目录
一、元素的定位
1、cssSelector
2、xpath
(1)xpath 语法
1、获取HTML页面所有的节点
2、获取HTML页面指定的节点
3、获取一个节点中的直接子节点
4、获取一个节点的父节点
5、实现节点属性的匹配
6、使用指定索引的方式获取对应的节点内容
(2)获取selector/xpath路径的便捷方法
3、NoSuchElementException
二、操作测试对象
1、click()
2、sendKeys(" ")
3、clear()
4、getText()
gerAttribute()
5、getTitle()
三、窗口
1、窗口设置大小
2、切换窗口
(1)获取当前页面句柄
(2)获取所有页面句柄
(3)切换当前句柄为最新页面
3、屏幕截图
简单版:
优化:
4、关闭窗口
四、等待
出现NotFindSuchElementException 的排查问题思路
1、强制等待
2、隐式等待
3、显式等待
(1)elementToBeClickable
(2)textToBe
(3)presenceOfElementLocated
4、隐式和显式等待同时使用
五、浏览器导航
1、打开网站
2、浏览器的前进、后退、刷新
六、弹窗
七、文件操作
八、参数设置
1、设置无头模式
2、设置浏览器加载策略
一、元素的定位
web自动化测试的操作核心是能够找到页面对应的元素,然后才能对元素进行具体的操作。
