论文精读-基于FPGA的卷积神经网络和视觉Transformer通用加速器
优势:
1.针对CNN和Transformer提出了通用的计算映射(共用计算单元,通过不同的映射指令,指导数据通路和并行计算)
2.非线性与归一化加速单元(支持softmax,gelu,层归一化函数,共用加速单元)
3.计算空间探索,通过片上模型计算量穷举(profiling),得到最佳计算量配置参数。同理在进行e^x函数近似时,也进行相同操作。
4.使用分布式存储复用权重,减少片外访问(多级存储降低延迟)+ 非线性与归一化单元使用低精度计算(fp16),PE计算阵列使用DSP时钟倍频和INT8乘法并行计算方法共享DSP资源,减少资源消耗。
概述
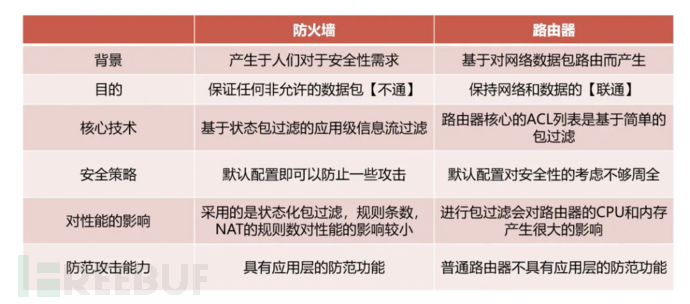
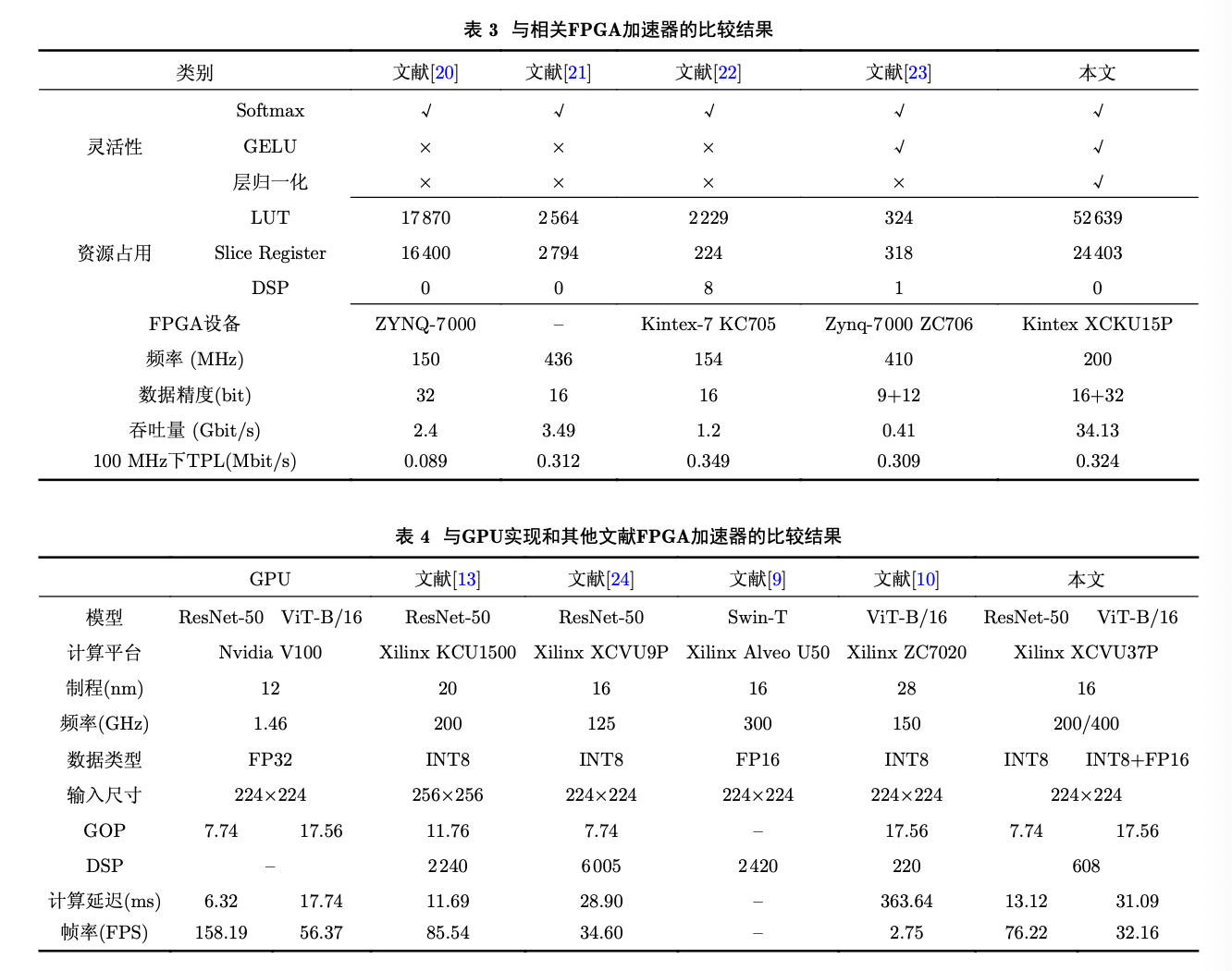
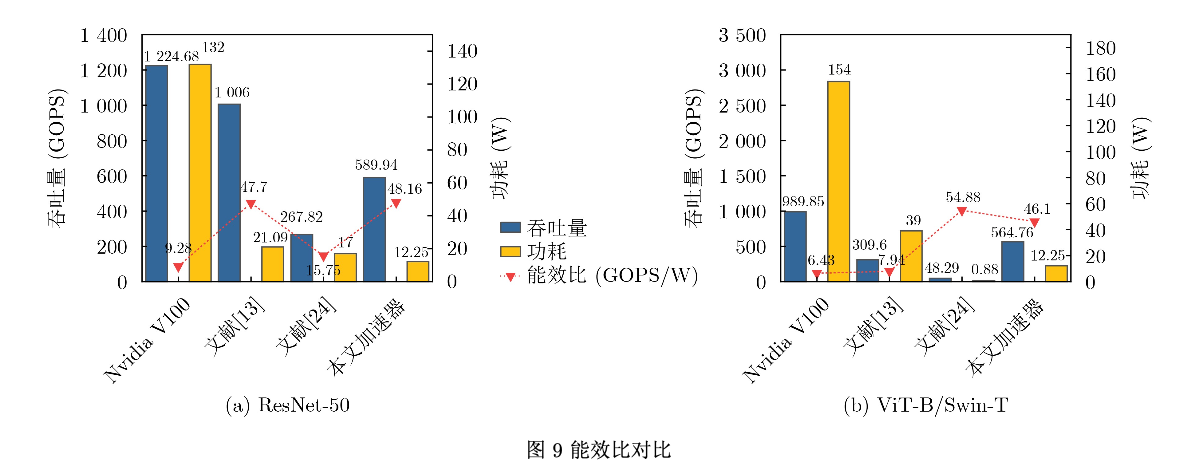
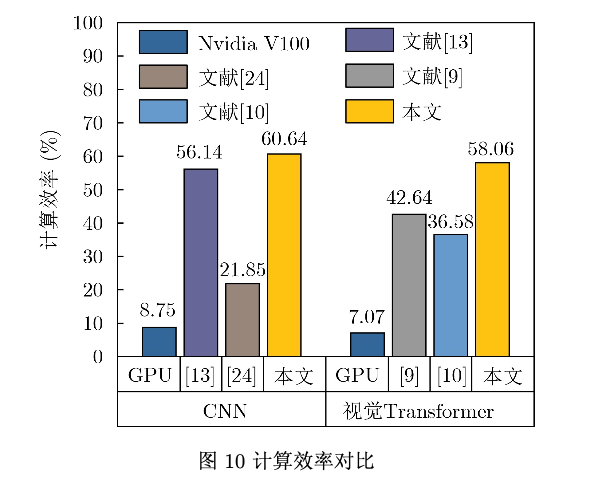
针对计算机视觉领域中基于现场可编程逻辑门阵列(FPGA)的传统卷积神经网(CNN)络加速器不适配视 觉Transformer网络的问题,该文提出一种面向卷积神经网络和Transformer的通用FPGA加速器。首先,根据卷 积和注意力机制的计算特征,提出一种面向FPGA的通用计算映射方法;其次,提出一种非线性与归一化加速单 元,为计算机视觉神经网络模型中的多种非线性和归一化操作提供加速支持;然后,在Xilinx XCVU37P FP- GA上实现了加速器设计。