随着大型语言模型(LLMs)的广泛应用,文本嵌入技术在语义相似性编码、搜索、聚类和分类等方面发挥着重要作用。然而,文本嵌入所蕴含的隐私风险尚未得到充分探讨。研究提出了一种控制生成的方法,通过迭代修正和重新嵌入文本,以生成与固定嵌入点接近的文本。研究发现,尽管基于嵌入的朴素模型表现不佳,但多步骤方法能够精确恢复92%的32个标记文本输入。此外,模型还能够从临床笔记数据集中恢复重要的个人信息(如全名)。
在利用大型语言模型的系统中,文本数据的嵌入向量通常存储在向量数据库中。尽管向量数据库越来越受欢迎,但它们内部的隐私威胁尚未得到全面探索。本文旨在探讨第三方服务是否能够根据给定的嵌入向量重现初始文本,从而对隐私构成威胁。
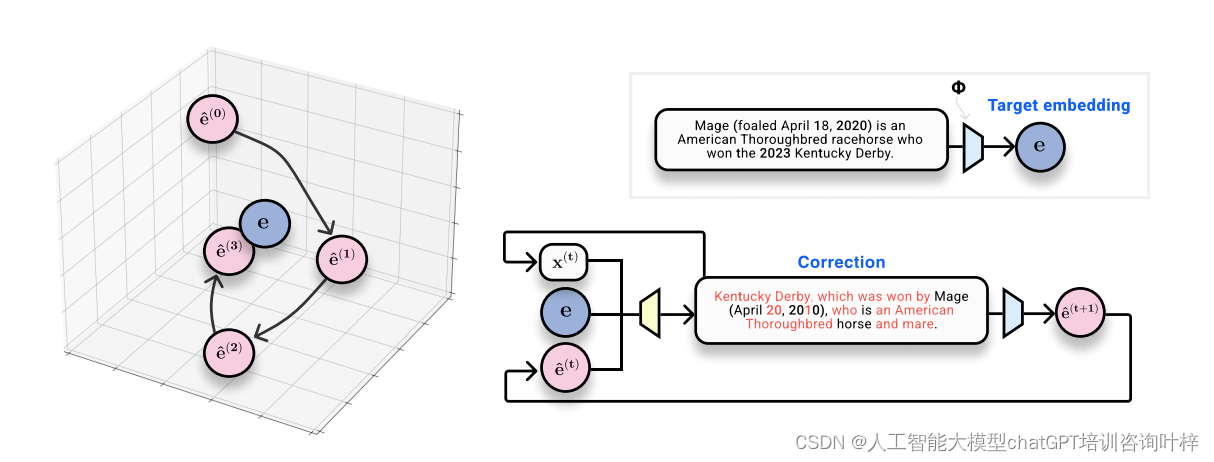
方法:Vec2Text
Vec2Text方法是一种用于从文本嵌入向量重构原始文本的迭代修正过程。这种方法的核心在于控制生成,即生成满足特定条件(在本例中为与目标嵌入向量接近)的文本。以下是Vec2Text方法的详细说明:
1. 控制生成的启发式方法
Vec2Text方法基于控制生成的原理,它生成文本以满足一个已知的条件,即生成的文本在重新嵌入后,其嵌入向量应尽可能接近一个给定的目标嵌入点。
2. 迭代修正过程
这个过程从一个初始假设开始,并逐步通过迭代修正来改进这个假设。每一步都包括以下操作:
- 使用当前的文本假设重新生成嵌入向量(
ˆe(t) = ϕ(x(t)))。 - 计算当前嵌入向量与目标嵌入向量之间的差异。
- 根据这个差异来修正文本假设,生成一个新的更接近目标嵌入的文本假设。
3. 编码器-解码器变换器(Transformer)
Vec2Text使用标准的编码器-解码器架构的Transformer模型来生成和修正文本。Transformer模型因其在自然语言处理任务中的高效性能而广泛使用。
4. 多层感知机(MLP)
