Transformer 是一种彻底改变人工智能方法的神经网络架构。它首次在 2017 年的里程碑式论文 "Attention is All You Need"[1] 中被提出,并迅速成为深度学习模型的首选架构,为 OpenAI 的 GPT、Meta 的 Llama 和 Google 的 Gemini 等文本生成模型提供动力。除了文本之外,Transformer 还应用于 音频生成[2]、图像识别[3]、蛋白质结构预测[4] 甚至 游戏[5] 等领域,展现了其跨多个领域的通用性。
Transformer 的工作原理 从根本上说,文本生成 Transformer 模型基于 下一个词预测 的原则运作:给定用户输入的文本提示,那么 最有可能跟随这个输入的下一个词是什么?Transformer 的核心创新和强大之处在于其使用自注意力机制,这使得它能够更有效地处理整个序列并捕获比之前架构更长的依赖关系。GPT-2 系列模型是文本生成 Transformer 的突出例子。Transformer 解释器由 GPT-2[6] (小型) 模型提供动力,该模型拥有 1.24 亿个参数。虽然它不是最新或最强大的 Transformer 模型,但它与当前最先进模型中发现的许多相同的架构组件和原理共享,使其成为理解基础知识的理想起点。 Transformer 架构 每个文本生成 Transformer 都由以下 三个关键组件 组成:
-
1. Embedding: 将文本输入分解为称为 token 的较小单元,可以是单词或子词。这些 token 被转换为称为Embedding的数值向量,这些向量捕获单词的语义含义。
-
2. Transformer 块: 是模型处理和转换输入数据的基本构建块。每个块包括:
-
• 注意力机制: Transformer 块的核心组件。它允许 token 与其他 token 通信,捕获单词之间的上下文信息和关系。
-
• MLP (多层感知器) 层: 一个前馈网络,独立地对每个 token 进行操作。注意力层的目的是在 token 之间路由信息,而 MLP 的目的是细化每个 token 的表示。
-
-
3. 输出概率: 最后的线性层和 softmax 层将处理过的Embedding转换为概率,使模型能够对序列中的下一个 token 进行预测。
Embedding