实验结果表明,所提出的非线性与归一化加速单元在提高吞吐量的同时仅造成很小的 精度损失,ResNet-50和ViT-B/16在所提FPGA加速器上的性能分别达到了589.94 GOPS和564.76 GOPS。与 GPU实现相比,能效比分别提高了5.19倍和7.17倍;与其他基于FPGA的大规模加速器设计相比,能效比有明显 提高,同时计算效率较对比FPGA加速器提高了8.02%~177.53%。
研究背景
卷积和注意力机制概述
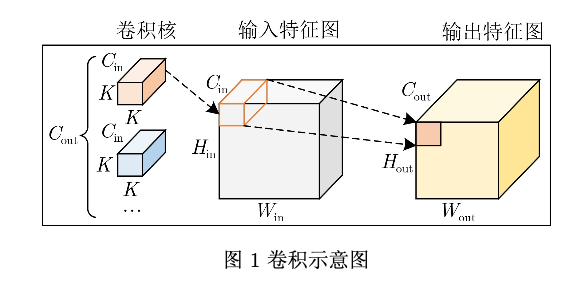
卷积是传统CNN最核心的组成部件,同时也是CNN模型中计算量最大的操作,卷积计算过程 如图1所示。卷积使用卷积核在输入特征图的2维空 间上滑动计算每个像素点及其相邻像素点与卷积核 的点积,最终得到一张输出特征图。图1中的Cin 和 Cout 分别表示卷积操作的输入通道数和输出通道 数。K 表示卷积核大小。Hin 和Win 表示输入特征图 的高度和宽度。Hout 和Wout 表示输入特征图的高度 和宽度。
注意力机制最关键的部分是自注意力操作,自 注意力计算流程如图2(a)所示。Xin 是自注意力操 作的输入,分别与权重WQ , WK 和WV 作线性矩阵
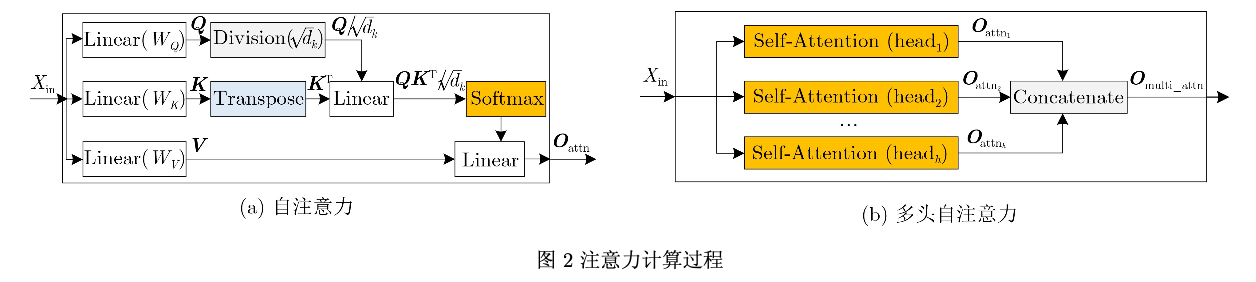
乘法得到Q, K 和V 。为避免Softmax函数的输入 绝对值过大,导致函数的梯度过小进而影响到梯度下降。将Q除以