由于Transformer模型需要序列形式的输入,而嵌入向量是固定长度的向量,因此Vec2Text使用MLP来将嵌入向量投影到适合Transformer编码器的序列长度。具体步骤如下:
- 使用MLP将目标嵌入向量
e、当前假设嵌入向量ˆe(t)以及两者的差异e - ˆe(t)投影到更大的维度空间。 - 将这些投影后的向量与假设文本的词嵌入向量连接起来,形成Transformer编码器的输入。
5. 模型参数化
Vec2Text模型的参数化包括:
- 一个基础的文本逆向模型,用于生成初始假设
p(x(0) | e)。 - 一个条件语言模型,用于从给定嵌入重构未知文本
x。
6. 训练过程
模型训练涉及以下步骤:
- 从基础模型生成初始假设
x(0)。 - 计算初始假设的嵌入
ˆe(0)。 - 在生成的数据上训练模型,以改进文本假设。
7. 推理过程
在实际应用中,由于无法对所有中间假设进行求和,Vec2Text使用束搜索(beam search)来近似这个过程。在每一步修正中,考虑一定数量的可能修正,并解码这些修正的顶部可能延续,然后通过测量它们与目标嵌入在嵌入空间中的距离来选择顶部的独特延续。
Vec2Text方法通过这种方式能够有效地从文本嵌入向量中恢复原始文本,展示了文本嵌入技术在隐私保护方面的潜在风险。
实验设置
Vec2Text在两个最先进的嵌入模型上进行训练:GTR-base和OpenAI的text-embeddings-ada-002。还评估了在BEIR基准的多种常见检索语料库上生成的嵌入,以及MIMIC-III临床笔记数据库。
训练模型
Vec2Text方法在两个高绩效的文本嵌入模型上进行了训练:
-
GTR-base: 这是一个基于T5的预训练变换器模型,专门为文本检索任务设计。GTR-base模型在MTEB(Massive Text Embedding Benchmark)文本嵌入基准测试中表现出色。
-
text-embeddings-ada-002: 这是通过OpenAI API提供的模型,也是一个高性能的文本嵌入模型。