假设您想使用 Transformer 模型生成文本。您像这样添加提示:Data visualization empowers users to。这个输入需要转换为模型可以理解和处理的格式。这就是Embedding发挥作用的地方:它将文本转换为模型可以处理的数值表示。要将提示转换为Embedding,我们需要 1) 对输入进行分词,2) 获取 token Embedding,3) 添加位置信息,最后 4) 将 token 和位置编码相加以获得最终Embedding。让我们看看每个步骤是如何完成的。
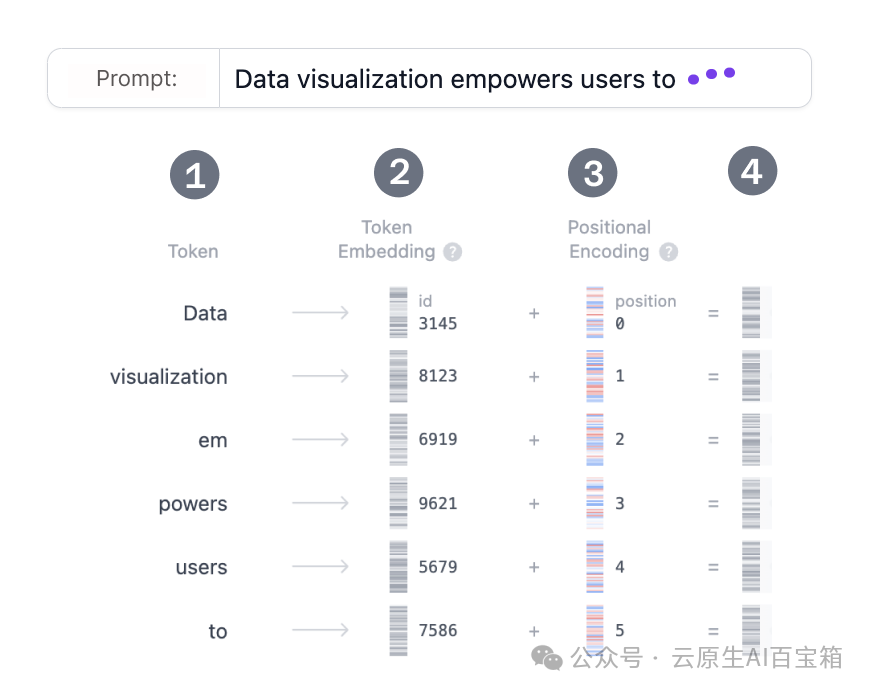
图 1. 展开Embedding层视图,显示如何将输入提示转换为向量表示。该过程涉及 (1) 分词,(2) token Embedding,(3) 位置编码,最后 (4) 最终Embedding。
步骤 1:分词
分词是将输入文本分解成称为 token 的较小、更易于管理的片段的过程。这些 token 可以是单词或子词。"数据" 和 "可视化" 对应于唯一的 token,而单词 "赋能" 被分成两个 token。模型训练之前确定了 token 的完整词汇表:GPT-2 的词汇表有 50,257 个独特的 token。现在,我们已经将输入文本分解为具有不同 ID 的 token,我们可以从Embedding中获取它们的向量表示。
步骤 2:token Embedding
GPT-2 小型将词汇表中的每个 token 表示为 768 维向量;向量的维度取决于模型。这些Embedding向量存储在形状为 (50,257, 768) 的矩阵中,包含约 3900 万个参数!这个庞大的矩阵允许模型为每个 token 分配语义意义。
步骤 3:位置编码
Embedding层还编码每个 token 在输入提示中的位置信息。不同的模型使用各种方法进行位置编码。GPT-2 从零开始训练自己的位置编码矩阵,并将其直接集成到训练过程中。
步骤 4:最终Embedding
最后,我们将 token 和位置编码相加以获得最终Embedding表示。这种组合表示既捕获了 token 的语义含义,也捕获了它们在输入序列中的位置。
云原生AI百宝箱
行万里路,此处相逢,共话云原生AI之道。 偶逗趣事,明月清风,与君同坐。
69篇原创内容
公众号
Transformer 块