sqrt(dk)。缩放后的Q与K 的转置KT 相乘,然后进行 Softmax操作,结果与V 相乘得到自注意力最终结 果Oattn 。现有的基于注意力机制的Transformer模 型大多数使用多头自注意力,由多个自注意力操作 组成,数量用Head(h)表示。图2(b)展示了Trans- former中多头自注意力的计算过程。每个头使用不 同的权重WQi , WKi 和WVi 来分别得到Qi , Ki 和 Vi。最后将h个自注意力输出拼接为Omulti−attn作为 多头自注意力的最终结果。
计算方式差异
由上述可知,卷积和注意力机制遵循着不同的 设计范式。卷积使用卷积核在感受野上计算得到 输出值,感受野是指输出特征图上的像素点在原始 图像上映射的区域。相比之下,注意力机制则是 对输入特征图及其中间结果进行操作,专注于不同 的区域,捕捉更多的特征信息。在推理过程中,卷 积计算过程中只涉及输入数据和训练后的模型 参数,而注意力计算过程还包括对当前输入的中间结 果进行操作,如Q, K , V 等。另外,与注意力中 的单通道2维矩阵乘法不同,卷积计算通常是多通 道的。
非线性与归一化操作差异
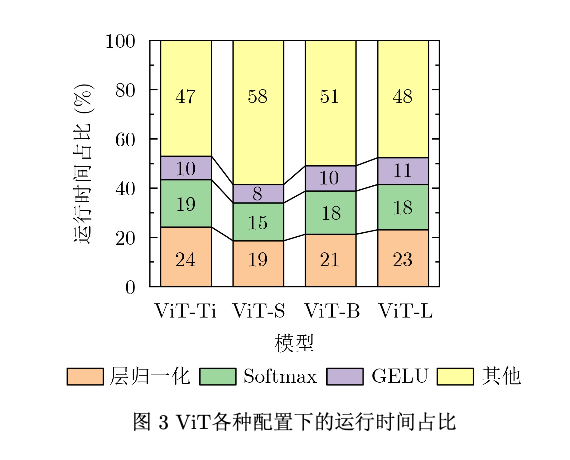
