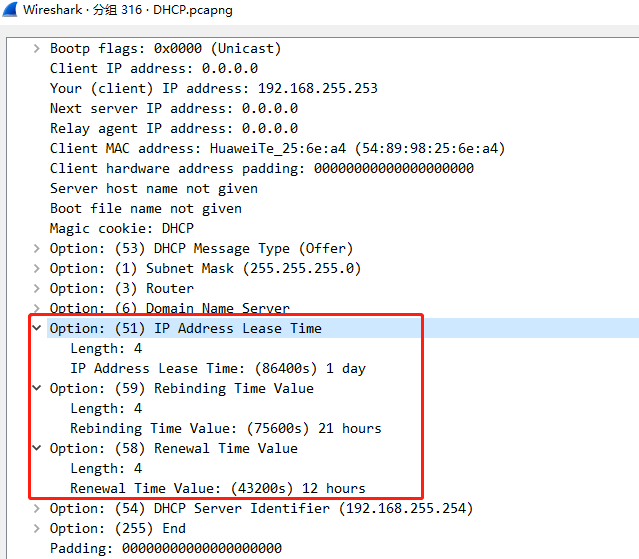
强化学习
- 定义
- 强化学习的核心要素
- 马尔可夫决策过程
- 价值函数
- Bellman 方程
- Q Learning
- 深度Q学习算法 (DQN)
- DQN 的核心思想
- DQN 的工作流程
- 经验回放:(随机抽样)
- 目标网络:
- 损失函数
- 优先级经验回放(Prioritized Experience Replay)
- 优先级经验回放的核心思想
- 优先级经验回放的优势
- 重要概念回顾
定义
强化学习(RL)是一种通过智能体(Agent)与环境(Environment)互动,从而学习最优行为策略的机器学习方法。强化学习的目标是让智能体通过试错的方式获得最大化累积奖励的策略。
- 学会做一系列好的决定
- 只给我们的算法提供一个奖励函数
- 指示学习代理:做得好或不好
强化学习的核心要素
强化学习的核心由四个要素组成:状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。
状态(State, S):描述智能体当前所处的环境信息,帮助智能体判断下一步的决策。例如在迷宫问题中,状态就是当前所在的位置。
动作(Action, A):智能体在某个状态下可以采取的行动。例如在迷宫中,动作可以是“向上”“向下”“向左”“向右”。
奖励(Reward, R):智能体在执行某个动作后,环境给出的反馈,用来指导行为。奖励可以是正数(鼓励行动)或负数(惩罚行动)。
策略(Policy, π):策略是智能体在每个状态下选择动作的规则或函数。策略的目标是让智能体在环境中获得最大的长期累积奖励。策略可以是概率分布(随机策略)或确定性规则(确定性策略)
马尔可夫决策过程
RL代理(智能体)可能包括以下一个或多个组件:
- 策略:代理的行为函数
- 价值函数:每个状态和/或动作有多好
- 模型:agent对环境的表示
MDP通常通过五元组 (S, A, R, P ,y) 来表示:
S: 表示所有可能的状态的集合
A: 所有可能动作的集合。
R:执行动作后得到的即时奖励。
P:在状态s下执行动作a,转移到下一个状态s’的概率。
y: 折扣因子,用来确定未来奖励的价值,低的y更关注当前的奖励,高的y更关注长期回报
在马尔可夫决策过程中, 假设只需要关注当前状态就可以决定下一步, 不依赖于更早的历史
价值函数
价值函数用来衡量智能体在某一个策略下的特殊状态或行动的预期回报,根据状态或者行动分成
状态值函数:
V Π ( s ) = E ∑ t > = 0 y t r t ∣ s 0 = s , Π ∣ V^Π(s) = E\sum_{t>=0}y^tr_t |s_0 = s, Π| VΠ(s)=Et>=0∑ytrt∣s0=s,Π∣
动作值函数:
Q Π ( s , a ) = E [ ∑ t > = 0 y t r t ∣ s 0 = s , a 0 = a , Π ] Q^Π(s,a) = E[\sum_{t>=0}y^t r_t|s_0=s, a_0 =a,Π] QΠ(s,a)=E[t>=0∑ytrt∣s0=s,a0=a,Π]
两个函数都用来获得期望累计奖励。
Bellman 方程
定义Q*(s,a)为最优的Q值方程。

