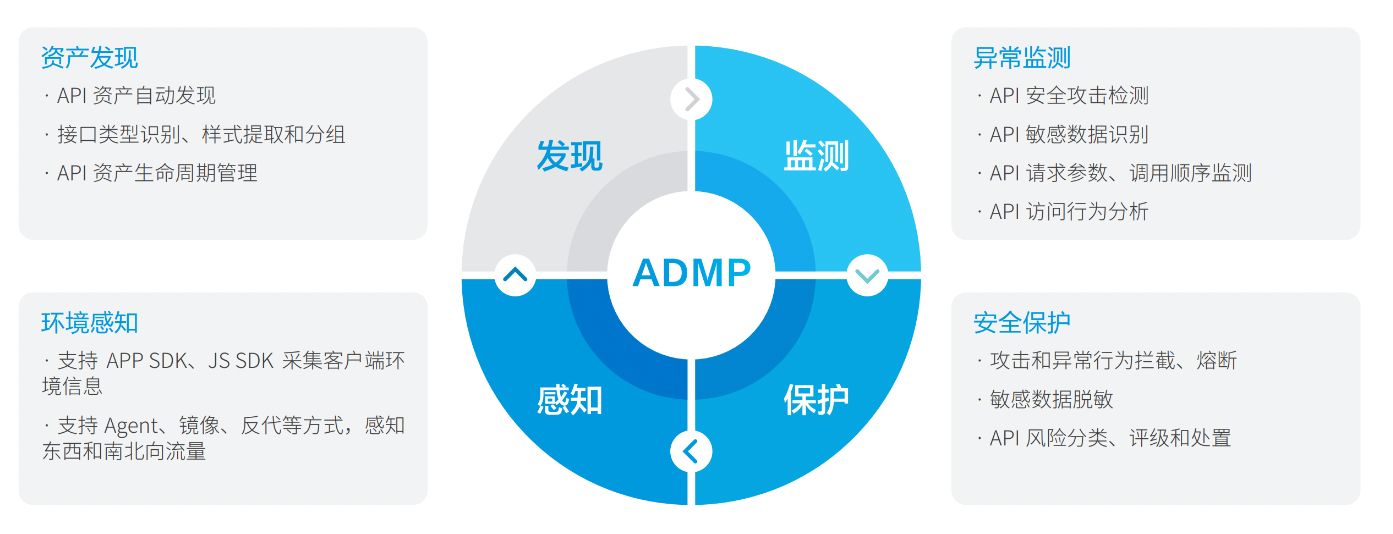
文章目录
- 一、IterativeImputer
- 示例:预测房价数据中的缺失值
- 使用 IterativeImputer`预测缺失值
- 总结
- 二、极端随机树特征选择
一、IterativeImputer
为了帮助理解 IterativeImputer 如何使用其他特征来预测有缺失值的特征,下面给出一个具体的例子。
示例:预测房价数据中的缺失值
假设我们有一个房价数据集,其中包含以下几个特征:
房屋面积(Square footage)房间数量(Number of rooms)建筑年份(Year built)房价(Price)
这个数据集中,房屋面积 和 建筑年份 中存在一些缺失值。
+-------------+-------------+-------------+-------+
| 房屋面积 | 房间数量 | 建筑年份 | 房价 |
+-------------+-------------+-------------+-------+
| 2000 | 3 | 1990 | 300 |
| 1500 | 2 | 1985 | 250 |
| NaN | 4 | 2000 | 450 |
| 2500 | 4 | NaN | 500 |
| 1800 | 3 | 1995 | 320 |
| NaN | 2 | 1980 | 220 |
+-------------+-------------+-------------+-------+
在这个例子中,我们看到:
- 第三行的
房屋面积是缺失值。 - 第四行的
建筑年份是缺失值。 - 第六行的
房屋面积是缺失值。
使用 IterativeImputer`预测缺失值
-
初始化缺失值:
首先,对于有缺失值的特征,IterativeImputer会用简单的方式初始化这些缺失值。比如,用列的均值来填充初始值。假设
房屋面积列的均值是 1950,那么我们会得到:+-------------+-------------+-------------+-------+ | 房屋面积 | 房间数量 | 建筑年份 | 房价 | +-------------+-------------+-------------+-------+ | 2000 | 3 | 1990 | 300 | | 1500 | 2 | 1985 | 250 | | 1950 | 4 | 2000 | 450 | | 2500 | 4 | 1988 (均值)| 500 | | 1800 | 3 | 1995 | 320 | | 1950 | 2 | 1980 | 220 | +-------------+-------------+-------------+-------+ -
迭代预测:
-
预测
房屋面积:
使用完整的特征房间数量、建筑年份和房价来预测房屋面积。这可以通过回归模型(例如线性回归)来完成。比如,对于第三行:
- 使用
房间数量 = 4,建筑年份 = 2000,房价 = 450作为输入,模型预测的房屋面积可能是 2100。 - 更新后为:
+-------------+-------------+-------------+-------+ | 房屋面积 | 房间数量 | 建筑年份 | 房价 | +-------------+-------------+-------------+-------+ | 2000 | 3 | 1990 | 300 | | 1500 | 2 | 1985 | 250 | | 2100 (预测) | 4 | 2000 | 450 | | 2500 | 4 | 1988 (均值)| 500 | | 1800 | 3 | 1995 | 320 | | 1950 | 2 | 1980 | 220 | +-------------+-------------+-------------+-------+ - 使用
