import numpy as np
from sklearn.datasets import load_iris
import pandas as pd
arr = load_iris()
data = arr.data
target = arr.target
print(target)
n_target = target.reshape(len(target),1)print(n_target)
n_data = np.hstack([data,n_target])print(n_data)
columns = arr.feature_names
print(columns)
columns.append('Target')print(columns)
Data = pd.DataFrame(n_data,columns=columns)print(Data)from sklearn.datasets import fetch_20newsgroups
# data_home:数据集存储位置,subset:'train','test','all'分别代表训练/测试/全部数据集
data = fetch_20newsgroups(data_home='src')# 打开excel和csv文件import pandas as pd
data = pd.read_csv('src/ss.csv')
data1 = pd.read_excel('src/test.xlsx')print(data,'\n',data1)## 数据集的划分#import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
arr = load_iris()
data = arr.data
target = arr.target
# *arrays:特征或目标,train_size/test_size:划分比例(0-1或整数),random_state:固定随机数种子,stratify:分层,保证train和test中包括数据库中所有的类别样本
x_train, x_test, y_train, y_test = train_test_split(data,target,train_size=0.8,stratify=target,random_state=6)print(x_train)print(y_test)# 二维数组划分只改变第一维度,不改变第二维度
arr1 = np.arange(1,16,1).reshape(5,3)
np_train,np_test = train_test_split(arr1,train_size=0.8)print(np_train)# DataFrame划分后还是DataFrame
arr1 = np.arange(1,16,1).reshape(5,3)
data = pd.DataFrame(arr1)
pd_train,pd_test = train_test_split(data,train_size=0.8)print(pd_train)from sklearn.feature_extraction import DictVectorizer
data =[{'city':'成都','age':30,'temperature':20},{'city':'重庆','age':33,'temperature':60},{'city':'北京','age':42,'temperature':80},{'city':'上海','age':22,'temperature':70},{'city':'成都','age':72,'temperature':40},]# 直接对字典划分得到的数据集还是原格式
x_train,x_test = train_test_split(data,train_size=0.8)print(x_train)# 使用DictVectorizer提取特征
transfer = DictVectorizer(sparse=True)#sparse:是否将数据集转换成三元组形式
data_new = transfer.fit_transform(data)print("data_new:\n", data_new)
x = data_new.toarray()#将三元组转为ndarrayprint(type(x))print(x)
x_train,x_test = train_test_split(x,train_size=0.8,random_state=6)print(x_train)
2.特征提取
# 字典列表特征提取from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data =[{'city':'北京','money':38,'age':20},{'city':'上海','money':60,'age':29},{'city':'深圳','money':30,'age':32},{'city':'深圳','money':40,'age':49},]# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=False)#sparse是否转换成三元组形式
data = model.fit_transform(data)print(data,type(data))print(model.get_feature_names_out())#获取所有的特征名称
ddata = pd.DataFrame(data=data,columns=model.get_feature_names_out())# print(ddata)
ddata
# 字典列表特征提取from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data =[{'city':'北京','money':38,'age':20},{'city':'上海','money':60,'age':29},{'city':'深圳','money':30,'age':32},{'city':'深圳','money':40,'age':49},]# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=True)#sparse是否转换成三元组形式
data = model.fit_transform(data)print(data,type(data))
arr = data.toarray()#把三元组(稀疏矩阵)转化为数组print(arr)
# 文本特征提取from sklearn.feature_extraction.text import CountVectorizer
corpus =['I love machine learning. Its awesome.','Its a book amazon book.','Amazon is book great company']# 创建一个词频提取对象
vectorizer = CountVectorizer(stop_words=['amazon'])# 提取词频
x = vectorizer.fit_transform(corpus)print(x)print(x.toarray())print(vectorizer.get_feature_names_out())
# 中文文本特征提取from sklearn.feature_extraction.text import CountVectorizer
import jieba
import pandas as pd
# arr = list(jieba.cut('我爱北京天安门'))# print(arr)# str1 = ' '.join(arr)# print(str1)#传入的文本(没有断词的字符串)用jieba分词工具转化为数据容器,然后再把数据容器中的元素连接成字符串defmycut(text):return' '.join(jieba.cut(text))corpus =['我爱北京天安门','我爱成都天府']# # 创建一个词频提取对象
vectorizer = CountVectorizer(stop_words=[])# # 提取词频
data =[mycut(el)for el in corpus]print(data)
x = vectorizer.fit_transform(data)print(x)print(x.toarray())print(vectorizer.get_feature_names_out())
ddata = pd.DataFrame(x.toarray(),columns=vectorizer.get_feature_names_out())
ddata
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizerdefcut_words(text):return" ".join(list(jieba.cut(text)))data =["教育学会会长期间,坚定支持民办教育事业!","扶持民办,学校发展事业","事业做出重大贡献!"]
data_new =[cut_words(v)for v in data]transfer = TfidfVectorizer(stop_words=['期间','做出',"重大贡献"])
data_final = transfer.fit_transform(data_new)pd.DataFrame(data_final.toarray(), columns=transfer.get_feature_names_out())
# TfidfVectorizer TF-IDF文本特征词的重要程度特征提取from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
import pandas as pd
defmycut(text):return' '.join(jieba.cut(text))
data =["教育学会会长期间,坚定支持民办教育事业!","扶持民办,学校发展事业","事业做出重大贡献!"]