常见的元素定位方式非常多,如:id、classname、tagname、xpath、cssSelector
常用的主要有:cssSelector、xpath。
1、cssSelector
选择器的功能:选中页面中指定的标签元素。
选择器的种类分为基础选择器和符合选择器,常见的元素定位方式可以通过id选择器和子类选择器来进行定位。
如图,在百度页面定位“百度一下” 源代码位置。

进入开发者模式,选择这个选项
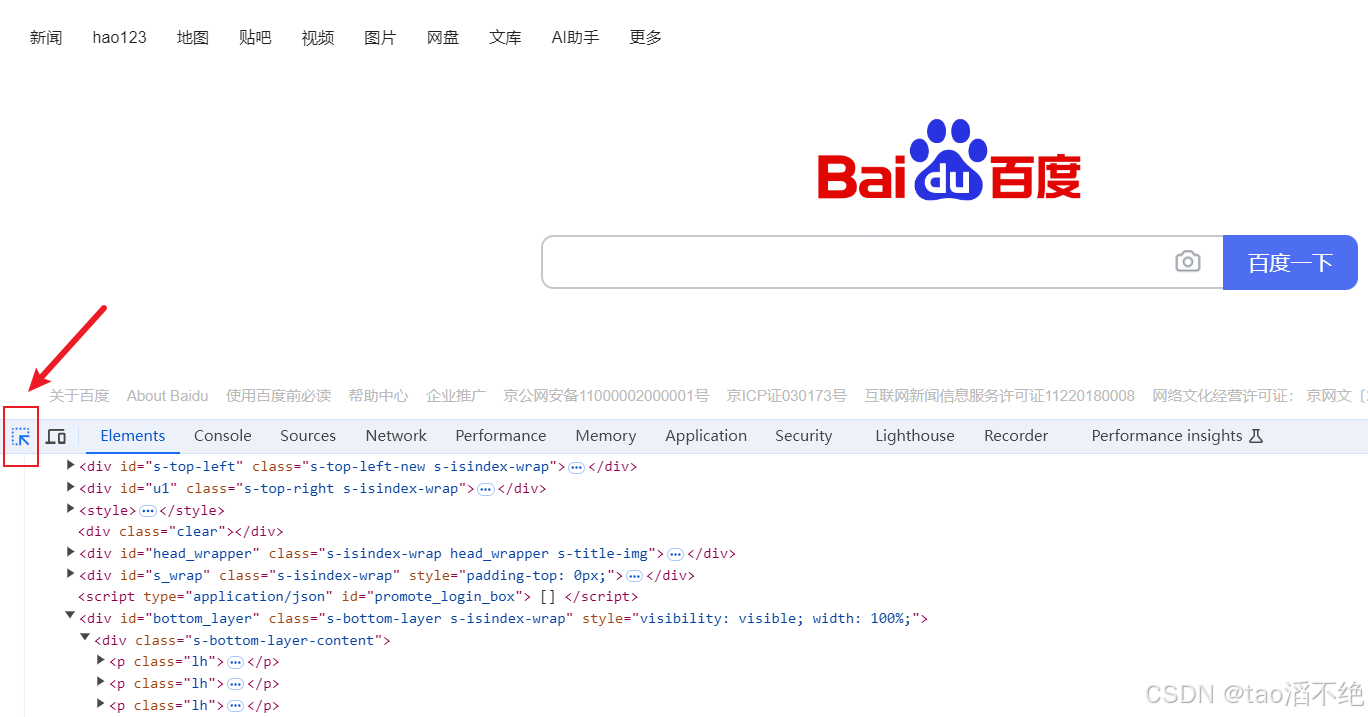
点击页面的相关按键,就能定位到该按键的源代码位置,如图:
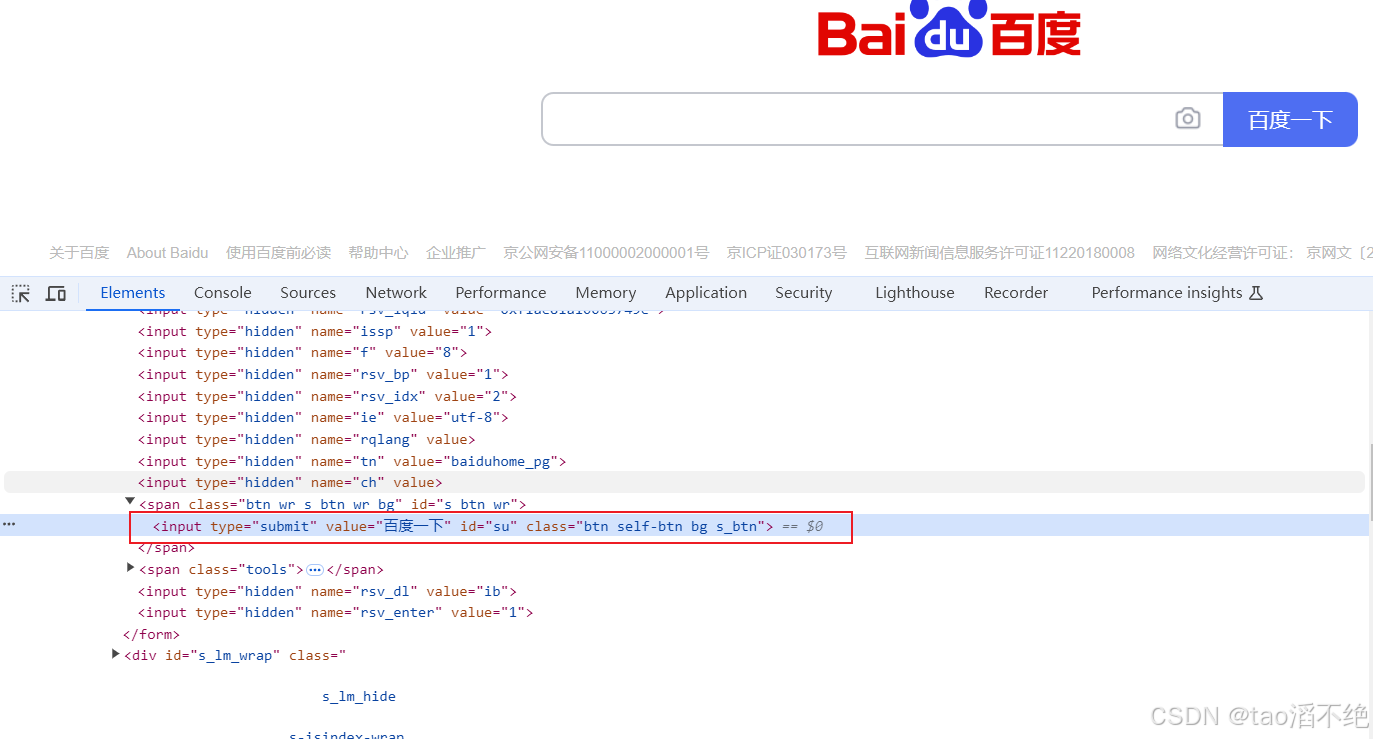
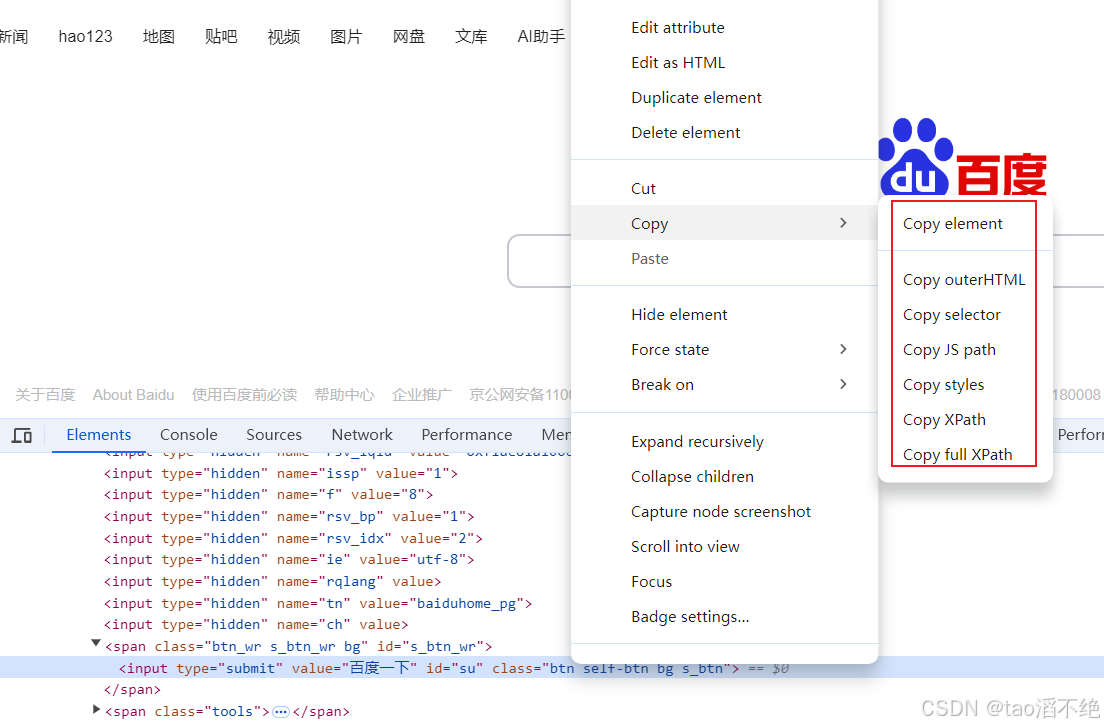
右键该源代码位置,点击copy,就能找到对应的selector和xpath等其他的路径。
2、xpath
XML路径语言,不仅可以在XML文件中查找信息,还可以在HTML中选取节点。
xpath使用路径表达式来选择XML文档中的节点。
(1)xpath 语法
1、获取HTML页面所有的节点
//*
2、获取HTML页面指定的节点
// [指定节点]
例如:
//ul:获取HTML页面所有的 ul 节点
//input:获取HTML页面所有的 input 节点
3、获取一个节点中的直接子节点
/
例如:
//span/input
4、获取一个节点的父节点
..