CNN和Transformer模型除了计算密集的线性操作,还包括激活和归一化函数。CNN通常采用 批归一化,由于批归一化在推理时可以作为固定权 重叠加进卷积层,同时CNN频繁使用的激活函数 ReLU可以在FPGA上使用简单的查找表实现,其 他非线性操作通常只在输出层进行,因此CNN中 的非线性与归一化操作基本不会影响其在FPGA上 推理的计算效率。Transformer通常采用层归一 化,层归一化的对象是单个样本,它对该样本的所 有维度的特征进行操作。层归一化使用输入数据的 均值和方差作为参数,与输入数据强相关。除了层 归一化,Transformer还包括频繁使用的Softmax和 GELU激活函数,这些操作在推理时引入了大量时间成本,在CPU上推理一张图像的运行时间占比 如图3所示。
问题小结
由于CNN和Transformer在计算方式和非线性 与归一化操作上存在着以上差异,给当前的计算机 视觉神经网络FPGA加速器设计带来了以下挑战。
(1) 如何在FPGA计算资源上同时映射计算方 式不同的卷积和注意力机制;
(2) 如何在保证精度的前提下设计非线性与归 一化加速单元以支持Transformer中的层归一化, Softmax和GELU激活函数加速;
(3) 基于上述两个挑战,如何将基于CNN和Trans- former的算法模型映射到FPGA上进行加速。
加速器设计
乘法单元探索
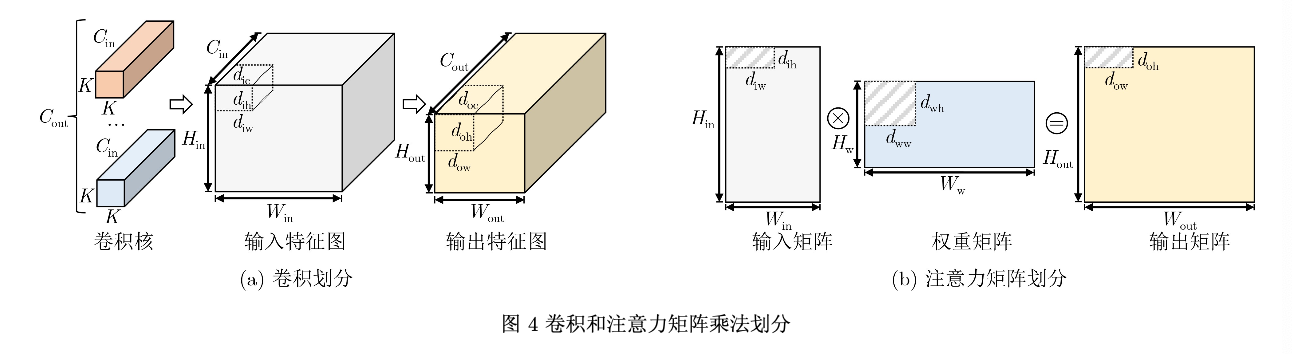
本文将(Ni,No)与(dic,doc,dow,doh) 和(diw, dow, doh)前两个维度对应。对于卷积,对划 分块逐通道计算,Ni 对应dic ,No 对应doc 。对于注 意力机制中的矩阵乘法,对划分块逐行计算, Ni 对应diw ,No 对应dow 。