Transformer 处理的核心在于 Transformer 块,它由多头自注意力和多层感知器层组成。大多数模型都由多个这样的块顺序堆叠而成。token 表示在层中演变,从第一个块到第 12 个块,使模型能够对每个 token 建立复杂的理解。这种分层方法导致输入的更高阶表示。
多头自注意力
自注意力机制使模型能够关注输入序列的相关部分,从而捕获数据中的复杂关系和依赖关系。让我们一步一步地看看自注意力是如何计算的。
步骤 1:查询、键和值矩阵

图 2. 从原始Embedding中计算查询、键和值矩阵。每个 token 的Embedding向量被转换为三个向量:查询 (Q)、键 (K) 和值 (V)。这些向量是通过将输入Embedding矩阵与 Q、K 和 V 的学习权重矩阵相乘来获得的。这里有一个网络搜索的类比,帮助我们建立对这些矩阵背后直觉的了解:
-
• 查询 (Q) 是您在搜索引擎栏中输入的搜索文本。这是您想要 "查找更多关于" 的 token。
-
• 键 (K) 是搜索结果窗口中每个网页的标题。它代表查询可以关注的可能 token。
-
• 值 (V) 是实际显示的网页内容。一旦我们匹配了适当的搜索词 (查询) 与相关的结果 (键),我们就想要获取最相关页面的内容 (值)。通过使用这些 QKV 值,模型可以计算注意力分数,这些分数决定了每个 token 在生成预测时应获得多少关注。
步骤 2:掩码自注意力
掩码自注意力允许模型通过关注输入的相关部分来生成序列,同时防止访问未来的 token。
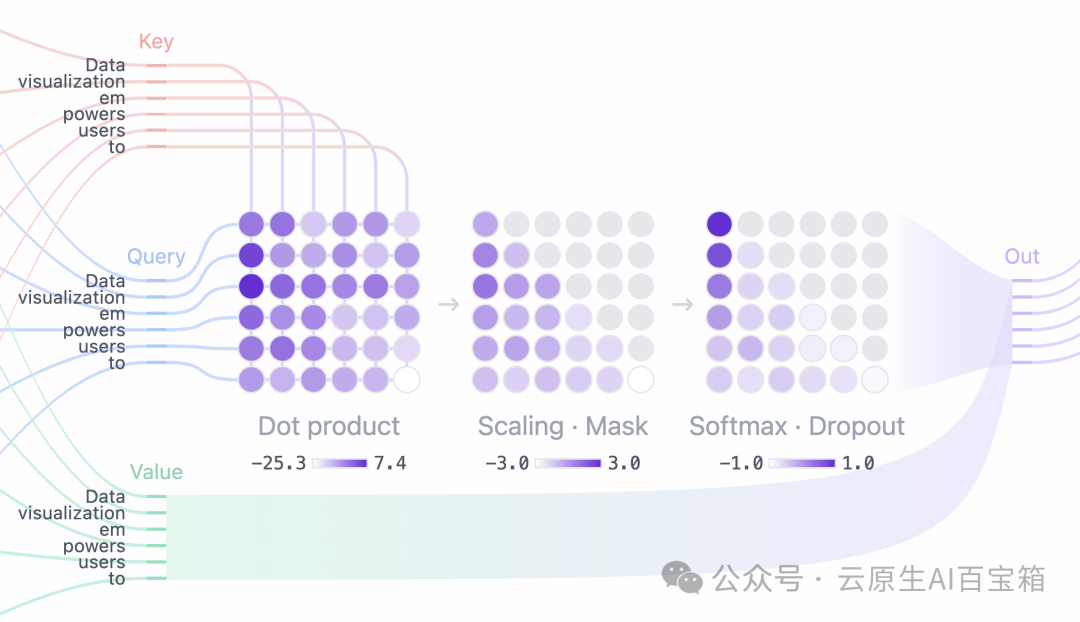
图 3. 使用查询、键和值矩阵来计算掩码自注意力。
-
• 注意力分数: 查询和键矩阵的点积决定了每个查询与每个键的对齐,产生一个正方形矩阵,反映了所有输入 token 之间的关系。
-
• 掩码: 一个掩码应用于注意力矩阵的上三角,将模型无法访问的未来 token 的值设置为负无穷大。模型需要学习如何在不 "偷看" 未来的情况下预测下一个 token。
-
• Softmax: 掩码后,注意力分数通过 softmax 操作转换为概率,该操作对每个注意力分数取指数。矩阵的每一行总和为 1,并指示每个其他 token 对其左侧每个 token 的相关性。
步骤 3:输出
模型使用掩码自注意力分数并将其乘以值矩阵,以获得自注意力机制的最终输出。GPT-2 有 12 个自注意力头,每个头捕获 token 之间不同的关系。这些头的输出被连接并通过线性投影传递。
