要求。
容灾性高:Leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 Leaf 仍能正常对外提供服务。
可以自定义 max_id 的大小,非常方便业务从原有的 ID 方式上迁移过来。
3.1.2 缺点
ID 号码不够随机,能够泄露发号数量的信息,不太安全。
TP999 数据波动大,当号段使用完之后还是会在获取新号段时在更新数据库的 I/O 依然会存在着等待,tg999 数据会出现偶尔的尖刺。
DB 宕机会造成整个系统不可用。
3.1.3 优化
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的 ID 下发时间取决于下一次从 DB 取回号段的时间,并且在这期间进来的请求也会因为 DB 号段没有取回来,导致线程阻塞。如果请求 DB 的网络和 DB 的性能稳定,这种情况对系统的影响是不大的,但是假如取 DB 的时候网络发生抖动,或者 DB 发生慢查询就会导致整个系统的响应时间变慢。
为此,希望 DB 取号段的过程能够做到无阻塞,不需要在 DB 取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的 TP999 指标。
采用双 buffer 的方式,Leaf 服务内部有两个号段缓存区 segment。当前号段已下发 10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment 接着下发,循环往复。通常推荐 segment 长度设置为服务高峰期发号 QPS 的 600 倍(10 分钟),这样即使 DB 宕机,Leaf 仍能持续发号 10-20 分钟不受影响。每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
四:分布式id实战
数据库配置
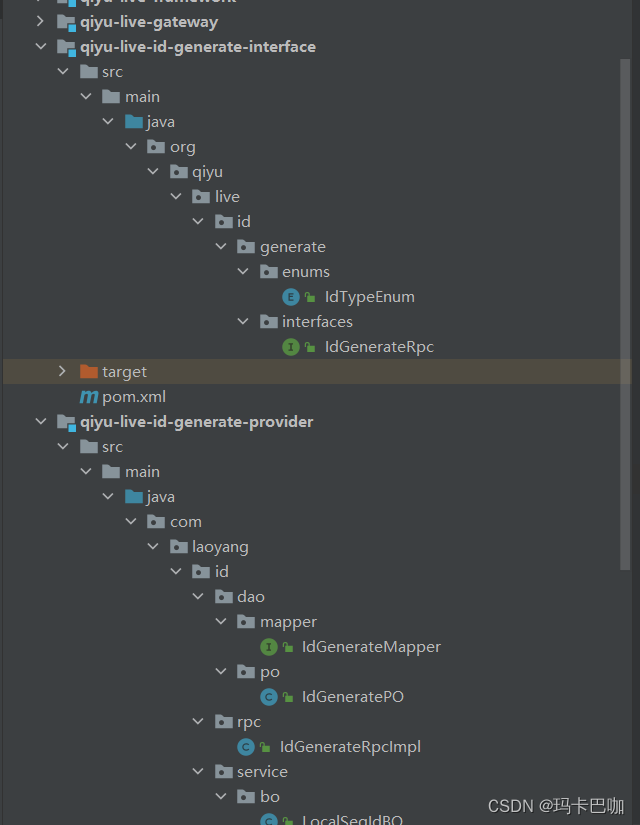
CREATE DATABASE qiyu_live_common CHARACTER set utf8mb3
COLLATE=utf8_bin;CREATE TABLE `t_id_generate_config` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键 id',`remark` varchar(255) CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci DEFAULT NULL COMMENT '描述',`next_threshold` bigint DEFAULT NULL COMMENT '当前 id 所在阶段的阈
值',`init_num` bigint DEFAULT NULL COMMENT '初始化值',`current_start` bigint DEFAULT NULL COMMENT '当前 id 所在阶段的开始
值',`step` int DEFAULT NULL COMMENT 'id 递增区间',`is_seq` tinyint DEFAULT NULL COMMENT '是否有序(0 无序,1 有序)',`id_prefix` varchar(60) CHARACTER SET utf8mb4 COLLATE
utf8mb4_unicode_ci DEFAULT NULL COMMENT '业务前缀码,如果没有则返回
时不携带',`version` int NOT NULL DEFAULT '0' COMMENT '乐观锁版本号',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时
间',`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE
CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_unicode_ci;插入记录
INSERT INTO `t_id_generate_config` (`id`, `remark`,
`next_threshold`, `init_num`, `current_start`, `step`, `is_seq`,
`id_prefix`, `version`, `create_time`, `update_time`)
VALUES(1, '用户 id 生成策略', 10050, 10000, 10000, 50, 0,
'user_id', 0, '2023-05-23 12:38:21', '2023-05-23 23:31:45');搭建springboot项目和配置文件
1.创建两个maven,并导入maven依赖
导入maven依赖
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version></dependency><dependency><groupId>org.apache.dubbo</groupId><artifactId>dubbo-spring-boot-starter</artifactId><version>${dubbo.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><artifactId>log4j-to-slf4j</artifactId><groupId>org.apache.logging.log4j</groupId></exclusion></exclusions></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${qiyu-mysql.version}</version></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>org.idea</groupId><artifactId>qiyu-live-id-generate-interface</artifactId><version>1.0-SNAPSHOT</version><scope>compile</scope></dependency>配置文件