训练数据集
-
Wikipedia文章: Vec2Text的GTR模型训练使用了从Natural Questions语料库中选取的500万个Wikipedia文章段落,每个段落被截断至32个标记(tokens)。
-
MSMARCO语料库: Vec2Text的OpenAI模型训练使用了MSMARCO语料库的两个版本,每个版本的最大标记数分别为32和128。
评估数据集
-
BEIR基准: 为了评估模型在不同检索语料库上的表现,研究者使用了BEIR(Benchmark for Explainable Information Retrieval)基准的15个不同数据集。这些数据集覆盖了多种领域和类型的文本。
-
MIMIC-III临床笔记数据库: 此外,研究者还评估了Vec2Text在MIMIC-III(Medical Information Mart for Intensive Care)数据库中的临床笔记嵌入上的表现。这个数据库包含了大量的临床医疗记录,用于评估模型恢复敏感个人信息的能力。
实验细节
-
模型参数: Vec2Text模型使用了约2.35亿参数,其中包括编码器-解码器架构和投影头(projection head)。
-
超参数: 在实验中,研究者设置了投影序列长度
s为16,这是基于初步实验结果确定的,因为增加此数值的收益递减。 -
优化器和学习率: 使用了Adam优化器,学习率为2×10^-4,并采用了预热和线性衰减策略。
-
训练周期: 模型训练了100个周期。
-
硬件: 所有模型都在4个NVIDIA A6000 GPU上进行训练。
这些实验设置展示了Vec2Text方法在不同文本嵌入模型和数据集上的训练和评估过程,以及它在恢复原始文本方面的潜力。通过这些实验,研究者能够评估文本嵌入的隐私风险,并提出了相应的保护措施。
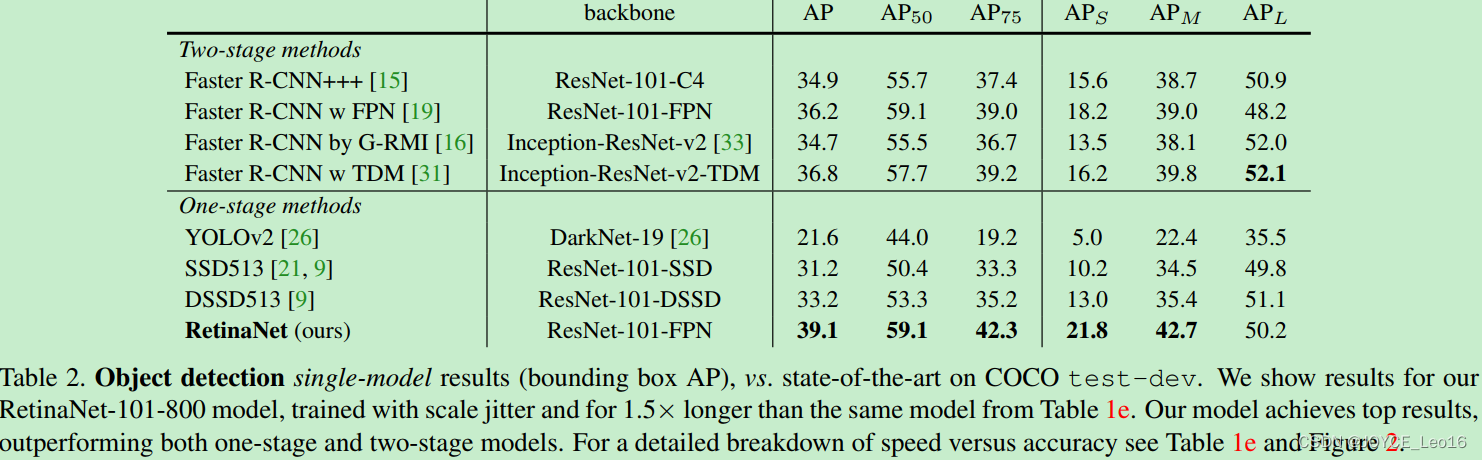
结果