和动作值函数做区分, 这里表示的是在所有可能的策略中, 而动作值函数表示的是在特定的策略下
价值函数的计算通常基于贝尔曼方程,通过递归的方式计算出各个状态的价值。
Q Learning
Q-Learning 是强化学习中最常用的算法之一。它的目标是找到一个最优的 Q 函数 𝑄*(s,a),表示在状态 s 下选择动作 a 时,所能获得的最大期望累积奖励。
Q-Learning 的核心更新公式为


终止: 若达到固定回合数, 或者Q表中所有的Q值变化都很小了, 小于某个阈值近似收敛, 则终止算法, Q表中的值作为学习到的最优Q值

在 Q-learning 算法中,Q 矩阵中的每个数值 Q(s,a) 表示在状态 s 选择动作a 后,智能体能够获得的期望累积奖励。这个值综合了即时奖励和未来可能获得的奖励,用于评估该状态-动作对的优劣程度。
更具体地说,Q 矩阵中的数值表示在当前状态选择某个动作后,随着智能体不断沿着最佳策略前进,所能累积得到的总奖励。因此,Q 值越高,意味着该状态-动作对在长期内能够带来的收益越大。Q-learning 训练的目标就是逐步优化这些 Q 值,使得在每个状态选择最佳的动作,以达到最终目标。
深度Q学习算法 (DQN)
在传统的Q学习中, Q值是保存在Q表中的, 这个方法在小规模的, 离散的状态空间中效果好, 但在复杂环境中有以下问题:
- 状态空间大,Q表会变得很大。Q表的size = 状态量*动作量。导致存储和计算资源需求大。
- 连续状态无法用有限的Q表表示。
- 难以泛化。 学习到的信息无法被类似的状态利用。
深度Q学习(DQN)引入了神经网络来近似最优Q值函数
DQN(Deep Q-Network,深度 Q 网络)是 Q-learning 和深度学习相结合的强化学习方法,特别适用于具有大量状态的复杂问题,比如图像输入和高维度空间。
DQN 的核心思想
在传统的 Q-learning 中,我们使用一个 Q 表来存储状态-动作值(Q 值)。但是当状态数量庞大(如图像数据)时,直接用表格来存储并更新 Q 值就不切实际了。DQN 通过使用神经网络来近似 Q 函数,即用神经网络去预测每个状态下的 Q 值,这样可以处理更复杂和高维的状态空间
DQN 的工作流程
输入状态:智能体从环境中获取当前状态信息(比如一张游戏截图)。
神经网络预测 Q 值:将状态输入到神经网络中,网络输出不同动作对应的 Q 值。
选择动作:根据 Q 值选择动作。通常使用 ε-greedy 策略,即有一定概率随机选择动作(探索),其余情况选择 Q 值最高的动作(利用)。
执行动作和观察奖励:在环境中执行动作,获得奖励并观察新的状态。
存储经验:将当前状态、动作、奖励和新状态(即一次交互的所有信息)存储在经验回放缓冲区中。
训练网络:从经验回放缓冲区中随机抽取一些样本,用于训练神经网络,使用的目标值为:

经验回放:(随机抽样)
经验回放(Replay Buffer)用于存储智能体和环境的交互记录。通过在训练时从回放缓冲区随机抽样,可以打破数据的相关性,提高训练稳定性。
目标网络:
DQN 使用两个网络:当前 Q 网络和目标网络。目标网络定期同步为当前网络的参数,这样可以在训练中稳定 Q 值的更新,减少发散风险。
DQN 引入了目标网络来提高 Q 值更新的稳定性。目标网络是 DQN 中的一个辅助 Q 网络,它与主 Q 网络结构相同,但其参数(权重)不在每一步都更新。使用目标网络的原因是,在 Q-learning 中直接用当前网络估计的 Q 值会导致更新过程不稳定甚至发散,因为 Q 值的目标值在不断变化。
目标网络的工作方式:
更新方式:目标网络的参数 𝜃- 是当前 Q 网络的参数 θ 的拷贝,但它不是在每次迭代中更新,而是每隔固定的步数(例如每 1000 步)进行一次同步,即将主 Q 网络的参数复制到目标网络中。
稳定性:由于目标网络的 Q 值在更新间隔内是固定的,这种做法能减缓目标值的波动,减少发散的风险,提升 Q 值估计的稳定性。
损失函数
DQN 的目标是让 Q 值(通过神经网络估算)逼近真实的期望回报。为了实现这一点,DQN 使用一个基于 Bellman 方程的损失函数,使 Q 值在每次更新后更接近目标值。具体来说:
DQN 的损失函数定义为

