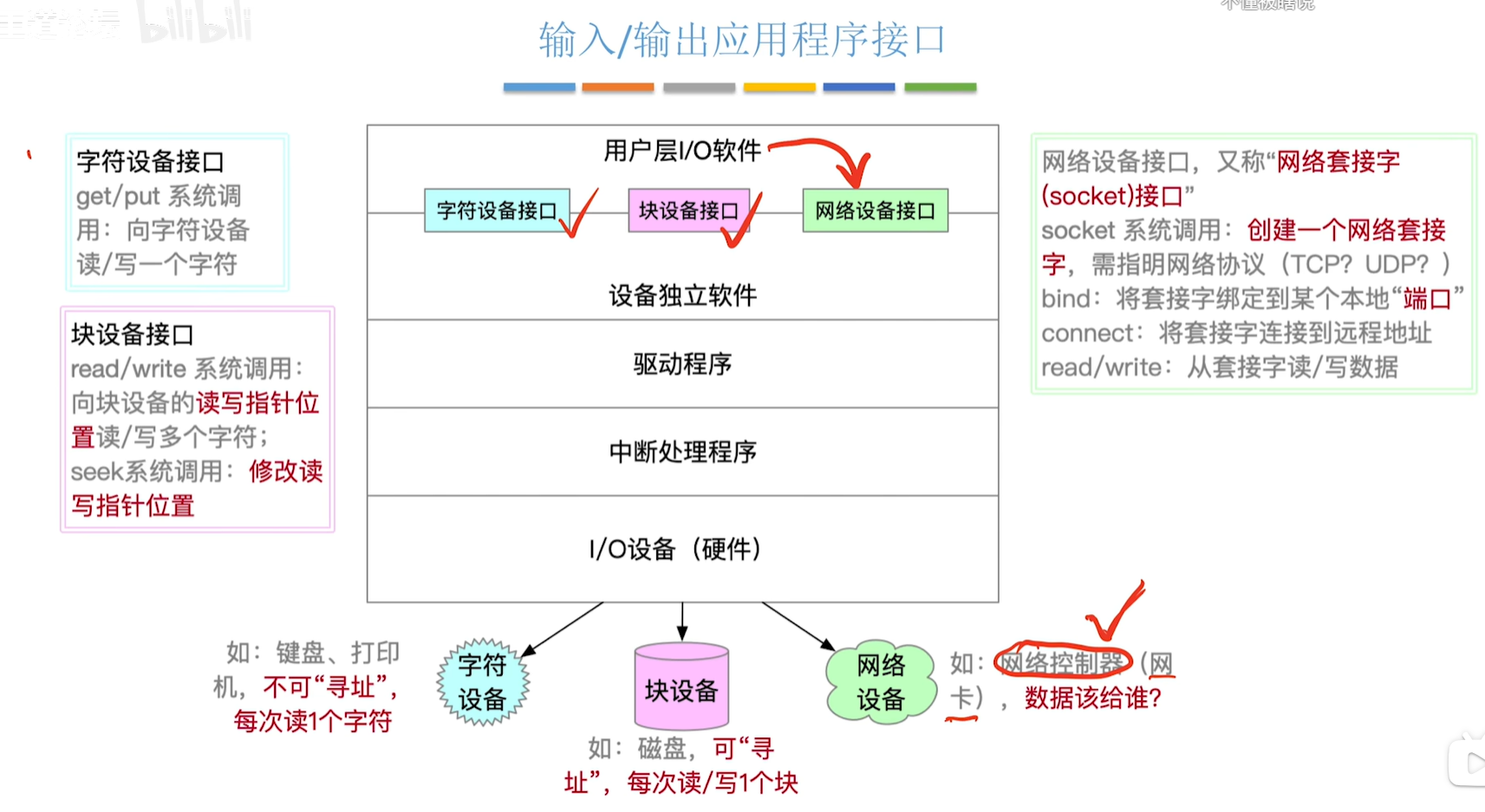
python数据分析 pandas库-数据操作
一、数据新增
1.追加数据
DataFrame.append
-
功能:将行追加到 DataFrame 中。
-
用法:
df.append(other:其他DataFrame对象, ignore_index=False:用于重置DataFrame的原所有索引,False表示不重置, verify_integrity=False:当它为Ture时会检测合并后的结果, sort=False:当它为Ture时结果将按照索引或列进行排序)import pandas as pd df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5], 'B': [6]})df = df1.append(df2, ignore_index=True) print(df)
2.扩展数据
DataFrame.assign
-
功能:通过提供的新列来扩展 DataFrame,它与直接修改源DataFrame不一样的点是,会重新返回一个DataFrame对象。
-
用法:
df.assign(**kwargs)df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})# 添加新列 'C' df = df.assign(C=[5, 6]) print(df)
3.插入数据
DataFrame.insert
-
功能:在 DataFrame 中指定位置插入新列。
-
用法:
df.insert(loc:指定新列在 DataFrame 中的位置(索引), column, value, allow_duplicates=False:如果设置为 True,则允许插入的列名称与现有列名重复)df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})# 在位置 1 插入新列 'C' df.insert(1, 'C', [5, 6]) print(df)
4.连接数据
DataFrame.concat
-
功能:沿指定轴连接多个 DataFrame 对象。
-
用法:
pd.concat(objs, axis=0:决定连接的方向,axis=0 表示按行连接(默认),axis=1 表示按列连接。, join='outer':默认outer交集,保留所有索引,并填充缺失值, ignore_index=False, keys=None:用于在合并后给结果对象创建多级索引的键)df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})# 沿行轴(axis=0)连接 df1 和 df2 df = pd.concat([df1, df2], ignore_index=True) print(df)
5.更新数据
DataFrame.update
-
功能:根据另一个 DataFrame 更新现有 DataFrame 中的值。
-
用法:
df.update(other)df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})# 更新 df1 的数据 df1.update(df2) print(df1) -
append:将 DataFrame 或 Series 行追加到现有对象。 -
assign:添加或修改 DataFrame 列。 -
insert:在指定位置插入新列。 -
concat:连接多个 DataFrame 或 Series。 -
update:根据另一个 DataFrame 更新现有 DataFrame。
二、数据查询
1. 单个元素查询(标签查询)
pandas.at
-
功能:用于快速访问 DataFrame 中的单个标量元素。适用于较少的操作,效率较高。
-
用法:
df.at[row_label, column_label]df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] })# 获取 'row1' 行和 'A' 列的单个元素 value = df.at[0, 'A'] print(value) # 输出 1
2.单个元素查询(索引查询)
pandas.iat
-
功能:用于快速访问 DataFrame 中的单个标量元素,基于整数位置进行索引。
-
用法:
df.iat[row_index, column_index]df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] })# 获取第1行和第2列的单个元素 value = df.iat[0, 0] print(value) # 输出 1
3.行列查询(标签查询)
pandas.loc
-
功能:基于行和列的标签进行数据选择。可以选择特定行、列或子集。
-
用法:
df.loc[row_labels, column_labels]df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] }, index=['row1', 'row2', 'row3'])# 获取 'row2' 行和 'A' 列的数据 subset = df.loc['row2', 'A'] print(subset) # 输出 2# 获取 'row1' 和 'row3' 行的所有数据 subset = df.loc[['row1', 'row3']] print(subset)