例如:
//input/.. 获取input节点的父节点
5、实现节点属性的匹配
[@...]
例如:
//*@id='kw'] 匹配HTML页面中的id属性为kw的节点
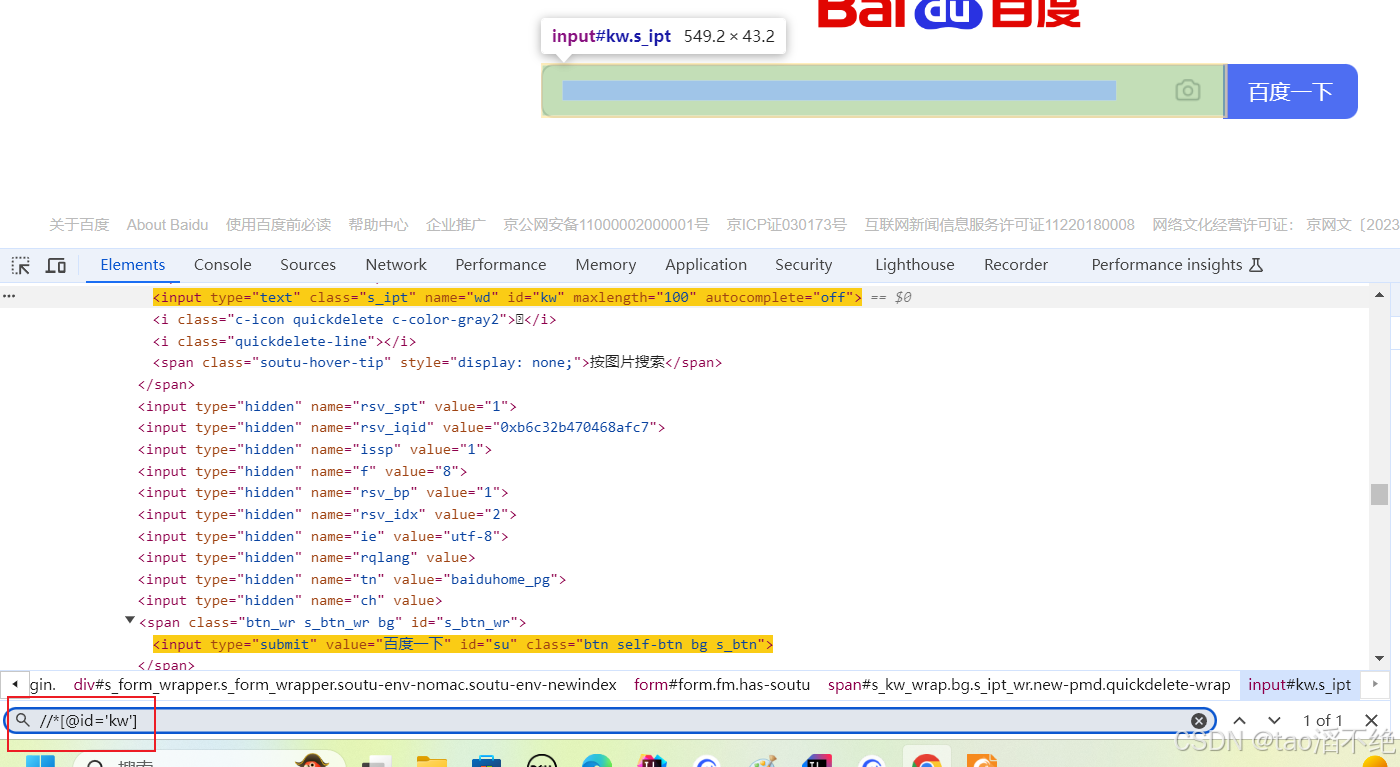
6、使用指定索引的方式获取对应的节点内容
注意:xpath的索引是从1开始的
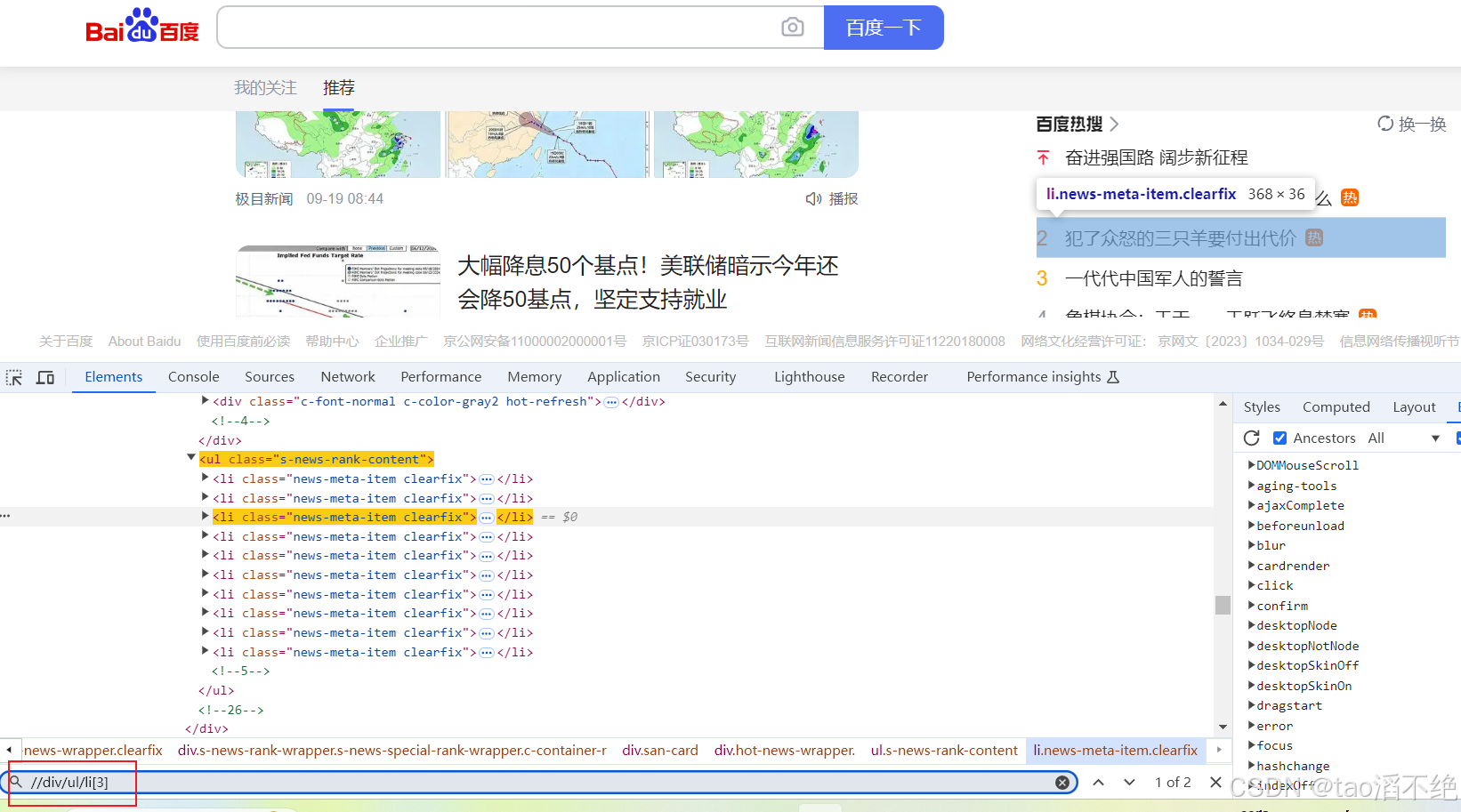
百度首页通过://div/ul/li[3] 定位到第二个百度热搜标签
(2)获取selector/xpath路径的便捷方法
更便捷的生成selector/xpath的方式:先点击图标所在位置,右键该源代码选择复制“Copy selector/xpath”。
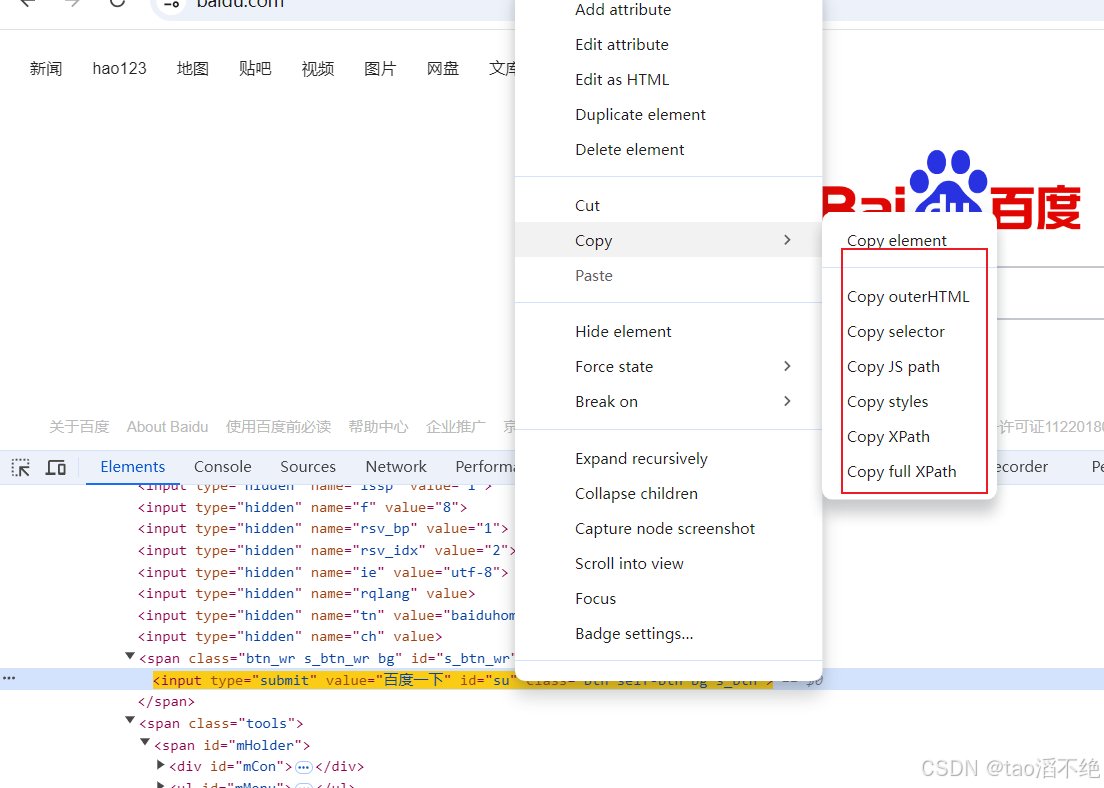
注意:元素的定位方法必须唯一。
3、NoSuchElementException
这个异常表示没有这样的元素,非常经典、常见。
编写一个自动化脚本,定位百度热搜这个标签,登录后,复制selector路径:#s_xmancard_news_new > div > div.s-news-rank-wrapper.s-news-special-rank-wrapper.c-container-r > div > div > div > a > div > i.c-icon.hotsearch-title
编写脚本代码:
void test02(){//1、打开浏览器,使用驱动打开WebDriverManager.chromedriver().setup();//增加浏览器配置:创建驱动对象要强制指定运行访问所有的链接ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);//