ElasticSearch 高级操作
bulk批量操作
批量操作-脚本
#批量操作
#1.删除5号
#新增8号
#更新2号 name为2号
POST _bulk
{"delete":{"_index":"person1","_id":"5"}}
{"create":{"_index":"person1","_id":"8"}}
{"name":"八号","age":18,"address":"北京"}
{"update":{"_index":"person1","_id":"2"}}
{"doc":{"name":"2号"}}批量操作-java
/**
* Bulk 批量操作
*/
@Test
public void test2() throws IOException {
//创建bulkrequest对象,整合所有操作BulkRequest bulkRequest =new BulkRequest();/*# 1. 删除5号记录# 2. 添加6号记录# 3. 修改3号记录 名称为 “三号”*///添加对应操作//1. 删除5号记录DeleteRequest deleteRequest=new DeleteRequest("person1","5");bulkRequest.add(deleteRequest);//2. 添加6号记录Map<String, Object> map=new HashMap<>();map.put("name","六号");IndexRequest indexRequest=new IndexRequest("person1").id("6").source(map);bulkRequest.add(indexRequest);//3. 修改3号记录 名称为 “三号”Map<String, Object> mapUpdate=new HashMap<>();mapUpdate.put("name","三号");UpdateRequest updateRequest=new UpdateRequest("person1","3").doc(mapUpdate);bulkRequest.add(updateRequest);//执行批量操作BulkResponse response = client.bulk(bulkRequest,RequestOptions.DEFAULT);System.out.println(response.status());
}导入数据(从mysql导入ES)
第一步:创建索引
PUT goods
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_smart"},"price": {"type": "double"},"createTime": {"type": "date"},"categoryName": {"type": "keyword"},"brandName": {"type": "keyword"},"spec": {"type": "object"},"saleNum": {"type": "integer"},"stock": {"type": "integer"}}}
}第二步:java代码进行数据导入
/**
* 从Mysql 批量导入 elasticSearch
*/
@Test
public void test3() throws IOException {//1.查询所有数据,mysqlList<Goods> goodsList = goodsMapper.findAll();//2.bulk导入BulkRequest bulkRequest=new BulkRequest();//2.1 循环goodsList,创建IndexRequest添加数据for (Goods goods : goodsList) {//2.2 设置spec规格信息 Map的数据 specStr:{}String specStr = goods.getSpecStr();//将json格式字符串转为Map集合Map map = JSON.parseObject(specStr, Map.class);//设置spec mapgoods.setSpec(map);//将goods对象转换为json字符串String data = JSON.toJSONString(goods);IndexRequest indexRequest=newIndexRequest("goods").source(data,XContentType.JSON);bulkRequest.add(indexRequest);}BulkResponse response = client.bulk(bulkRequest,RequestOptions.DEFAULT);System.out.println(response.status());
}ElasticSearch查询
matchAll
脚本
# 默认情况下,es一次展示10条数据,通过from和size来控制分页
# 查询结果详解
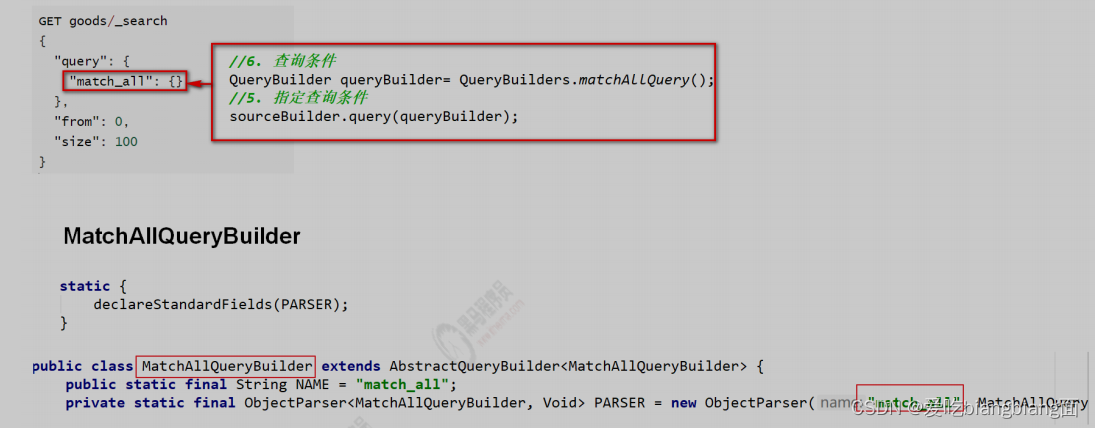
GET goods/_search
{"query": {"match_all": {}},"from": 0,"size": 100
}
GET gjava
/**
* 查询所有
* 1. matchAll
* 2. 将查询结果封装为Goods对象,装载到List中
* 3. 分页。默认显示10条
*/
@Test
public void matchAll() throws IOException {//2. 构建查询请求对象,指定查询的索引名称SearchRequest searchRequest=new SearchRequest("goods");//4. 创建查询条件构建器SearchSourceBuilderSearchSourceBuilder sourceBuilder=new SearchSourceBuilder();//6. 查询条件QueryBuilder queryBuilder= QueryBuilders.matchAllQuery();//5. 指定查询条件sourceBuilder.query(queryBuilder);//3. 添加查询条件构建器 SearchSourceBuildersearchRequest.source(sourceBuilder);// 8 . 添加分页信息 不设置 默认10条// sourceBuilder.from(0);// sourceBuilder.size(100);//1. 查询,获取查询结果SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);//7. 获取命中对象 SearchHitsSearchHits hits = searchResponse.getHits();//7.1 获取总记录数Long total= hits.getTotalHits().value;System.out.println("总数:"+total);//7.2 获取Hits数据 数组SearchHit[] hits1 = hits.getHits();//获取json字符串格式的数据List<Goods> goodsList = new ArrayList<>();for (SearchHit searchHit : hits1) {String sourceAsString = searchHit.getSourceAsString();//转为java对象Goods goods = JSON.parseObject(sourceAsString, Goods.class);goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}