MLP:多层感知器
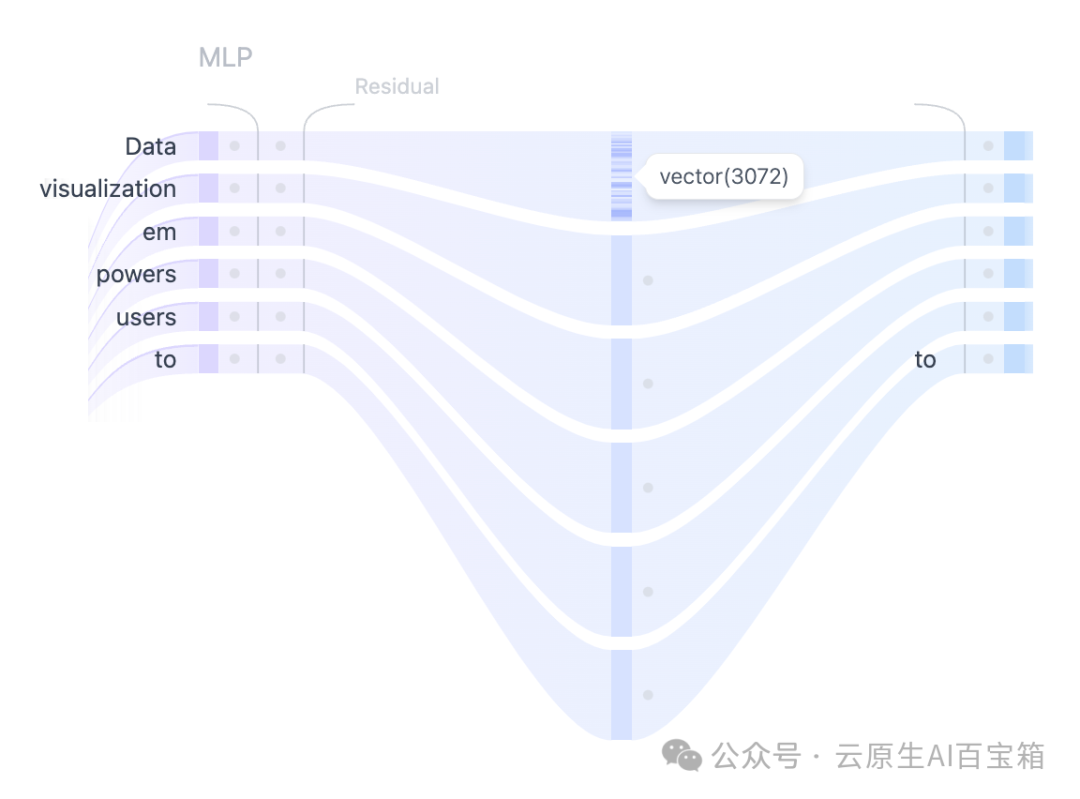
图 4. 使用 MLP 层将自注意力表示投影到更高维度,以增强模型的表示能力。在多个自注意力头捕获输入 token 之间的不同关系之后,连接的输出被传递到多层感知器 (MLP) 层以增强模型的表示能力。MLP 块由两个线性变换组成,中间有一个 GELU 激活函数。第一个线性变换将输入的维度从 768 倍增加到 3072。第二个线性变换将维度减少到原始大小 768,确保后续层接收一致维度的输入。与自注意力机制不同,MLP 独立地处理 token,并简单地将它们从一个表示映射到另一个表示。
输出概率
输入经过所有 Transformer 块处理后,输出通过最后的线性层以准备 token 预测。该层将最终表示投影到一个 50,257 维的空间中,其中词汇表中的每个 token 都有一个相应的值称为 "logit"。任何 token 都可以是下一个词,因此此过程允许我们简单地根据其成为下一个词的可能性对这些 token 进行排序。然后我们对 logits 应用 softmax 函数将其转换为概率分布,该分布总和为 1。这将允许我们根据其可能性对下一个 token 进行采样。
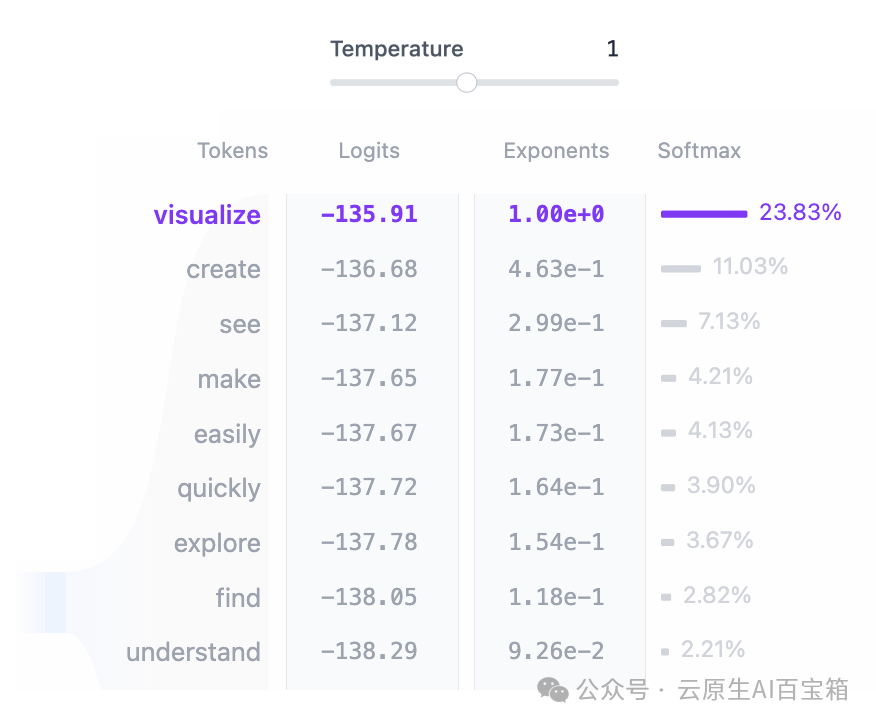
图 5. 词汇表中的每个 token 根据模型的输出 logits 被分配一个概率。这些概率决定了每个 token 成为序列中下一个词的可能性。最后一步是通过从这个分布中进行采样来生成下一个 token。temperature 超参数在此过程中起着关键作用。从数学上讲,它是一个非常简单的操作:将模型输出 logits简单地除以temperature:
-
•
temperature = 1:将 logits 除以 1 对 softmax 输出没有影响。 -
•
temperature < 1:较低的temperature使模型更加自信和确定,通过锐化概率分布来导致更可预测的输出。 -
•
temperature > 1:较高的temperature创建一个更软的概率分布,允许生成的文本中有更多的随机性——一些人称之为模型的 “创造力”。调整temperature并看看您如何可以在确定性和多样性之间取得平衡!