2、输入完整的网址:https://www.baidu.com/driver.get("https://www.baidu.com/");Thread.sleep(8000);//定位百度热搜标签driver.findElement(By.cssSelector("#s_xmancard_news_new > div > div.s-news-rank-wrapper.s-news-special-rank-wrapper.c-container-r > div > div > div > a > div > i.c-icon.hotsearch-title"));}执行该方法,发现报错了,报复内容:

去看脚本打开的网页查找该路径:发现没有该路径
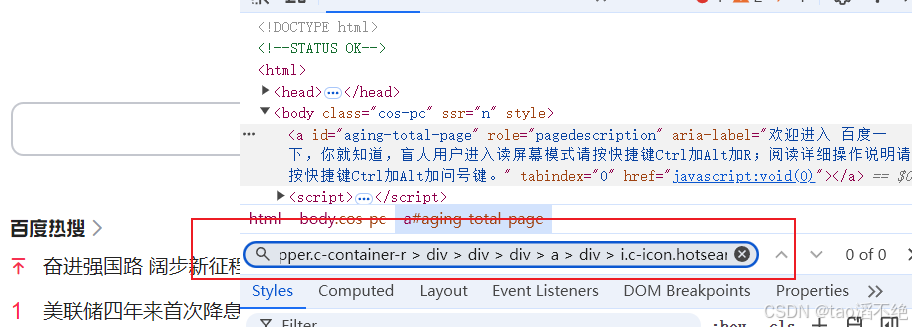
我们再看看脚本创建打开的网页长什么样子:
我们复制路径时候的页面:
发现问题所在,原因就是登录情况下和未登录情况下的页面不同,对应的元素路径也会不同,我们这时候把脚本用驱动打开的页面复制下来其路径就好了。
代码改成这样就不会报错了。
driver.findElement(By.cssSelector("#su"));注意:
登录状态和非登录状态下自动化打开的页面不一定相同,所以在做自动化测试一定要注意页面状态的一致性。
二、操作测试对象
获取到了页面元素之后,接下来就是要对元素进行操作了。常见的操作有点击、提交、输入、清除、获取文本。
1、findElement() 和 findElements()
findElement 和 findElements 都是在页面查找元素的。

findElements的使用:
找到百度热搜,拿到百度热搜的全部内容
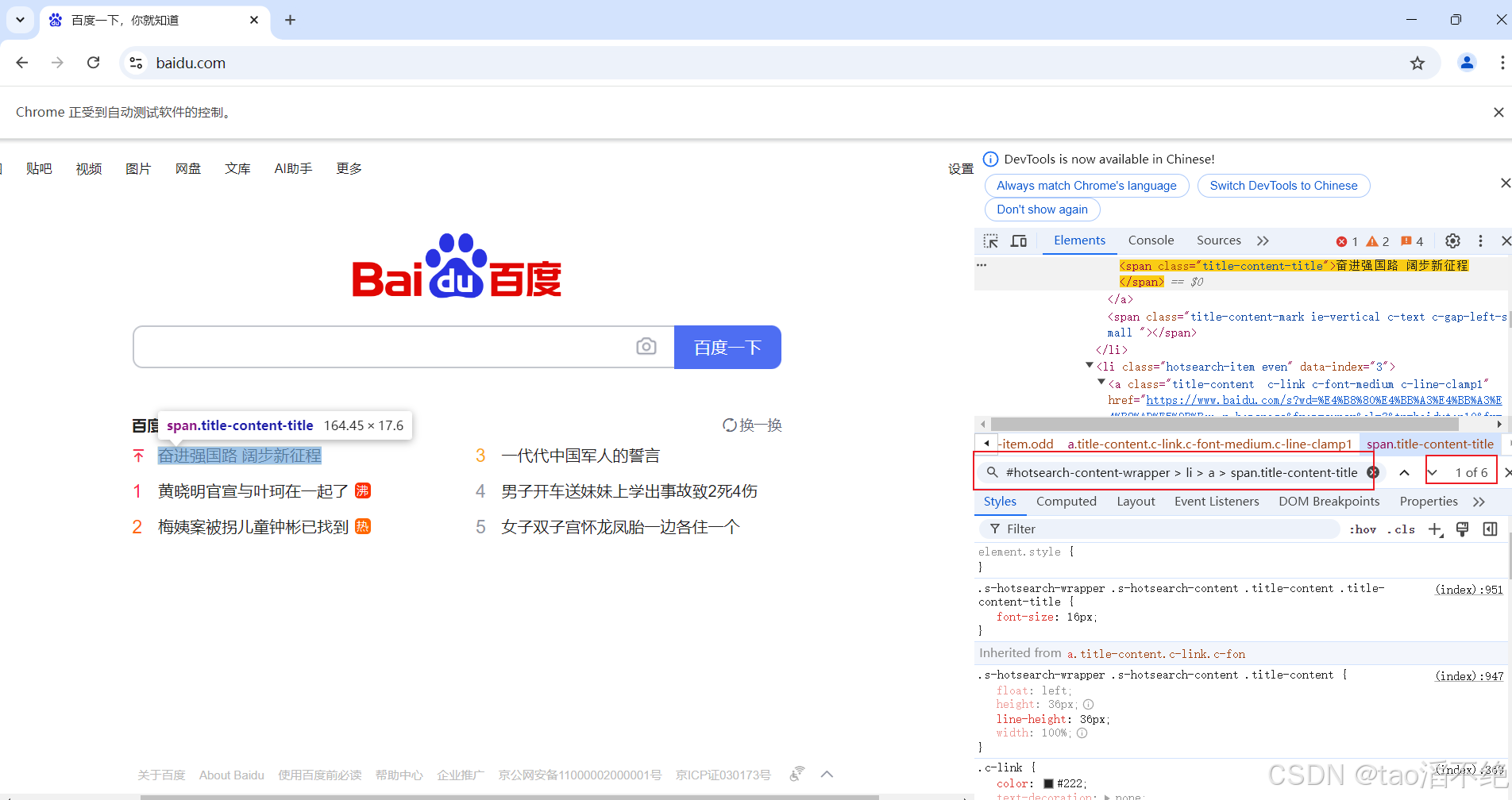