4.行列查询(索引查询)
pandas.iloc
-
功能:基于整数位置进行数据选择。可以选择特定行、列或子集。
-
用法:
df.iloc[row_indices, column_indices]df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] })# 获取第1行和第2列的数据 subset = df.iloc[0, 1] print(subset) # 输出 4# 获取前2行和前1列的数据 subset = df.iloc[0:2, 0] print(subset)
5.切块查询
pandas.xs
-
功能:从 DataFrame 中获取跨切片的数据。可以根据某个轴(行或列)进行切片。
-
用法:
df.xs(key, level, axis)df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] }, index=pd.MultiIndex.from_tuples([('x', 'a'), ('x', 'b'), ('y', 'c')], names=['first', 'second']))# 获取 'x' 级别的所有数据 result = df.xs('x', level='first') print(result)
6.表达式查询
pandas.query
-
功能:使用表达式进行数据查询,类似于 SQL 的查询语句。
-
用法:
df.query('expression')df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] })# 查询列 'A' 值大于 1 的行 result = df.query('A > 1') print(result)
7.条件查询
pandas.where
-
功能:根据条件进行数据筛选,可以选择满足条件的元素或替换不满足条件的元素。
-
用法:
df.where(condition, other)df = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6] })# 将不满足条件(列 'A' > 1)的元素替换为 NaN result = df.where(df['A'] > 1) print(result)
总结
at和iat:用于访问单个标量元素,at基于标签,iat基于位置。loc和iloc:用于选取数据,loc基于标签,iloc基于位置。xs:用于获取跨切片数据。query:用于表达式查询。where:用于条件筛选和替换。
三、数据清洗
1. 处理缺失值
-
DataFrame.isna()和DataFrame.isnull():检测缺失值。df = pd.DataFrame({'A': [1, None, 3], 'B': [4, 5, None]}) print(df.isna()) -
DataFrame.dropna():删除缺失值所在的行或列。df_cleaned = df.dropna() # 删除包含缺失值的行 -
DataFrame.fillna():填充缺失值。df_filled = df.fillna(0) # 用 0 填充缺失值 -
DataFrame.interpolate():使用插值方法填充缺失值。df_interpolated = df.interpolate()
2. 处理重复数据
-
DataFrame.duplicated():检测重复行。df = pd.DataFrame({'A': [1, 1, 2], 'B': [3, 3, 4]}) print(df.duplicated()) # 检测重复行 -
DataFrame.drop_duplicates():删除重复行。df_unique = df.drop_duplicates()
3. 处理异常值
-
使用统计方法识别异常值:
- 例如,使用 Z-Score 或 IQR(四分位距)来识别异常值。
df = pd.DataFrame({'A': [1, 2, 2, 3, 100]}) z_scores = stats.zscore(df) df_cleaned = df[(abs(z_scores) < 3).all(axis=1)] -
使用 IQR 识别异常值:
Q1 = df['A'].quantile(0.25) Q3 = df['A'].quantile(0.75) IQR = Q3 - Q1 df_cleaned = df[(df['A'] >= (Q1 - 1.5 * IQR)) & (df['A'] <= (Q3 + 1.5 * IQR))]
4. 处理数据类型
-
DataFrame.astype():转换数据类型。df['A'] = df['A'].astype(int) -
DataFrame.convert_dtypes():自动转换 DataFrame 的数据类型。df = df.convert_dtypes()
5. 清理文本数据
-