行万里路,此处相逢,共话云原生AI之道。 偶逗趣事,明月清风,与君同坐。
Transformer 架构高级功能
有几个高级架构功能增强了 Transformer 模型的性能。虽然对于理解架构的核心概念来说,它们并不那么重要,但它们对于模型的整体性能至关重要。层归一化、Dropout 和残差连接是在 Transformer 模型中,尤其是在训练阶段至关重要的组件。
层归一化
层归一化有助于稳定训练过程并提高收敛速度。它通过跨特征归一化输入来工作,确保激活的平均值和方差是一致的。这种归一化有助于缓解与内部协变量偏移相关的问题,使模型能够更有效地学习,并减少对初始权重的敏感性。在每个 Transformer 块中,层归一化应用两次,一次在自注意力机制之前,一次在 MLP 层之前。
Dropout
Dropout 是一种正则化技术,用于通过在训练过程中随机将模型权重设置为 0 来防止神经网络过拟合。这鼓励模型学习更鲁棒的特征,并减少对特定神经元的依赖,从而帮助网络更好地泛化到新的、未见过的数据。在模型推理期间,dropout 被停用。这本质上意味着我们正在使用训练子网络的集成,这导致更好的模型性能。
残差连接
残差连接首次于 2015 年在 ResNet 模型中引入。这项架构创新彻底改变了深度学习,它通过允许训练非常深的神经网络而闻名。本质上,残差连接是绕过一层或多层的捷径,将层的输入添加到其输出中。这有助于缓解梯度消失问题,使得训练堆叠多个 Transformer 块的深层网络变得更容易。在 GPT-2 中,残差连接在 Transformer 块中两次:一次在 MLP 之前,一次之后,确保梯度更容易流动,并且在反向传播期间早期层接收到足够的更新。
Transformer 解释器
Transformer 解释器旨在具有交互性,并允许您探索 Transformer 的内部工作原理。以下是一些您可以使用的交互式功能:
-
输入您自己的文本序列 以查看模型如何处理它并预测下一个词。探索注意力权重、中间计算,并查看最终输出概率是如何计算的。
-
使用temperature滑块 来控制模型预测的随机性。通过更改temperature值,探索您如何可以使模型输出更确定或更具创造性。
-
与注意力图交互 以查看模型如何关注输入序列中的不同 token。悬停在每个 token 上以突出显示其注意力权重,并探索模型如何捕获单词之间的上下文和关系。
引用链接
[1] "Attention is All You Need": https://dl.acm.org/doi/10.5555/3295222.3295349[2] 音频生成: https://huggingface.co/learn/audio-course/en/chapter3/introduction[3] 图像识别: https://huggingface.co/learn/computer-vision-course/unit3/vision-transformers/vision-transformers-for-image-classification[4] 蛋白质结构预测: https://elifesciences.org/articles/82819[5] 游戏: https://www.deeplearning.ai/the-batch/reinforcement-learning-plus-transformers-equals-efficiency/[6] GPT-2: https://huggingface.co/openai-community/gpt2


![[利用python进行数据分析01] “来⾃Bitly的USA.gov数据” 分析出各个地区的 windows和非windows用户](https://i-blog.csdnimg.cn/direct/fb36b41fde154881a78108aac6e73bd9.png)