spring:application:name: qiyu-live-id-generate-providerdatasource:driver-class-name: com.mysql.cj.jdbc.Driver# 访问主库url: jdbc:mysql://192.168.1.128:8808/qiyu_live_common?useUnicode=true&characterEncoding=utf8username: rootpassword: root在下面模块生成基本配置策略枚举和对外接口
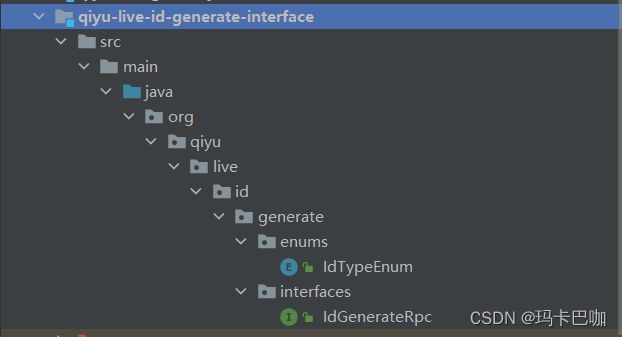
创建id生成策略枚举类
package org.qiyu.live.id.generate.enums;/*** @Author idea* @Date: Created in 17:55 2023/6/13* @Description*/
public enum IdTypeEnum {USER_ID(1,"用户id生成策略");int code;String desc;IdTypeEnum(int code, String desc) {this.code = code;this.desc = desc;}public int getCode() {return code;}public String getDesc() {return desc;}
}
生成对外接口方法
package org.qiyu.live.id.generate.interfaces;/*** @Author idea* @Date: Created in 19:45 2023/5/25* @Description*/
public interface IdGenerateRpc {/*** 获取有序id** @param id* @return*/Long getSeqId(Integer id);/*** 获取无序id** @param id* @return*/Long getUnSeqId(Integer id);}
接下来在id生成模块实现
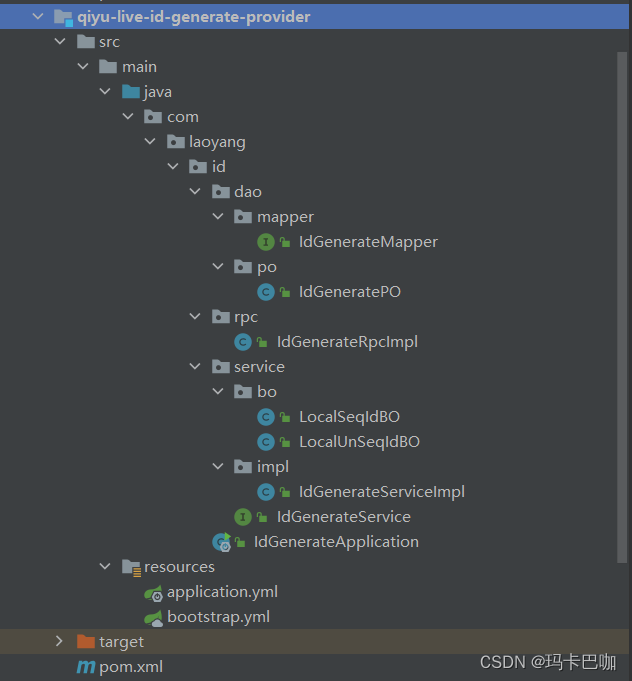
创建数据库po类(这里就是数据库id配置策略表)
package com.laoyang.id.dao.po;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;import java.util.Date;/*** @Author idea* @Date: Created in 19:59 2023/5/23* @Description*/
@TableName("t_id_gengrate_config")
public class IdGeneratePO {@TableId(type = IdType.AUTO)private Integer id;/*** id备注描述*/private String remark;/*** 初始化值*/private long initNum;/*** 步长*/private int step;/*** 是否是有序的id*/private int isSeq;/*** 当前id所在阶段的开始值*/private long currentStart;/*** 当前id所在阶段的阈值*/private long nextThreshold;/*** 业务代码前缀*/private String idPrefix;/*** 乐观锁版本号*/private int version;private Date createTime;private Date updateTime;public int getId() {return id;}public void setId(int id) {this.id = id;}public String getRemark() {return remark;}public void setRemark(String remark) {this.remark = remark;}public long getInitNum() {return initNum;}public void setInitNum(long initNum) {this.initNum = initNum;}public int getStep() {return step;}public void setStep(int step) {this.step = step;}public long getCurrentStart() {return currentStart;}public void setCurrentStart(long currentStart) {this.currentStart = currentStart;}public long getNextThreshold() {return nextThreshold;}public void setNextThreshold(long nextThreshold) {this.nextThreshold = nextThreshold;}public String getIdPrefix() {return idPrefix;}public void setIdPrefix(String idPrefix) {this.idPrefix = idPrefix;}public int getVersion() {return version;}public void setVersion(int version) {this.version = version;}public Date getCreateTime() {return createTime;}public void setCreateTime(Date createTime) {this.createTime = createTime;}public Date getUpdateTime() {return updateTime;}public void setUpdateTime(Date updateTime) {this.updateTime = updateTime;}public