脚本代码:
void test03(){//1、打开浏览器,使用驱动打开WebDriverManager.chromedriver().setup();//增加浏览器配置:创建驱动对象要强制指定运行访问所有的链接ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);//2、输入完整的网址:https://www.baidu.com/driver.get("https://www.baidu.com/");//定位百度热搜标签List<WebElement> elements = driver.findElements(By.cssSelector("#hotsearch-content-wrapper > li > a > span.title-content-title"));for(WebElement x : elements) {System.out.println(x.getText());}} 控制台输出:
介绍完findElements后,下面介绍selenium操作web页面里的元素。
2、click()
点击 / 提交对象
//找到百度⼀下按钮并点击
driver.findElement(By.cssSelector("#su")).click();注意:
选择web页面的元素不能选hidden,标签里的type=hidden表示是隐藏的,如果选择隐藏的元素,则会报错。
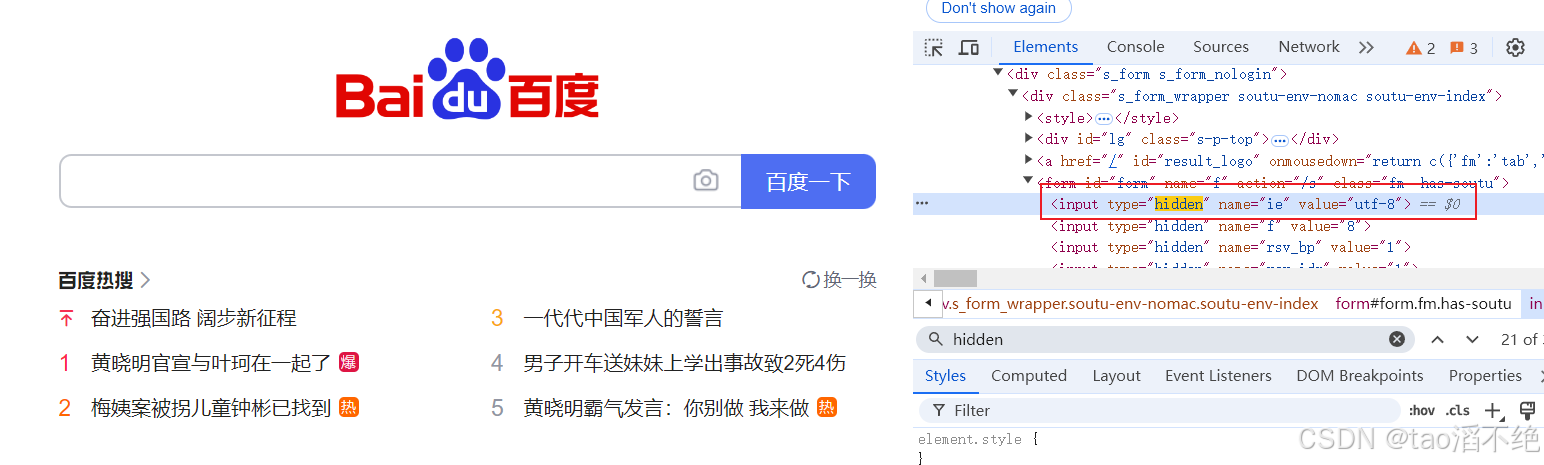
选择这个元素进行点击,执行结果如下:
driver.findElement(By.cssSelector("#form > input[type=hidden]:nth-child(1)")).click();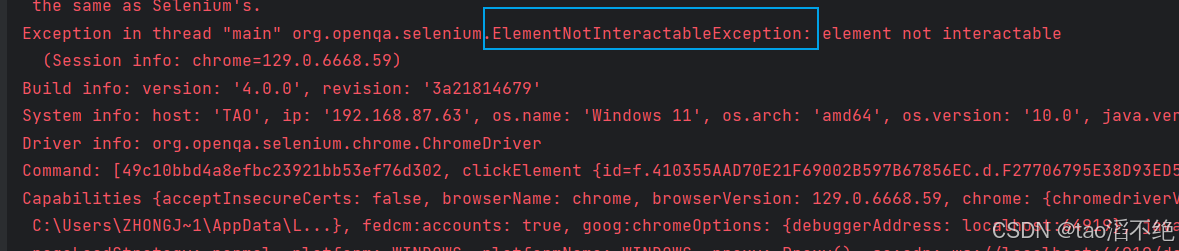