} 设置条件的疑问点
termQuery和matchQuery
term 查询和字段类型有关系,首先回顾一下 ElasticSearch 两个数据类型
ElasticSearch 两个数据类型(做映射时候用于区别是否对这个字段的内容进行分词)
text :会分词,不支持聚合keyword :不会分词,将全部内容作为一个词条,支持聚合
termQuery和matchQuery作用类似,但是是用在查询条件上的,分别代表的不同的查询方式,termQuery不会对查询条件进行分词,matchQuery则会对查询条件进行分词
term 查询:会将华为手机作为一个整体查询
GET goods/_search
{"query": {"term": {"title": {"value": "华为手机"}}}
} match查询:会将华为手机分为:华为和手机进行查询
# match查询
GET goods/_search
{"query": {"match": {"title": "华为手机"}},"size": 500
} 总结:
term query 会去倒排索引中寻找确切的 term ,它并不知道分词器的存在。这种查询适合 keyword 、numeric 、 date类型match query 知道分词器的存在。并且理解是如何被分词的
模糊查询
wildcard 查询:会对查询条件进行分词。还可以使用通配符 ? (任意单个字符) 和 * ( 0 个或多个字符)
"* 华 *" 包含华字的" 华 *" 华字后边多个字符" 华 ?" 华字后边多个字符"* 华 " 或 "? 华 " 会引发全表(全索引)扫描 注意效率问题
# wildcard 查询。查询条件分词,模糊查询
GET goods/_search
{"query": {"wildcard": {"title": {"value": "华*"}}}
}正则查询
\W :匹配包括下划线的任何单词字符,等价于 [A-Z a-z 0-9_] 开头的反斜杠是转义符+ 号多次出现(.)* 为任意字符正则查询取决于正则表达式的效率
GET goods/_search
{"query": {"regexp": {"title": "\\w+(.)*"}}
}前缀查询
对 keyword 类型支持比较好
GET goods/_search
{"query": {"prefix": {"brandName": {"value": "三"}}}
}模糊查询-JavaAPI
//模糊查询
WildcardQueryBuilder query = QueryBuilders.wildcardQuery("title", "华*");//华后多
个字符
//正则查询
RegexpQueryBuilder query = QueryBuilders.regexpQuery("title", "\\w+(.)*");
//前缀查询
PrefixQueryBuilder query = QueryBuilders.prefixQuery("brandName", "三");范围&排序查询
# 范围查询
GET goods/_search
{"query": {"range": {"price": {"gte": 2000,"lte": 3000}}},"sort": [{"price": {"order": "desc"}}]}queryString查询
queryString 多条件查询
• 会对查询条件进行分词。
• 然后将分词后的查询条件和词条进行等值匹配
• 默认取并集( OR )
• 可以指定多个查询字段
query_string :识别 query 中的连接符( or 、 and )
# queryString
GET goods/_search
{"query": {"query_string": {"fields": ["title","categoryName","brandName"],"query": "华为 AND 手机"}}
} simple_query_string :不识别 query 中的连接符( or 、 and ),查询时会将 “ 华为 ” 、 "and" 、 “ 手机 ” 分别进行查询
GET goods/_search
{"query": {"simple_query_string": {"fields": ["title","categoryName","brandName"],"query": "华为 AND 手机"}}
} query_string :有 default_operator 连接符的脚本
GET goods/_search
{"query": {"query_string": {"fields": ["title","brandName","categoryName"],"query": "华为手机 ", "default_operator": "AND"}}
} java 代码
QueryStringQueryBuilder query = QueryBuilders.queryStringQuery("华为手
机").field("title").field("categoryName")
.field("brandName").defaultOperator(Operator.AND); simple_query_string :有 default_operator 连接符的脚本
GET goods/_search
{"query": {"simple_query_string": {"fields": ["title","brandName","categoryName"],"query": "华为手机 ", "default_operator": "OR"}}
} 注意: query 中的 or and 是查询时 匹配条件是否同时出现 ----or 出现一个即可, and 两个条件同时出现 default_operator 的 or and 是对结果进行 并集( or )、交集( and )
布尔查询
boolQuery :对多个查询条件连接。连接方式:
•must ( and ):条件必须成立
•must_not ( not ):条件必须不成立
•should ( or ):条件可以成立
