强化学习之父Richard Sutton悄悄搞了个大的,提出了一个简单思路:奖励聚中。这思路简单效果却不简单,等于是给几乎所有的强化学习算法上了一个增强buff,所以这篇论文已经入选了首届强化学习会议(RLC 2024),对于强化学习领域的同学来说,非常值得一读。
其实不止这篇,近年因为大模型的火爆,有关强化学习的研究也算是烫门,在各大顶会顶刊(比如CVPR、Science)上都有成果发表,属实是发文香饽饽了。而且作为实现AGI无可替代的组成部分,强化学习不仅无需标注数据,具有探索性和适应性,同时也拥有强大的泛化能力和实时决策能力,是我们解决复杂现实问题的绝佳选择。
目前关于强化学习的创新主要涉及两个方面:与其他模型结合(比如注意力机制、GNN等)、自身改进(比如层次化、多智能体等)。如果有同学想发表论文,建议从这两点下手,有参考比较好找思路,或者也可以直接看我已经总结好的27个创新方案(有代码)。
全部方案+开源代码需要的同学看文末
与其他模型结合
将强化学习与其他类型的模型结合是比较常见的创新思路,这种方法可以提高强化学习的性能和泛化能力。比如深度强化学习,利用神经网络来逼近值函数或策略函数,从而处理高维输入和输出空间的问题。此外,我们还可以考虑将强化学习与注意力机制、GNN等其他技术结合,以进一步提高其性能和效率。
+注意力机制
在强化学习中,智能体需要根据环境状态做出决策,而注意力机制可以通过计算不同状态或动作元素的权重值来突出对决策最重要的信息,帮助智能体提高学习效率和决策质量。两者的结合不仅提升了算法的性能,还扩展了强化学习在复杂环境和任务中的应用范围。