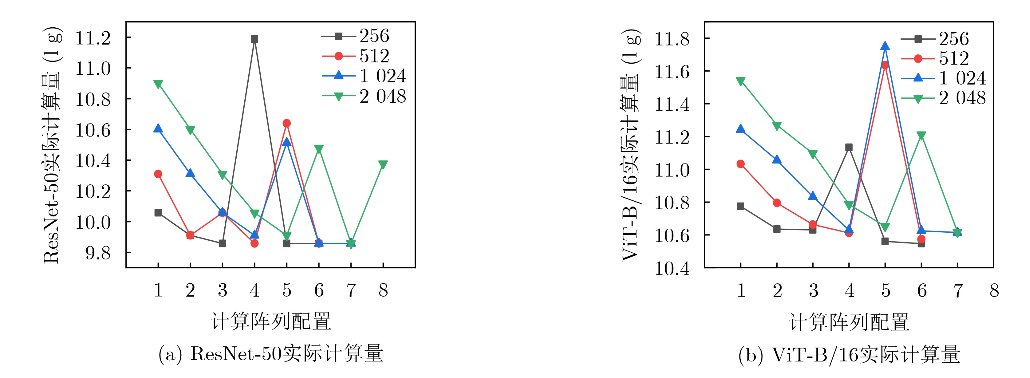
为了探索计算阵列配置(Ni, No),本文以计算 量最小化为目标,提出了片上模型计算量穷举法。

结果如下:
非线性与归一化加速单元
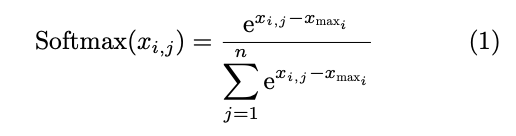
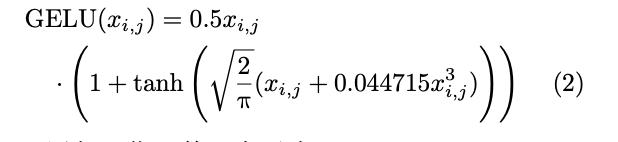
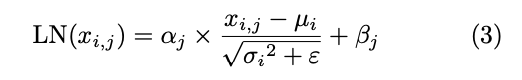
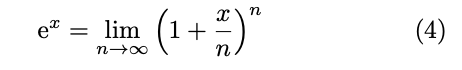
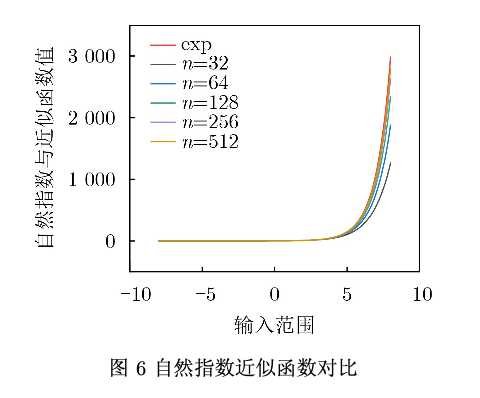
=> g(x) = (1 + x/128)^128
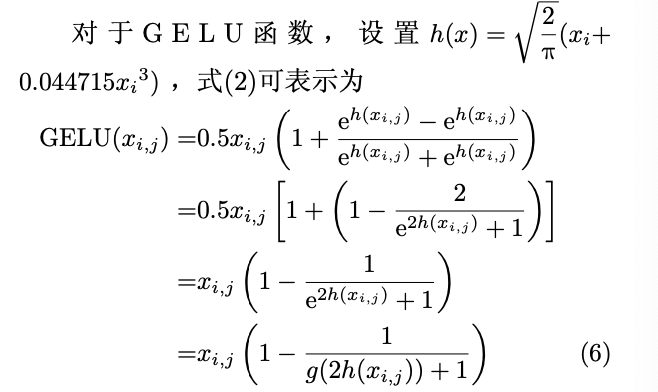
在FPGA上计算方差 σi2 的倒数平方根会导致较大的硬件开销,因此本 文使用快速倒数平方根算法(Fast Inverse Square Root, FISR)
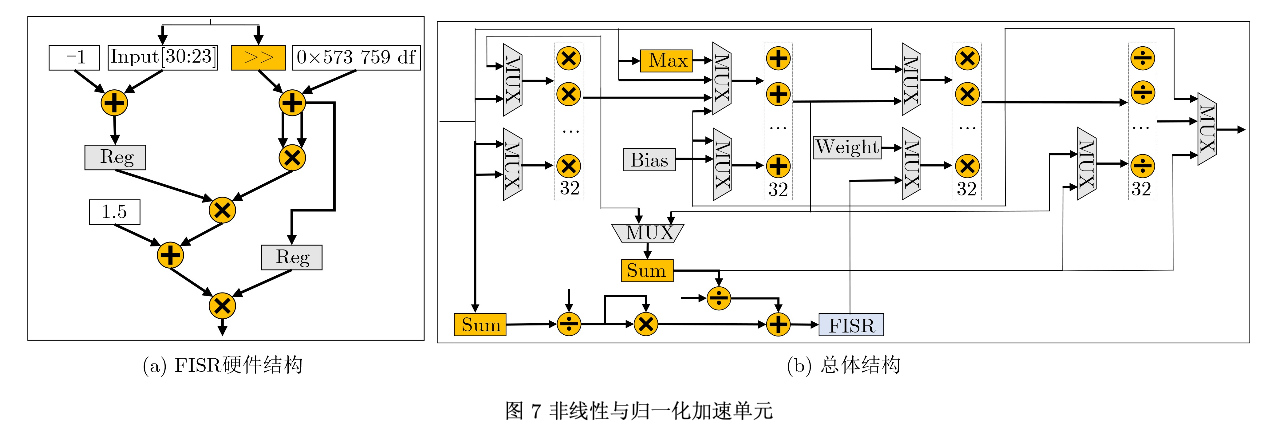
(2组32路输入的乘法 器,1组32路输入的加法器和1组32路输入的除法 器,2组32路输入的加法树)
fp32用于计算方差倒数
其他单元都使用fp16
加速器架构
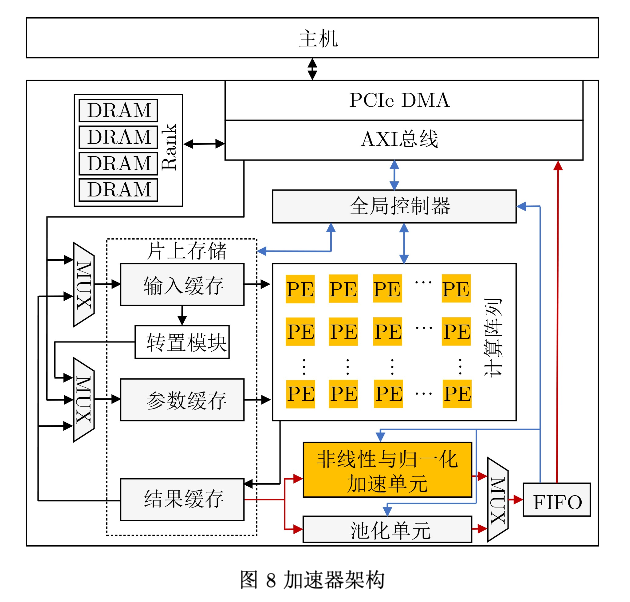
其他资源优化:
基于DSP时钟倍频和INT8乘法并行计算方法,1个DSP可以在每个系统时钟周期内完成4次乘法操 作。因此当(Ni, No)配置为(32, 64)时,计算阵列的 乘加器只需消耗512个DSP,每个DSP负责4个输出 通道方向上的计算。在计算阵列中嵌入了分布式存 储(Look-Up-Table Random Access Memory, LUTRAM)来尽可能地复用权重,减少片外访存量。
执行过程:
通过主机解析网络结 构描述文件,对神经网络模型进行划分,确定调度 顺序,并生成映射指令。预编译的映射指令、预处 理的划分块在运行前通过基于高速串行计算机扩展 总线标准(Peripheral Component Interface experss, PCIe)的直接内存访问(Direct Memory Access, DMA)存储在片外动态随机存取存储器 (Dynamic Random Access Memory, DRAM)。全 局控制器接收预编译的映射指令来驱动加速器,将 指令发送到片上存储和计算阵列等模块控制数据处 理,或将数据请求发送到DRAM读写数据。
数据流动:
预处理的划分块在运行时从DRAM中提取到 输入缓存或参数缓存。计算阵列从这些缓存读取数 据和参数进行计算。结果缓存负责存储中间或最终 结果。当该层包括非线性或归一化或池化操作时, 计算结果从结果缓存读入非线性与归一化加速单元 或池化单元进行处理,完成后写入DRAM或写回 输入缓存或参数缓存进行下一步计算。
实验结果
QA
Q:全流水线设计?