•filter :条件必须成立,性能比 must 高。不会计算得分
得分 : 即条件匹配度 , 匹配度越高,得分越高
# boolquery
#must和filter配合使用时,max_score(得分)是显示的
#must 默认数组形式
GET goods/_search
{"query": {"bool": {"must": [{"term": {"brandName": {"value": "华为"}}}],"filter": [{"term": {"title": "手机"}},{"range": {"price": {"gte": 2000,"lte": 3000}}}]}}
}
#filter 单独使用 filter可以是单个条件,也可多个条件(数组形式)
{"query": {"bool": {"filter": [{"term": {"brandName": {"value": "华为"}}}]}}
} 布尔查询 -JavaAPI
布尔查询: boolQuery
1. 查询品牌名称为 : 华为
2. 查询标题包含:手机
3. 查询价格在: 2000-3000
must 、 filter 为连接方式
term 、 match 为不同的查询方式
//1.构建boolQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//2.构建各个查询条件
//2.1 查询品牌名称为:华为
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("brandName","华为");
boolQuery.must(termQueryBuilder);
//2.2. 查询标题包含:手机
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("title", "手机");
boolQuery.filter(matchQuery);
//2.3 查询价格在:2000-3000
RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("price");
rangeQuery.gte(2000);
rangeQuery.lte(3000);
boolQuery.filter(rangeQuery);
sourceBuilder.query(boolQuery);聚合查询
• 指标聚合:相当于 MySQL 的聚合函数。 max 、 min 、 avg 、 sum 等
• 桶聚合:相当于 MySQL 的 group by 操作。不要对 text 类型的数据进行分组,会失败。
# 聚合查询
# 指标聚合 聚合函数
GET goods/_search
{"query": {"match": {"title": "手机"}},"aggs": {"max_price": {"max": {"field": "price"}}}
}
# 桶聚合 分组
GET goods/_search
{"query": {"match": {"title": "手机"}},"aggs": {"goods_brands": {"terms": {"field": "brandName","size": 100}}}
}
聚合查询 -JavaAPI
聚合查询:桶聚合,分组查询
1. 查询 title 包含手机的数据
2. 查询品牌列表
/**
* 聚合查询:桶聚合,分组查询
* 1. 查询title包含手机的数据
* 2. 查询品牌列表
*/
@Test
public void testAggQuery() throws IOException {SearchRequest searchRequest=new SearchRequest("goods");SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();//1. 查询title包含手机的数据MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "手机");sourceBuilder.query(queryBuilder);//2. 查询品牌列表 只展示前100条AggregationBuilder aggregation=AggregationBuilders.terms("goods_brands").field("brandName").size(100);sourceBuilder.aggregation(aggregation);searchRequest.source(sourceBuilder);SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);//7. 获取命中对象 SearchHitsSearchHits hits = searchResponse.getHits();//7.1 获取总记录数Long total= hits.getTotalHits().value;System.out.println("总数:"+total);// aggregations 对象Aggregations aggregations = searchResponse.getAggregations();//将aggregations 转化为mapMap<String, Aggregation> aggregationMap = aggregations.asMap();//通过key获取goods_brands 对象 使用Aggregation的子类接收 buckets属性在Terms接口中体现// Aggregation goods_brands1 = aggregationMap.get("goods_brands");Terms goods_brands =(Terms) aggregationMap.get("goods_brands");//获取buckets 数组集合List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();Map<String,Object>map=new HashMap<>();//遍历buckets key 属性名,doc_count 统计聚合数for (Terms.Bucket bucket : buckets) {System.out.println(bucket.getKey());map.put(bucket.getKeyAsString(),bucket.getDocCount());}System.out.println(map);
}
高亮查询
高亮三要素:
• 高亮字段
• 前缀
• 后缀
默认前后缀 : em
<em> 手机 </em>
GET goods/_search
{"query": {"match": {"title": "电视"}},"highlight": {"fields": {"title": {"pre_tags": "<font color='red'>","post_tags": "</font>"}}} 高亮查询 -JavaAPI