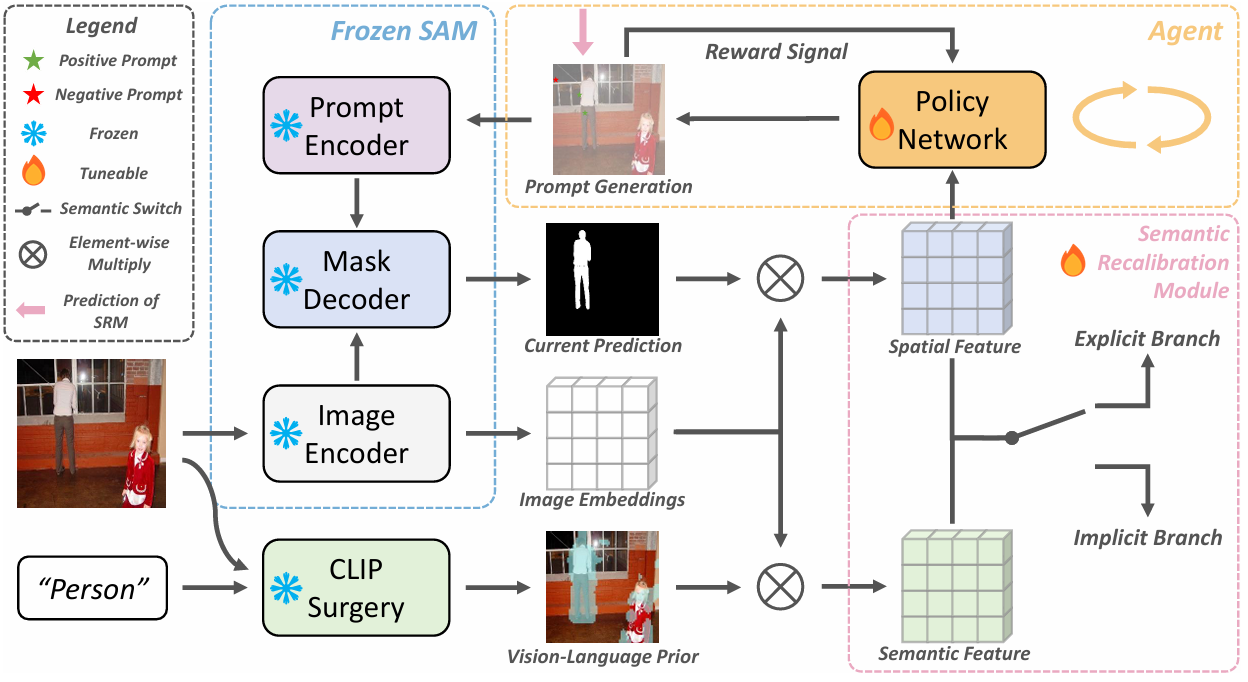
比如AlignSAM框架,核心创新点:
通过强化学习来自动生成提示,以便将SAM适应到开放环境中。这一框架的关键创新包括:1) 利用强化学习代理来迭代优化分割预测,以模拟人类标注者推荐提示位置的过程;2) 引入语义重校准模块,为选定的提示位置提供精确的二元分类标签,增强模型处理包含显式和隐式语义任务的能力。
+图神经网络
一边GNN能深入挖掘图中的模式和关系,另一边强化学习擅长在动态环境中进行序列决策,尤其是在需要长期规划和适应环境变化的情况下。这两者结合,可以开发出能够同时学习图结构表示和做出最优决策的智能模型。
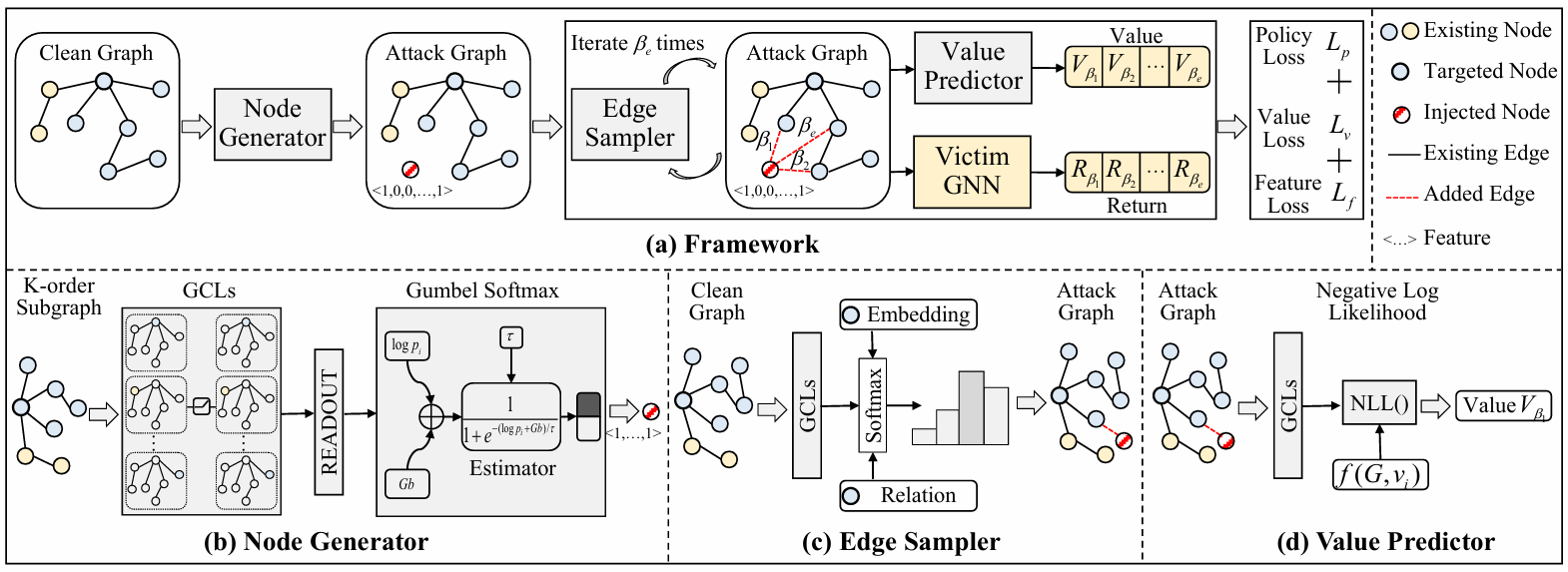
比如G2A2C框架,核心创新点:
G2A2C通过将攻击过程(节点生成和边连接)建模为马尔可夫决策过程,并直接从目标模型查询中学习,避免了依赖于可能误导的替代模型梯度,从而在不牺牲性能的情况下提高了攻击的实用性和有效性。
在节点生成阶段,生成的节点特征既要不引人注意又要具有恶意性;在边连接阶段,根据可学习的条件下概率分布将注入的节点连接到图中的其他节点。
自身改进
另一种创新思路是针对强化学习算法本身进行改进,以提高其收敛速度、稳定性和适应性。比如我们可以研究更高效的探索策略、设计更好的奖励函数,或者开发更鲁棒的策略更新规则等等。此外,我们还可以考虑从理论层面进行改进,比如层次化强化学习和多智能体强化学习。
层次化强化学习