DataFrame.replace():替换文本中的特定值。df = pd.DataFrame({'A': ['foo', 'bar', 'foo']}) df['A'] = df['A'].replace('foo', 'baz') -
DataFrame.str.strip():去除字符串中的前后空白字符。df['A'] = df['A'].str.strip() -
DataFrame.str.lower()和DataFrame.str.upper():转换字符串为小写或大写。df['A'] = df['A'].str.lower()
6. 数据转换
-
DataFrame.apply():应用自定义函数进行数据转换。df['A'] = df['A'].apply(lambda x: x * 2) -
DataFrame.map():将映射函数应用于 DataFrame 或 Series。df['A'] = df['A'].map({1: 'one', 2: 'two'})
7. 处理分类数据
-
DataFrame.get_dummies():将分类变量转换为虚拟变量(one-hot encoding)。
df = pd.get_dummies(df, columns=['A'])
总结
- 缺失值处理:
isna(),dropna(),fillna(),interpolate() - 重复数据处理:
duplicated(),drop_duplicates() - 异常值处理:使用统计方法如 Z-Score 和 IQR
- 数据类型转换:
astype(),convert_dtypes() - 文本数据清理:
replace(),str.strip(),str.lower(),str.upper() - 数据转换:
apply(),map() - 分类数据处理:
get_dummies()
四、数据统计
在 Pandas 中,数据统计是数据分析中的核心部分,它包括对数据进行各种统计计算和汇总。以下是一些常用的 Pandas 数据统计函数和方法:
1. 基本统计描述
-
DataFrame.describe():计算 DataFrame 中各列的基本统计描述,包括计数、均值、标准差、最小值、四分位数和最大值。df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [10, 20, 30, 40, 50]}) print(df.describe()) -
Series.describe():对 Series 计算基本统计描述。s = pd.Series([1, 2, 3, 4, 5]) print(s.describe())
2. 聚合函数
-
DataFrame.mean():计算每列的均值。print(df.mean()) -
DataFrame.median():计算每列的中位数。print(df.median()) -
DataFrame.sum():计算每列的总和。print(df.sum()) -
DataFrame.min()和DataFrame.max():计算每列的最小值和最大值。print(df.min()) print(df.max()) -
DataFrame.std():计算每列的标准差。print(df.std()) -
DataFrame.var():计算每列的方差。print(df.var())
3. 分组统计
-
DataFrame.groupby():按照指定列进行分组。df = pd.DataFrame({'A': ['foo', 'foo', 'bar', 'bar'], 'B': [1, 2, 3, 4]}) grouped = df.groupby('A') print(grouped.mean()) -
GroupBy.agg():对分组结果应用多种聚合函数。grouped = df.groupby('A') print(grouped.agg({'B': ['sum', 'mean']})) -
GroupBy.transform():对每组数据应用函数并返回与原 DataFrame 相同形状的结果。python复制代码df['B_transformed'] = grouped['B'].transform(lambda x: x - x.mean()) print(df)
4. 透视表
-
DataFrame.pivot_table():创建透视表以汇总数据。
df = pd.DataFrame({'A': ['foo', 'foo', 'bar', 'bar'], 'B': [1, 2, 3, 4], 'C': [5, 6, 7, 8]}) pivot_table = pd.pivot_table(df, values='C', index='A', columns='B', aggfunc='mean') print(pivot_table)
5. 相关性
-
DataFrame.corr():计算各列之间的相关系数矩阵。df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [10, 20, 30, 40]}) print(df.corr()) -
DataFrame.cov():计算各列之间的协方差矩阵。print(df.cov())
6. 频率统计
-