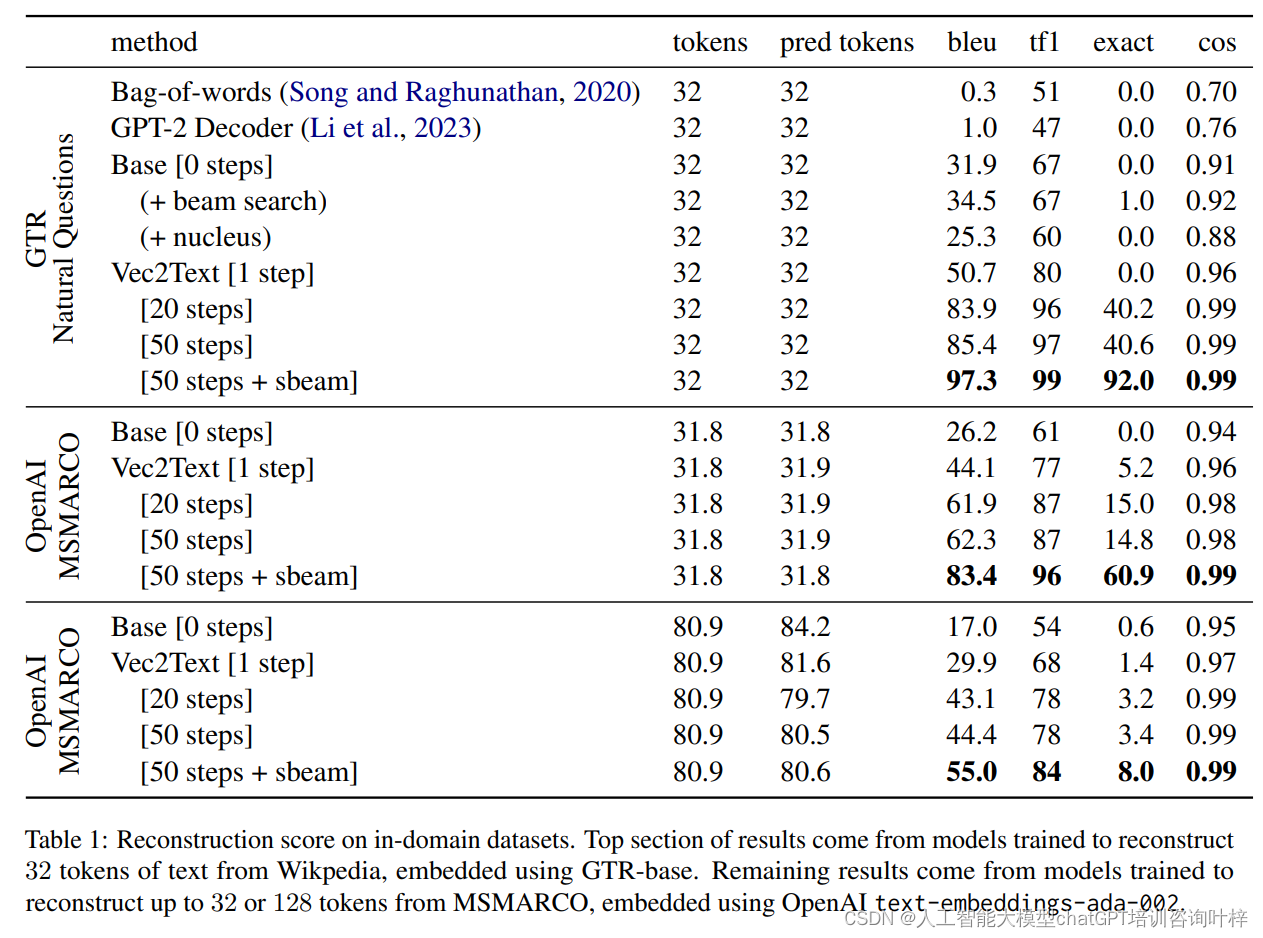
域内数据集上的表现
Vec2Text在域内数据集上的表现超过了所有基线模型。这些基线模型包括简单的词袋模型和GPT-2解码器,它们没有使用迭代修正步骤来恢复文本。Vec2Text使用以下指标进行评估:
- BLEU分数: 用于衡量重构文本和原始文本之间的n-gram相似度。
- Token F1: 多类F1分数,衡量预测的标记集合和真实标记集合之间的关系。
- 精确匹配: 重构输出完全匹配原始文本的百分比。
- 余弦相似度: 原始嵌入向量和重构文本嵌入向量之间的相似度。
Vec2Text在这些指标上都显示出了优越的性能,特别是在使用GTR-base模型时,经过50步迭代修正后,对于32个标记的输入,BLEU分数达到了97.3,并且能够精确恢复92%的示例。
BEIR基准上的表现
Vec2Text在BEIR基准的15个数据集上进行了评估,这些数据集覆盖了不同的领域和文本类型。模型展示了对不同长度输入的适应性,并且在所有数据集上都取得了以下最低恢复性能:
- Token F1分数: 至少41%,表明模型能够准确预测大部分的标记。
- 余弦相似度: 至少0.95,表明重构的嵌入向量与真实嵌入向量在向量空间中非常接近。
这些结果表明,即使在未见过的文本数据上,Vec2Text也能够有效地恢复文本内容,从而证实了文本嵌入可能带来的隐私风险。
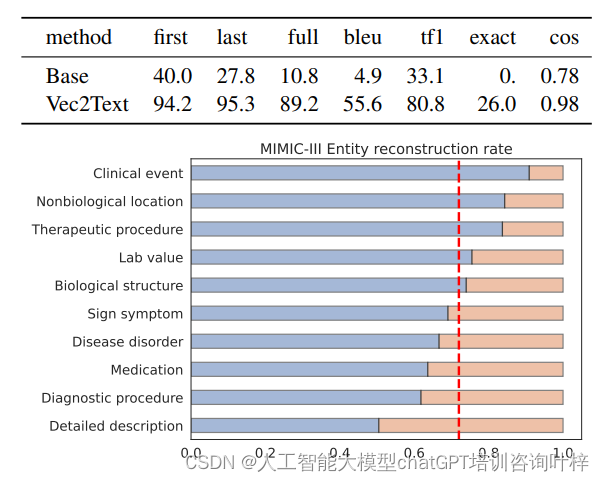
MIMIC-III临床笔记
在MIMIC-III临床笔记数据库上,Vec2Text能够恢复大部分的个人信息,包括:
- 94%的名(first names)
- 95%的姓(last names)
- 89%的全名(full names)
这些结果进一步强调了在处理敏感数据时,需要特别注意保护文本嵌入的隐私。
论文链接:http://arxiv.org/pdf/2310.06816