int getIsSeq() {return isSeq;}public void setIsSeq(int isSeq) {this.isSeq = isSeq;}@Overridepublic String toString() {return "IdGeneratePO{" +"id=" + id +", remark='" + remark + '\'' +", initNum=" + initNum +", step=" + step +", isSeq=" + isSeq +", currentStart=" + currentStart +", nextThreshold=" + nextThreshold +", idPrefix='" + idPrefix + '\'' +", version=" + version +", createTime=" + createTime +", updateTime=" + updateTime +'}';}
}生成mapper映射类,注意插入加入了乐观锁,注意这个sql
package com.laoyang.id.dao.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import com.laoyang.id.dao.po.IdGeneratePO;import java.util.List;/*** @Author idea* @Date: Created in 19:47 2023/5/25* @Description*/
@Mapper
public interface IdGenerateMapper extends BaseMapper<IdGeneratePO> {@Update("update t_id_gengrate_config set next_threshold=next_threshold+step," +"current_start=current_start+step,version=version+1 where id =#{id} and version=#{version}")int updateNewIdCountAndVersion(@Param("id")int id,@Param("version")int version);@Select("select * from t_id_gengrate_config")List<IdGeneratePO> selectAll();
}
在service下创建bo类生成有序id和无序id对象
package com.laoyang.id.service.bo;import java.util.concurrent.atomic.AtomicLong;/*** @Author idea* @Date: Created in 20:00 2023/5/25* @Description 有序id的BO对象*/
public class LocalSeqIdBO {private int id;/*** 在内存中记录的当前有序id的值*/private AtomicLong currentNum;/*** 当前id段的开始值*/private Long currentStart;/*** 当前id段的结束值*/private Long nextThreshold;public int getId() {return id;}public void setId(int id) {this.id = id;}public AtomicLong getCurrentNum() {return currentNum;}public void setCurrentNum(AtomicLong currentNum) {this.currentNum = currentNum;}public Long getCurrentStart() {return currentStart;}public void setCurrentStart(Long currentStart) {this.currentStart = currentStart;}public Long getNextThreshold() {return nextThreshold;}public void setNextThreshold(Long nextThreshold) {this.nextThreshold = nextThreshold;}
}
package com.laoyang.id.service.bo;import java.util.concurrent.ConcurrentLinkedQueue;/*** @Author idea* @Date: Created in 20:32 2023/5/26* @Description 无序id的BO对象*/
public class LocalUnSeqIdBO {private int id;/*** 提前将无序的id存放在这条队列中*/private ConcurrentLinkedQueue<Long> idQueue;/*** 当前id段的开始值*/private Long currentStart;/*** 当前id段的结束值*/private Long nextThreshold;public int getId() {return id;}public void setId(int id) {this.id = id;}public ConcurrentLinkedQueue<Long> getIdQueue() {return idQueue;}public void setIdQueue(ConcurrentLinkedQueue<Long> idQueue) {this.idQueue = idQueue;}public Long getCurrentStart() {return currentStart;}public void setCurrentStart(Long currentStart) {this.currentStart = currentStart;}public Long getNextThreshold() {return nextThreshold;}public void setNextThreshold(Long nextThreshold) {this.nextThreshold = nextThreshold;}