Series.value_counts():计算 Series 中每个值的出现次数。s = pd.Series(['a', 'b', 'a', 'c', 'a', 'b']) print(s.value_counts()) -
DataFrame.value_counts():计算 DataFrame 中每行的出现次数(可通过 DataFrame 的行或列计算)。df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['x', 'x', 'y']}) print(df.value_counts())
总结
- 基本统计描述:
describe() - 聚合函数:
mean(),median(),sum(),min(),max(),std(),var() - 分组统计:
groupby(),agg(),transform() - 透视表:
pivot_table() - 相关性:
corr(),cov() - 频率统计:
value_counts()
五、数据排序
1. 排序 DataFrame
-
按列排序
-
DataFrame.sort_values(by, axis, ascending):按照指定列排序,by参数指定要排序的列名,axis为 0 表示按行排序(默认),ascending为 True 表示升序(默认),False 表示降序。df = pd.DataFrame({'A': [3, 1, 2], 'B': [9, 7, 6]}) sorted_df = df.sort_values(by='A', ascending=True) print(sorted_df) -
按多列排序
你可以指定多个列进行排序,每个列可以有不同的排序顺序。
df = pd.DataFrame({'A': [1, 2, 1], 'B': [9, 7, 7]}) sorted_df = df.sort_values(by=['A', 'B'], ascending=[True, False]) print(sorted_df)
-
-
按索引排序
-
DataFrame.sort_index(axis, level, ascending):按照索引排序,
axis为 0 表示按行索引排序(默认),
level允许在多级索引的情况下进行排序,
ascending为 True 表示升序,False 表示降序。
df = pd.DataFrame({'A': [3, 1, 2]}, index=['c', 'a', 'b']) sorted_df = df.sort_index(ascending=True) print(sorted_df)
-
2. 排序 Series
-
按值排序
-
Series.sort_values(ascending):按照值排序,
ascending为 True 表示升序(默认),False 表示降序。
s = pd.Series([3, 1, 2], index=['c', 'a', 'b']) sorted_s = s.sort_values(ascending=True) print(sorted_s)
-
-
按索引排序
-
Series.sort_index(ascending):按照索引排序,
ascending为 True 表示升序,False 表示降序。
python复制代码sorted_s = s.sort_index(ascending=True) print(sorted_s)
-
3. 排序相关参数
by:指定排序的列或索引。axis:指定排序的轴,0 表示按行(默认),1 表示按列。ascending:指定升序或降序,默认是升序。level:在多级索引的情况下,指定要排序的级别。
示例代码
import pandas as pd# 创建示例 DataFrame
df = pd.DataFrame({'A': [3, 1, 2], 'B': [9, 7, 6]}, index=['c', 'a', 'b'])# 按列 'A' 升序排序
sorted_df_by_A = df.sort_values(by='A', ascending=True)
print("按列 'A' 升序排序:")
print(sorted_df_by_A)# 按列 'A' 降序排序,并按列 'B' 升序排序
sorted_df_by_A_and_B = df.sort_values(by=['A', 'B'], ascending=[False, True])
print("\n按列 'A' 降序排序,并按列 'B' 升序排序:")
print(sorted_df_by_A_and_B)# 按索引升序排序
sorted_df_by_index = df.sort_index(ascending=True)
print("\n按索引升序排序:")
print(sorted_df_by_index)
总结
- 按列排序:
sort_values(by, axis, ascending) - 按索引排序:
sort_index(axis, level, ascending) - 排序 Series:
sort_values(ascending),sort_index(ascending)
这些方法可以帮助你对数据进行排序,以满足不同的数据分析需求。