强化学习的一种扩展方法。它将原本单一的强化学习代理划分为多个层次的子代理,每个子代理负责解决问题的不同方面。这种分层结构有助于降低问题的复杂度,让学习过程更加高效。
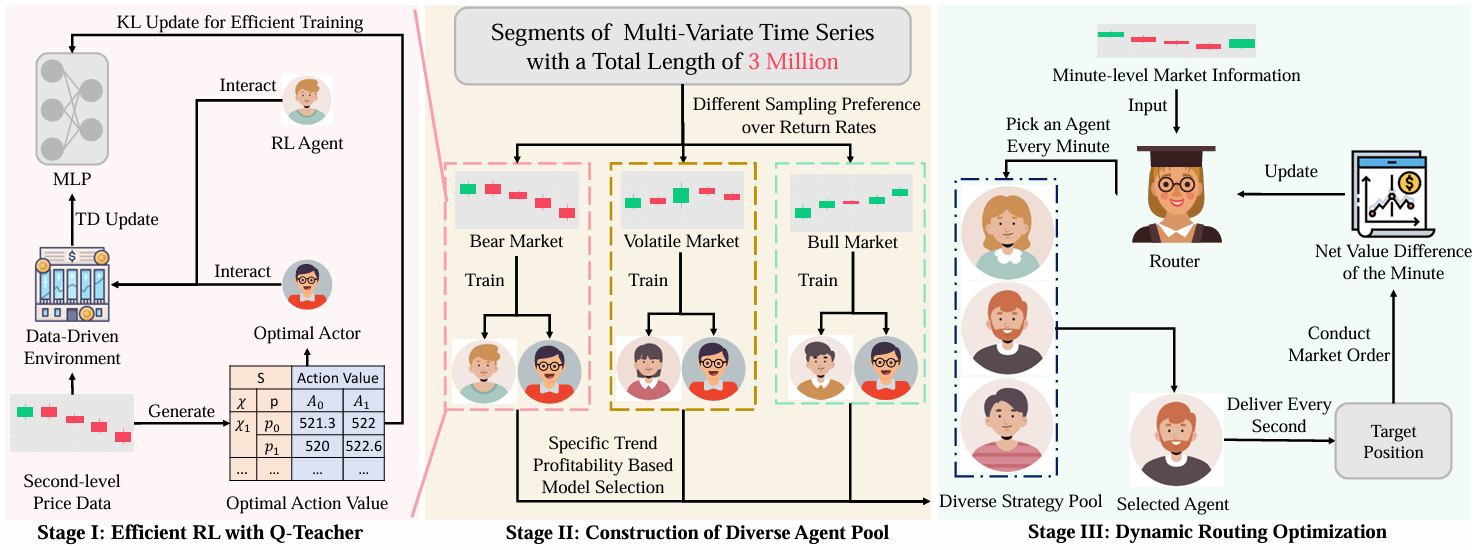
比如EarnHFT层次化强化学习框架,核心创新点:
通过三个阶段来解决HFT中的两个主要挑战:数据效率低下和市场趋势变化剧烈导致的性能下降。EarnHFT通过计算Q-教师来提升训练效率,构建多样化的RL代理池以适应不同的市场趋势,以及训练一个动态路由器来选择适合当前市场状态的代理,从而在高频交易中实现稳定且高效的性能。
多智能体强化学习
强化学习的另一类扩展,专注于多个智能体在共享的环境中学习和决策的场景。与单智能体强化学习相比,它需要额外考虑智能体间的相互作用、协作与竞争等复杂动态。
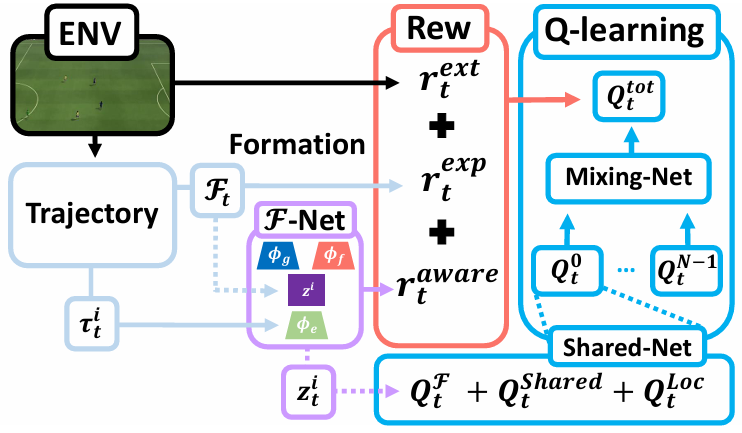
比如FoX框架,核心创新点:
FoX旨在解决多智能体环境中的探索问题,特别是针对部分可观测性和随着智能体数量增加而呈指数级增长的探索空间。FoX引入了一种基于形成的等价关系来缩减多智能体强化学习中的探索空间,并提出了一种形成感知的探索策略,让智能体能够基于局部观察结果有效地识别和访问多样化的形成状态,从而提高在复杂多智能体环境中的探索效率和学习性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“强化改进”获取全部方案+开源代码
码字不易,欢迎大家点赞评论收藏