嵌入生成 已成为自然语言处理(NLP)中不可或缺的一部分。
无论是智能推荐、文本相似度计算,还是聊天机器人,嵌入技术都扮演着重要角色。然而,我们常常会陷入繁重的库和庞大的模型中,耗时费力。
今天,向大家介绍一款轻量级、快速且高效的 Python 库—FastEmbed。
什么是FastEmbed?
FastEmbed是一个专为文本嵌入而生的轻量级Python库。它的核心优势在于轻量、快速和准确。
🌟 FastEmbed的优势
-
轻量: FastEmbed 是一个轻量级库,几乎没有任何外部依赖项。它不需要 GPU,也不需要下载大内存的 PyTorch 依赖项,而是使用 ONNX 运行。 这使它成为 AWS Lambda 等无服务器运行时的绝佳候选者。
-
快速: FastEmbed 专为速度而设计。它使用 ONNX Runtime,它比 PyTorch 更快,还使用数据并行来编码大型数据集。
-
准确: 它在文本嵌入方面的表现甚至超过了OpenAI的Ada-002模型。这不仅仅是技术上的突破,更是对现有文本处理能力的一次革新。
开发者体验:无痛上手
作为一名开发者,我们最怕的就是那些复杂难懂的工具,有时候为了一个小功能需要配置半天,真的让人抓狂。
而 FastEmbed 的设计理念显然更贴近我们程序员的需求—简单、直观、快速上手。
FastEmbed的安装和使用都非常简便,不需要你翻阅几十页的文档或者费尽心思去解决各种依赖冲突问题。
你只需要简单几步,就可以开始生成高质量的文本嵌入。
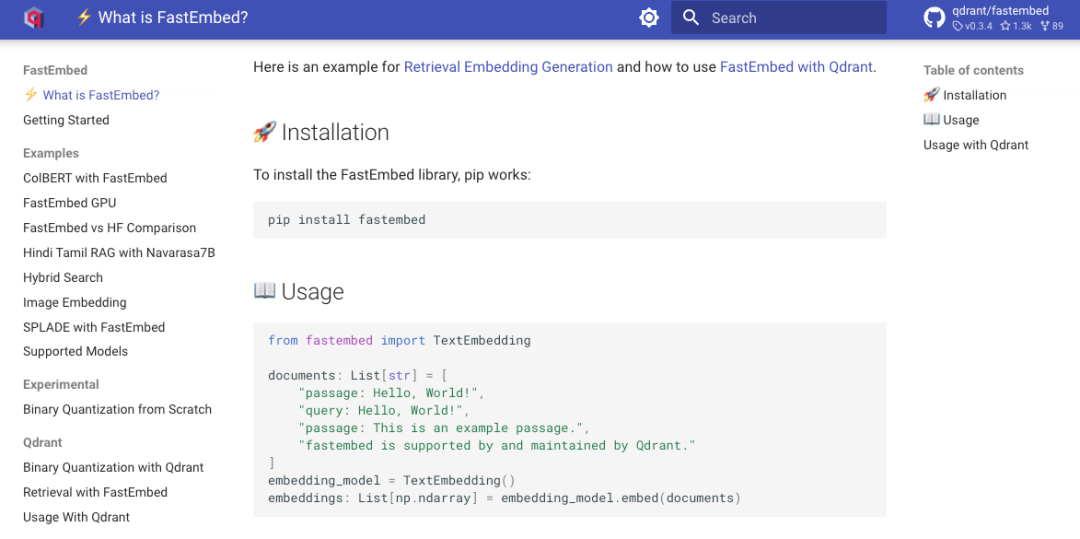
举个例子,安装FastEmbed只需要通过pip进行一行命令,初始化模型的代码也非常简洁明了:
from fastembed import FastEmbed# 初始化FastEmbed并生成嵌入
model = FastEmbed()
embeddings = model.encode(["Demo", "FastEmbed 是个很棒的python库"])
结语
总的来说,FastEmbed作为一款轻量级、快速且准确的嵌入生成工具,完美契合了现代开发者对效率和性能的双重需求。它的轻量设计让我们能够在各种环境下轻松运行模型,快速生成高质量嵌入,而无需担心资源的浪费和依赖问题。
如果你是一个追求高效、想要简化开发流程的程序员,或者你需要在资源受限的环境中部署AI应用,FastEmbed无疑是你的不二选择。
GitHub: https://github.com/qdrant/fastembed