ElementNotInteractableException,元素不可交互(表示不可以对元素进行操作),如果遇到这种异常,可能就是选择了隐藏的标签(含有hidden关键字)。
3、sendKeys(" ")
模拟按键输入
//找到百度搜索框并输入内容
driver.findElement(By.cssSelector("#kw")).sendKeys("输入文字");4、clear()
清除文本内容;输入文本后又想换一个新的关键词,这里就需要用到clear()
//输入文本后又想换一个新的关键词
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱打游戏");
driver.findElement(By.cssSelector("#kw")).clear();
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱学习");
执行上述代码后,打开百度页面,文本框中输入“我爱打游戏”,然后清除掉文本框内容,再打印“我爱学习”。
5、getText()
获取文本信息;如何判断获取到的元素对应的文本是否符合预期呢?获取元素对应的文本并打印一下~~
脚本代码如下:
void test05(){//1、打开浏览器,使用驱动打开WebDriverManager.chromedriver().setup();//增加浏览器配置:创建驱动对象要强制指定运行访问所有的链接ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);//2、输入完整的网址:https://www.baidu.com/driver.get("https://www.baidu.com/");WebElement ele = driver.findElement(By.cssSelector("#hotsearch-content-wrapper > li:nth-child(1) > a > span.title-content-title"));//获取元素对应的文本System.out.println(ele.getText());driver.quit();}运行结果:
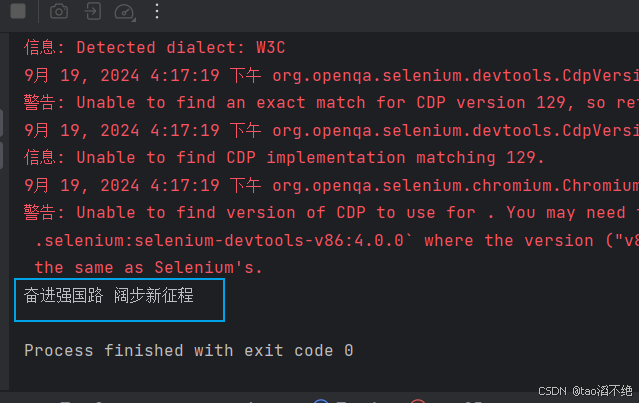
但是获取“百度一下”的文本内容获取不了,因为“百度一下”不是文本内容,而是标签里的属性(value="")。
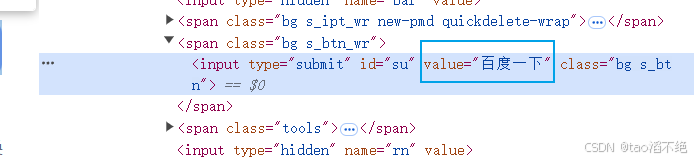
那如果要获取HTML的标签里的属性值怎么办?下面的方法可以实现
gerAttribute()
获取标签里的属性值
代码如下:
String s = driver.findElement(By.cssSelector("#su")).getAttribute("value");System.out.println(s);执行结果:
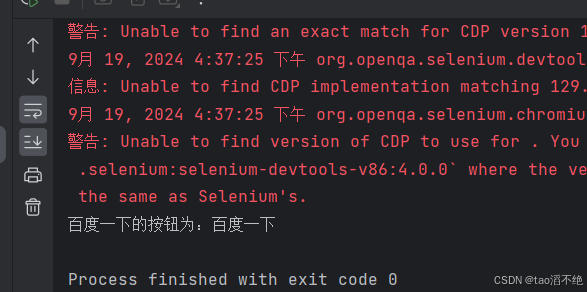
怎么区分文本和标签属性值?如图:
文本:

属性值:

6、getTitle()
获取当前页面标题
String title = driver.getTitle();
System.out.println(title); 执行结果:
7、getCurrentUrl()
获取当前页面URL
String url = driver.getCurrentUrl();
System.out.println(url);执行结果:
三、窗口
打开一个新的页面之后获取到的title和URL为啥仍然还是前一个页面的?