}
生成service类生成有序id与无序id
package com.laoyang.id.service;/*** @Author idea* @Date: Created in 19:58 2023/5/25* @Description*/
public interface IdGenerateService {/*** 获取有序id** @param id* @return*/Long getSeqId(Integer id);/*** 获取无序id** @param id* @return*/Long getUnSeqId(Integer id);
}
实现有序id和无序id方法(这里是关键,主要用到了原子类,一些同步类操作等等,线程池)
package com.laoyang.id.service.impl;import jakarta.annotation.Resource;
import com.laoyang.id.dao.mapper.IdGenerateMapper;
import com.laoyang.id.dao.po.IdGeneratePO;
import com.laoyang.id.service.IdGenerateService;
import com.laoyang.id.service.bo.LocalSeqIdBO;
import com.laoyang.id.service.bo.LocalUnSeqIdBO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicLong;/*** @Author idea* @Date: Created in 19:58 2023/5/25* @Description*/
@Service
public class IdGenerateServiceImpl implements IdGenerateService, InitializingBean {@Resourceprivate IdGenerateMapper idGenerateMapper;private static final Logger LOGGER = LoggerFactory.getLogger(IdGenerateServiceImpl.class);private static Map<Integer, LocalSeqIdBO> localSeqIdBOMap = new ConcurrentHashMap<>();private static Map<Integer, LocalUnSeqIdBO> localUnSeqIdBOMap = new ConcurrentHashMap<>();private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(8, 16, 3, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000),new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {Thread thread = new Thread(r);thread.setName("id-generate-thread-" + ThreadLocalRandom.current().nextInt(1000));return thread;}});private static final float UPDATE_RATE = 0.50f;private static final int SEQ_ID = 1;private static Map<Integer, Semaphore> semaphoreMap = new ConcurrentHashMap<>();@Overridepublic Long getUnSeqId(Integer id) {if (id == null) {LOGGER.error("[getSeqId] id is error,id is {}", id);return null;}LocalUnSeqIdBO localUnSeqIdBO = localUnSeqIdBOMap.get(id);if (localUnSeqIdBO == null) {LOGGER.error("[getUnSeqId] localUnSeqIdBO is null,id is {}", id);return null;}Long returnId = localUnSeqIdBO.getIdQueue().poll();if (returnId == null) {LOGGER.error("[getUnSeqId] returnId is null,id is {}", id);return null;}this.refreshLocalUnSeqId(localUnSeqIdBO);return returnId;}/**** @param id 传的是对应的业务id* @return*/@Overridepublic Long getSeqId(Integer id) {if (id == null) {LOGGER.error("[getSeqId] id is error,id is {}", id);return null;}LocalSeqIdBO localSeqIdBO = localSeqIdBOMap.get(id);if (localSeqIdBO == null) {LOGGER.error("[getSeqId] localSeqIdBO is null,id is {}", id);return null;}this.refreshLocalSeqId(localSeqIdBO);long returnId = localSeqIdBO.getCurrentNum().incrementAndGet();if (returnId > localSeqIdBO.getNextThreshold()) {//同步去刷新 