A:在IC(集成电路)设计中,全流水线设计是指采用流水线架构来设计和制造集成电路。通过将IC设计成流水线结构,可以提高处理速度、降低功耗,并且可以更好地利用硬件资源。
Q:批归一化与层归一化区别与作用,应用场景?
A:
-
区别:
- 批归一化(BN):在神经网络的每一层中,对每个训练小批量数据的输入进行归一化处理,即对每个特征维度进行归一化,然后再应用缩放和平移操作。
- 层归一化(LN):在神经网络的每一层中,对每个训练样本的所有特征进行归一化处理,即对每个样本的所有特征维度进行归一化,然后再应用缩放和平移操作。
-
作用:
- 批归一化(BN):通过减少训练过程中内部协变量偏移(Internal Covariate Shift),加速了模型训练过程,有助于梯度传播,提高了模型的泛化能力。同时,BN还有一定的正则化效果,可以缓解过拟合。
- 层归一化(LN):与批归一化类似,层归一化也有助于减少内部协变量偏移,但它在处理不同样本时更加独立,因此在处理小样本或序列数据(如自然语言处理中的序列数据)时可能更有效。此外,层归一化还可以在训练和推理时提供一致的输出,而不受批量大小的影响。
-
批归一化的应用场景:
- 大规模数据集:在大规模数据集上进行训练时,批归一化通常能够提供较好的性能。因为在大规模数据集上,对每个小批量数据进行归一化可以更好地估计每个特征的统计信息,有助于模型训练的稳定性和收敛速度。
- 图像处理和计算机视觉:批归一化在图像处理和计算机视觉任务中广泛应用,例如图像分类、目标检测和语义分割等任务。
- 深度卷积神经网络(CNN):对于深度的卷积神经网络,批归一化可以加速训练过程,提高模型的泛化能力,并且有助于解决梯度消失或梯度爆炸的问题。
-
层归一化的应用场景:
- 小样本数据集:在小样本数据集上进行训练时,由于批归一化受限于批量大小,可能会引入额外的噪声,而层归一化则能够提供更稳定的表现。
- 序列数据:层归一化在处理序列数据(如自然语言处理中的文本数据)时通常表现较好,因为它对不同样本的特征进行归一化处理,而不受序列长度的影响。
- 生成模型:在生成模型中,如生成对抗网络(GAN)和变分自编码器(VAE)等,层归一化通常比批归一化更适用,因为它提供了更稳定的训练和更一致的生成结果。
Q:快速倒数平方根算法?
A:主要思想是通过近似计算倒数的平方根,以减少计算开销。常见的快速倒数平方根算法,即牛顿迭代法(Newton’s method):
给定一个实数 x,我们希望求它的倒数的平方根,即 1/√x。
- 初始化一个初始近似值 y。
- 迭代计算新的近似值:y = y * (1.5 - 0.5 * x * y * y),重复这个过程直到收敛(通常通过设定迭代次数或者设定一个收敛条件来判断)。
- 最终得到的 y 就是 x 的倒数的平方根的近似值。
这个算法的关键在于,它通过迭代逼近来计算倒数的平方根,而不是直接进行精确的计算。牛顿迭代法的优点在于它的收敛速度通常很快,尤其是对于简单的函数形式而言。
Q:GELU与RELU?
A:神经网络中常见的激活函数,用于神经网络的非线性变换。
- ReLU(修正线性单元):
- ReLU函数定义为 f(x) = max(0, x)。即当输入大于0时,输出为输入值;当输入小于等于0时,输出为0。
- ReLU的优点包括简单、计算高效,且能够缓解梯度消失问题,使神经网络更易于训练。
- 但是,ReLU存在一个称为“神经元死亡”问题的缺点,即当输入小于等于0时,对应的神经元的梯度为0,导致这些神经元在后续训练中无法更新权重。
- GELU(高斯误差线性单元):
- GELU函数定义为 f(x) = 0.5 * x * (1 + tanh(sqrt(2/pi) * (x + 0.044715 * x^3)))。GELU在ReLU的基础上引入了高斯误差函数的形式,使其近似一个非线性激活函数。
- GELU的优点是在一些任务上表现更好,尤其是在自然语言处理等领域,它的光滑性和非饱和性使得在训练中更加稳定,有时候可以获得更好的性能。
- 但是,GELU相对于ReLU来说计算量更大,可能会增加训练和推理的时间成本。
DSP时钟倍频与INT8乘法并行计算方法?