-
预测
建筑年份:
使用完整的特征房屋面积、房间数量和房价来预测建筑年份。对于第四行:- 使用
房屋面积 = 2500,房间数量 = 4,房价 = 500作为输入,模型预测的建筑年份可能是 1998。 - 更新后为:
+-------------+-------------+-------------+-------+ | 房屋面积 | 房间数量 | 建筑年份 | 房价 | +-------------+-------------+-------------+-------+ | 2000 | 3 | 1990 | 300 | | 1500 | 2 | 1985 | 250 | | 2100 | 4 | 2000 | 450 | | 2500 | 4 | 1998 (预测)| 500 | | 1800 | 3 | 1995 | 320 | | 1950 | 2 | 1980 | 220 | +-------------+-------------+-------------+-------+ - 使用
-
-
重复步骤 2:
继续迭代,使用最新的预测值作为输入,重复上述步骤,直到模型收敛或者达到最大迭代次数。 -
最终结果:
最终,我们将得到一个没有缺失值的填补数据集。+-------------+-------------+-------------+-------+ | 房屋面积 | 房间数量 | 建筑年份 | 房价 | +-------------+-------------+-------------+-------+ | 2000 | 3 | 1990 | 300 | | 1500 | 2 | 1985 | 250 | | 2100 | 4 | 2000 | 450 | | 2500 | 4 | 1998 | 500 | | 1800 | 3 | 1995 | 320 | | 1950 | 2 | 1980 | 220 | +-------------+-------------+-------------+-------+
总结
IterativeImputer 通过不断迭代,使用完整的特征预测缺失的特征,逐步提高填补值的准确性。这种方法尤其适用于特征之间有较强相关性的场景,使得填补后的数据能够保留更多的原始结构信息。
二、极端随机树特征选择
随机选择特征通过在每个节点随机选择不同的特征来确保模型不会过度依赖某些特征,从而增加了决策树的多样性和抗噪声能力。
随机选择分裂点则在进一步细化选择特征后的分裂策略,确保即使同一个特征被选择,不同的树也可能根据不同的分裂点做出不同的决策,从而进一步增加模型的多样性。
特征重要性得分的计算方法
特征重要性得分衡量了每个特征在决策树中作为分裂点时对模型整体性能提升的重要性。在极端随机树中,特征重要性得分通常基于以下方法计算:
基于节点分裂的特征重要性
- 信息增益或Gini impurity的减少:
- 在决策树中,每次分裂节点时会计算这个节点的某个度量值(如 Gini impurity 或 信息增益)的减少量。这个减少量越大,意味着该特征在此节点上的分裂对分类结果的贡献越大。
- 在极端随机树中,尽管分裂点是随机选择的,仍然可以计算每次分裂所带来的 Gini impurity 的减少量。对于每个特征,计算其在所有树中作为分裂点时的减少量的总和。
- 特征的重要性得分:
- 对于每棵树来说,特征重要性是通过累计该特征在树中所有分裂节点的 Gini impurity 减少量得到的。所有树中的特征重要性得分再取平均,得到最终的特征重要性。
- 特征重要性得分越高,表明该特征对模型预测的贡献越大。