可能是高并发下还未更新本地数据LOGGER.error("[getSeqId] id is over limit,id is {}", id);return null;}return returnId;}/*** 刷新本地有序id段** @param localSeqIdBO*/private void refreshLocalSeqId(LocalSeqIdBO localSeqIdBO) {long step = localSeqIdBO.getNextThreshold() - localSeqIdBO.getCurrentStart();if (localSeqIdBO.getCurrentNum().get() - localSeqIdBO.getCurrentStart() > step * UPDATE_RATE) {Semaphore semaphore = semaphoreMap.get(localSeqIdBO.getId());if (semaphore == null) {LOGGER.error("semaphore is null,id is {}", localSeqIdBO.getId());return;}boolean acquireStatus = semaphore.tryAcquire();if (acquireStatus) {LOGGER.info("开始尝试进行本地id段的同步操作");//异步进行同步id段操作threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {try {IdGeneratePO idGeneratePO = idGenerateMapper.selectById(localSeqIdBO.getId());tryUpdateMySQLRecord(idGeneratePO);} catch (Exception e) {LOGGER.error("[refreshLocalSeqId] error is ", e);} finally {semaphoreMap.get(localSeqIdBO.getId()).release();LOGGER.info("本地有序id段同步完成,id is {}", localSeqIdBO.getId());}}});}}}/*** 刷新本地无序id段** @param localUnSeqIdBO*/private void refreshLocalUnSeqId(LocalUnSeqIdBO localUnSeqIdBO) {long begin = localUnSeqIdBO.getCurrentStart();long end = localUnSeqIdBO.getNextThreshold();long remainSize = localUnSeqIdBO.getIdQueue().size();//如果使用剩余空间不足25%,则进行刷新if ((end - begin) * 0.35 > remainSize) {LOGGER.info("本地无序id段同步开始,id is {}", localUnSeqIdBO.getId());Semaphore semaphore = semaphoreMap.get(localUnSeqIdBO.getId());if (semaphore == null) {LOGGER.error("semaphore is null,id is {}", localUnSeqIdBO.getId());return;}boolean acquireStatus = semaphore.tryAcquire();if (acquireStatus) {threadPoolExecutor.execute(new Runnable() {@Overridepublic void run() {try {IdGeneratePO idGeneratePO = idGenerateMapper.selectById(localUnSeqIdBO.getId());tryUpdateMySQLRecord(idGeneratePO);} catch (Exception e) {LOGGER.error("[refreshLocalUnSeqId] error is ", e);} finally {semaphoreMap.get(localUnSeqIdBO.getId()).release();LOGGER.info("本地无序id段同步完成,id is {}", localUnSeqIdBO.getId());}}});}}}//bean初始化的时候会回调到这里@Overridepublic void afterPropertiesSet() throws Exception {List<IdGeneratePO> idGeneratePOList = idGenerateMapper.selectAll();for (IdGeneratePO idGeneratePO : idGeneratePOList) {LOGGER.info("服务刚启动,抢占新的id段");tryUpdateMySQLRecord(idGeneratePO);semaphoreMap.put(idGeneratePO.getId(), new Semaphore(1));}}/*** 更新mysql里面的分布式id的配置信息,占用相应的id段* 同步执行,很多的网络IO,性能较慢** @param idGeneratePO*/private void tryUpdateMySQLRecord(IdGeneratePO idGeneratePO) {int updateResult = idGenerateMapper.updateNewIdCountAndVersion(idGeneratePO.getId(), idGeneratePO.getVersion());if (updateResult > 0) {localIdBOHandler(idGeneratePO);return;}//重试进行更新for (int i = 0; i < 3; i++) {idGeneratePO = idGenerateMapper.selectById(idGeneratePO.getId());updateResult = idGenerateMapper.updateNewIdCountAndVersion(idGeneratePO.getId(), idGeneratePO.getVersion());if (updateResult > 0) {localIdBOHandler(idGeneratePO);return;}}throw new RuntimeException("表id段占用失败,竞争过于激烈,id is " + idGeneratePO.getId());}/*** 专门处理如何将本地ID对象放入到Map中,并且进行初始化的** @param idGeneratePO*/private void localIdBOHandler(IdGeneratePO idGeneratePO) {long currentStart = idGeneratePO.getCurrentStart();long nextThreshold = idGeneratePO.getNextThreshold();long currentNum = currentStart;if (idGeneratePO.getIsSeq() == SEQ_ID) {LocalSeqIdBO localSeqIdBO = new LocalSeqIdBO();AtomicLong atomicLong = new AtomicLong(currentNum);localSeqIdBO.setId(idGeneratePO.getId());localSeqIdBO.setCurrentNum(atomicLong);localSeqIdBO.setCurrentStart(currentStart);localSeqIdBO.setNextThreshold(nextThreshold);localSeqIdBOMap.put(localSeqIdBO.getId(), localSeqIdBO);} else {LocalUnSeqIdBO localUnSeqIdBO = new LocalUnSeqIdBO();localUnSeqIdBO.setCurrentStart(currentStart);localUnSeqIdBO.setNextThreshold(nextThreshold);localUnSeqIdBO.setId(idGeneratePO.getId());long begin = localUnSeqIdBO.getCurrentStart();long end = localUnSeqIdBO.getNextThreshold();List<Long> idList = new ArrayList<>();for (long i = begin; i < end; i++) {idList.add(i);}//将本地id段提前打乱,然后放入到队列中Collections.shuffle(idList);ConcurrentLinkedQueue<Long> idQueue = new ConcurrentLinkedQueue<>();idQueue.addAll(idList);localUnSeqIdBO.setIdQueue(idQueue);localUnSeqIdBOMap.put(localUnSeqIdBO.getId(), localUnSeqIdBO);}}
}
最后创建启动类
package com.laoyang.id;import jakarta.annotation.Resource;
import org.apache.dubbo.config.spring.context.annotation.EnableDubbo;
import com.laoyang.id.service.IdGenerateService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.WebApplicationType;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;import java.util.HashSet;/*** @Author idea* @Date: Created in 19:45 2023/5/25* @Description*/
@SpringBootApplication
public class IdGenerateApplication implements CommandLineRunner {private static final Logger LOGGER = LoggerFactory.getLogger(IdGenerateApplication.class);@Resourceprivate IdGenerateService idGenerateService;public static void main(String[] args) {SpringApplication springApplication = new SpringApplication(IdGenerateApplication.class);springApplication.setWebApplicationType(WebApplicationType.NONE);springApplication.run(args);}@Overridepublic void run(String... args) throws Exception {HashSet<Long> idSet = new HashSet<>();for (int i = 0; i < 1500; i++) {Long id = idGenerateService.getSeqId(1);System.out.println(id);idSet.add(id);}System.out.println(idSet.size());}
}
最终会在控制台打印输出!








![[网鼎杯 2020 朱雀组]Nmap 通过nmap写入木马 argcmd过滤实现逃逸](https://img-blog.csdnimg.cn/45de470718864a15ba9c255414e8ee05.png)