优先级经验回放(Prioritized Experience Replay)
是 DQN 的一种改进技术,旨在更高效地使用经验数据,加速训练和提高性能。它是在经验回放(Experience Replay)的基础上提出的,通过赋予不同的经验样本不同的优先级,让那些对学习影响更大的样本被优先使用,从而更有效地更新 Q 网络。
在传统的经验回放中,经验回放缓冲区(Replay Buffer)中储存智能体与环境的所有交互经验,训练时从中随机抽取样本来更新 Q 网络。这种随机抽样的方法可以打破数据相关性,提高训练的稳定性,但它没有考虑样本的重要性,因此效果可能不够高效。优先级经验回放解决了这一问题。
优先级经验回放的核心思想
在优先级经验回放中,每条经验(即状态转移样本 (s,a,r,s ‘) )会被赋予一个优先级,优先级的大小由这条经验对学习的影响程度决定。具体来说,优先级通常由样本的TD误差(Temporal Difference Error,时间差误差)决定。
TD 误差的定义为:

TD 误差:表示当前 Q 值与目标 Q 值的差距。误差大的样本表明智能体的估计与实际奖励存在较大偏差,说明这类样本对改进 Q 值估计更有帮助,因此应该优先使用。

优先级经验回放的优势
- 更快的收敛速度:优先级高的样本优先被抽取和更新,使模型更快纠正大误差样本,提升学习效率。
- 更好的性能:DQN 通过优先级经验回放可以更高效地学习到最优策略,尤其在复杂任务中比随机抽样的方式有显著改进。
重要概念回顾
- state-value函数衡量的是当前的状态在遵循Policy的预期累积回报; action-value函数是在当前状态下采取行动后遵循Policy的预期累积回报
- 最优Q函数就是在所有可能的Policy中, 最大的预期累积回报. 最优Q函数遵循Bellman方程, Q*等于即时回报和将来回报乘以折扣因子
- Q-Learning对Q表的每个Q值进行增量更新(使用Bellman),得到Q表中所有值近似收敛于最佳Q值
- 在每轮迭代中, 利用ϵ调控探索/利用选择动作, 并维护一个记忆池打破和时间的相关性, 从记忆池中均匀采样然后反向传播更新Q网络的权重,并且为了防止目标Q值计算的不稳定, 我们引入一个Q网络
- 强化学习不需要标签数据(不像监督学习需要每条数据的正确输出)
需要奖励信号来评估行为的效果,这种反馈可以是即时的(每一步都有)或延迟的(如在完成任务后才有)。
这种奖励机制使得强化学习可以用于解决很多动态和长期决策的问题,比如游戏、机器人控制等。 - 与监督学习比的优缺点:
优点:
a. 适合长期策略优化:强化学习的目标是最大化长期回报,因此适合解决需要综合考虑多个步骤或延迟奖励的任务,如路径规划、资源分配等。监督学习只关注单步预测:监督学习通常只能进行单步预测,无法优化长期策略,不适合动态任务和需长期规划的场景。
b. 无需标签数据:强化学习依靠环境反馈的奖励信号,而不需要大规模标注数据,适合那些难以标注的任务。
c. 自适应性强:RL在动态和复杂的环境中可以自动调整和优化策略,使其在未知环境中更具适应性
缺点:
a. 数据效率低:智能体需要大量试错来学习策略,训练过程较长,尤其是在高维或复杂任务中
b. 奖励设计难度高:需要设计合理的奖励机制,不合理的奖励信号可能导致智能体学到次优或不符合预期的行为。
c. 准确率可能更低
d. 对比部分高解释性监督学习模型(决策树),解释性低。 - 与无监督学习对比的优缺点:
- 无监督不适合做决策任务,通常是发现数据模式或者聚类结构。
- 强化学习适合长期策略优化
- 计算需求相对更高。