data =[mycut(i)for i in data]# print(data)
transfer = TfidfVectorizer(stop_words=[])
res = transfer.fit_transform(data)print(transfer.get_feature_names_out())print(res.toarray())ddata = pd.DataFrame(res.toarray(),columns=transfer.get_feature_names_out())
ddata
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
scaler = MinMaxScaler(feature_range=(0,1))
data = pd.read_excel('src/test2.xlsx')print(data.values)# arr = scaler.fit_transform(data.values)
arr = scaler.fit_transform(data)print(arr)
# 字典列表特征提取from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
data =[{'city':'北京','money':38,'age':20},{'city':'上海','money':60,'age':29},{'city':'深圳','money':30,'age':32},{'city':'深圳','money':40,'age':49},]# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=True)#sparse是否转换成三元组形式
data = model.fit_transform(data)print(data,type(data))
arr = data.toarray()#把三元组(稀疏矩阵)转化为数组print(arr)
arr1 = MinMaxScaler().fit_transform(arr)
arr1
from sklearn.preprocessing import StandardScaler
import numpy as np# 初始化标准化工具
scaler = StandardScaler()
np.random.seed(7)
data = np.random.randint(0,100,(30,4))# print(data)
x = scaler.fit_transform(data)print(x)
# fit 和 transfer 和 fit_transform的区别from sklearn.preprocessing import StandardScaler,MinMaxScaler
import numpy as np
np.random.seed(666)
transfer = StandardScaler()
x = np.random.randint(100,size=(3,4))print(x)# y = transfer.fit_transform(x)
transfer.fit(x)#计算均值和标准差
x = transfer.transform(x)print(x)
x2 = np.array([[10,20,30,40]])
y = transfer.transform(x2)print(y)
# 低方差过滤from sklearn.feature_selection import VarianceThreshold
transer = VarianceThreshold(threshold=0.01)
x =[[0,2,0,3],[0,1,4,3],[0,1,1,3]]
x = transer.fit_transform(x)print(x)
from scipy.stats import pearsonr
import pandas as pd
data = pd.read_csv('src/factor_returns.csv')print(data)
data = data.iloc[:,1:-2]print(data)
r1 = pearsonr(data["pe_ratio"], data["pb_ratio"])print(r1.statistic)#-0.0043893227799362555 相关性, 负数表示负相关print(r1.pvalue)#0.8327205496590723 正相关性
r2 = pearsonr(data['revenue'], data['total_expense'])print(r2)#PearsonRResult(statistic=0.9958450413136111, pvalue=0.0)
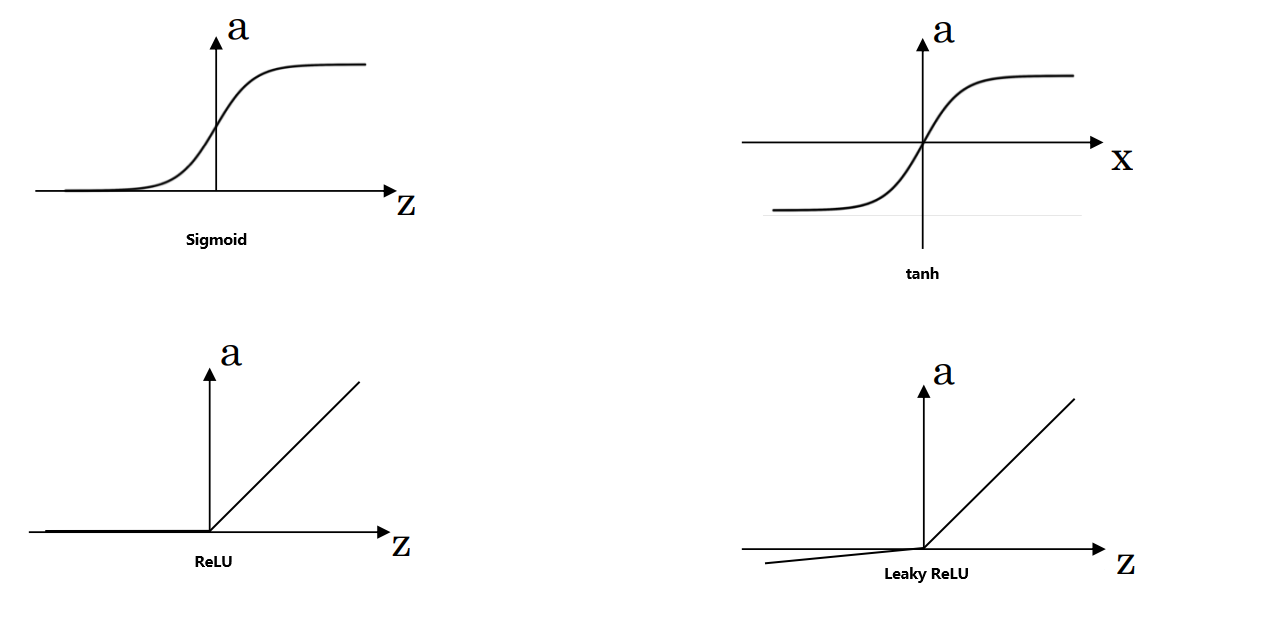
浅层神经网络 浅层神经网络通常指包含一个隐藏层的神经网络。这个网络由输入层、隐藏层和输出层构成: 输入层:输入层负责接收网络的输入特征,通常表示为列向量 x T [ x 1 , x 2 , x 3 ] x^T [x_1, x_2, x_3] xT[x1,x2,x3]ÿ…