实施步骤:
高亮查询:
1. 设置高亮
高亮字段
前缀
后缀
2. 将高亮了的字段数据,替换原有数据
/**
*
* 高亮查询:
* 1. 设置高亮
* * 高亮字段
* * 前缀
* * 后缀
* 2. 将高亮了的字段数据,替换原有数据
*/
@Test
public void testHighLightQuery() throws IOException {SearchRequest searchRequest = new SearchRequest("goods");SearchSourceBuilder sourceBulider = new SearchSourceBuilder();// 1. 查询title包含手机的数据MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");sourceBulider.query(query);//设置高亮HighlightBuilder highlighter = new HighlightBuilder();//设置三要素highlighter.field("title");//设置前后缀标签highlighter.preTags("<font color='red'>");highlighter.postTags("</font>");//加载已经设置好的高亮配置sourceBulider.highlighter(highlighter);searchRequest.source(sourceBulider);SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();//获取记录数long value = searchHits.getTotalHits().value;System.out.println("总记录数:"+value);List<Goods> goodsList = new ArrayList<>();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String sourceAsString = hit.getSourceAsString();//转为javaGoods goods = JSON.parseObject(sourceAsString, Goods.class);// 获取高亮结果,替换goods中的titleMap<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField HighlightField = highlightFields.get("title");Text[] fragments = HighlightField.fragments();//highlight title替换 替换goods中的titlegoods.setTitle(fragments[0].toString());goodsList.add(goods);}for (Goods goods : goodsList) {System.out.println(goods);}
}重建索引&索引别名
#查询别名 默认别名无法查看,默认别名同索引名
GET goods/_alias/
#结果
{"goods" : {"aliases" : { }}
} 1. 新建 student_index_v1 索引
# -------重建索引-----------
# 新建student_index_v1。索引名称必须全部小写
PUT student_index_v1
{"mappings": {"properties": {"birthday":{"type": "date"}}}
}
#查看 student_index_v1 结构
GET student_index_v1
#添加数据
PUT student_index_v1/_doc/1
{
"birthday":"1999-11-11"
}
#查看数据
GET student_index_v1/_search
#添加数据
PUT student_index_v1/_doc/1
{
"birthday":"1999年11月11日"
} 2. 重建索引 : 将 student_index_v1 数据拷贝到 student_index_v2
# 业务变更了,需要改变birthday字段的类型为text
# 1. 创建新的索引 student_index_v2
# 2. 将student_index_v1 数据拷贝到 student_index_v2
# 创建新的索引 student_index_v2
PUT student_index_v2
{"mappings": {"properties": {"birthday":{"type": "text"}}}
}
# 将student_index_v1 数据拷贝到 student_index_v2
# _reindex 拷贝数据
POST _reindex
{"source": {"index": "student_index_v1"},"dest": {"index": "student_index_v2"}
}
GET student_index_v2/_search
PUT student_index_v2/_doc/2
{
"birthday":"1999年11月11日"
} 3. 创建索引库别名:
注意: DELETE student_index_v1 这一操作将删除 student_index_v1 索引库,并不是删除别名
# 思考: 现在java代码中操作es,还是使用的实student_index_v1老的索引名称。
# 1. 改代码(不推荐)
# 2. 索引别名(推荐)
# 步骤:
# 0. 先删除student_index_v1
# 1. 给student_index_v2起个别名 student_index_v1
# 先删除student_index_v1
#DELETE student_index_v1 这一操作将删除student_index_v1索引库
#索引库默认的别名与索引库同名,无法删除
# 给student_index_v1起个别名 student_index_v11
POST student_index_v2/_alias/student_index_v11
#测试删除命令
POST /_aliases
{"actions": [{"remove": {"index": "student_index_v1", "alias": "student_index_v11"}}]
}
# 给student_index_v2起个别名 student_index_v1
POST student_index_v2/_alias/student_index_v1
#查询别名
GET goods/_alias/
GET student_index_v1/_search
GET student_index_v2/_search