当我们手工测试的时候,我们可以通过眼睛来判断当前的窗口是什么,但对于程序来说,它是不知道当前最新的窗口应该是哪一个。对于程序来说,它怎么来识别每一个窗口呢?每个浏览器窗口都有一个唯一的属性句柄(handle)来表示,我们就可以通过句柄来切换。
1、窗口设置大小
代码如下:
//窗口最大化driver.manage().window().maximize();//窗口最小化driver.manage().window().minimize();//全屏窗口driver.manage().window().fullscreen();//手动设置窗口大小driver.manage().window().setSize(new Dimension(1024, 666));2、切换窗口
(1)获取当前页面句柄
driver.getWindowHandle();(2)获取所有页面句柄
driver.getWindowHandles();(3)切换当前句柄为最新页面
主要代码:
String curWindow = driver.getWindowHandle();driver.findElement(By.cssSelector("#s-top-left > a:nth-child(1)")).click();Thread.sleep(2000);//获取所有页面句柄Set<String> allWindow = driver.getWindowHandles();for(String w : allWindow) {if(!w.equals(curWindow)) {driver.switchTo().window(w);}}测试代码如下:
void test08() throws InterruptedException {//1、打开浏览器,使用驱动打开WebDriverManager.chromedriver().setup();//增加浏览器配置:创建驱动对象要强制指定运行访问所有的链接ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);//2、输入完整的网址:https://www.baidu.com/driver.get("https://www.baidu.com/");//获取当前页面句柄String curWindow = driver.getWindowHandle();driver.findElement(By.cssSelector("#s-top-left > a:nth-child(1)")).click();//获取所有页面句柄Set<String> allWindow = driver.getWindowHandles();for(String w : allWindow) {if(!w.equals(curWindow)) {driver.switchTo().window(w);}}//测试百度新闻页首页driver.findElement(By.cssSelector("#usrbar > ul > li:nth-child(4) > a"));driver.quit();}注意:执行了driver.quit()之前需要切换到未被关闭的窗口。(driver.get()也可以跳转到其他页面)
3、屏幕截图
引入依赖:
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency>简单版:
//测试百度新闻页首页
File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
//srcFile放到指定位置
FileUtils.copyFile(srcFile, new File("my.png"));执行程序后生成对应的文件:

优化:
上面代码每次生成图片都会把之前的图片给覆盖掉。现在进行优化:
1、每次生成的屏幕截图都保存下来,避免覆盖。
2、屏幕截图文件统一放到test下的image文件夹下
3、生成的屏幕截图名称,要见名知义——即看到这个屏幕截图的名称,我就知道是哪个测试方法的屏幕截图。
脚本代码:(这里的时间最好设置成毫秒级别,因为自动化脚本执行很快,是毫秒级别,不然调用多次就会把之前图片文件覆盖掉)
void getScreenShot(String str) throws IOException {//1、打开浏览器,使用驱动打开WebDriverManager.chromedriver().setup();//增加浏览器配置:创建驱动对象要强制指定运行访问所有的链接ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");WebDriver driver = new ChromeDriver(options);//2、输入完整的网址:https://www.baidu.com/driver.get("https://www.baidu.com/");// ./src/test/image/// /2024-07-17/// /test01-192300.png// /test01-192300.png// /2024-07-18/// /test01-192300.png// /test01-192300.png//屏幕截图SimpleDateFormat sim1 = new SimpleDateFormat("yyyy-MM-dd");//年月日SimpleDateFormat sim2 = new SimpleDateFormat("HHmmssSS");//时分秒毫秒String dirTime = sim1.format(System.currentTimeMillis());String fileTime = sim2.format(System.currentTimeMillis());//test01-192300.pngString fileName = "./src/test/image/" + dirTime +"/" + str + "-" + fileTime + ".png";File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);FileUtils.copyFile(srcFile, new File(fileName));driver.close();}运行代码,结果如下:

多次运行该程序,也不会把之前的数据给覆盖掉。
4、关闭窗口
driver.close();和 driver.quit()不同,quit方法表示关闭浏览器 或 释放driver对象,而close是关闭当前标签页。
注意:
1、窗口关闭后 driver 要重新切换到其他句柄(因为当前句柄已经释放掉了,所以要切换到其他句柄)。
2、即使多次close把所有标签页都关闭了,driver 对象也还没被释放掉,要么程序退出后自动释放,要么就要我们手动进行释放(quit方法)
3、close方法用到的比较少,只会在以下场景下使用:测试打开新的标签页后还要返回到前一个标签页进行测试。
四、等待
通常代码执行的速度比页面渲染的速度要快,如何避免因为渲染过慢出现的自动化误报的问题呢?可以使用 selenium 中提供的三种等待方法。
公共代码:
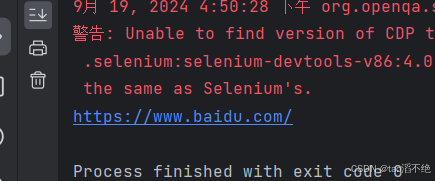
WebDriver driver = null;void createDriver() {WebDriverManager.chromedriver().setup();ChromeOptions options = new ChromeOptions();options.addArguments("--remote-allow-origins=*");driver = new ChromeDriver(options);}现在百度 “邓紫棋”,然后选择 “百度百科” 进行点击
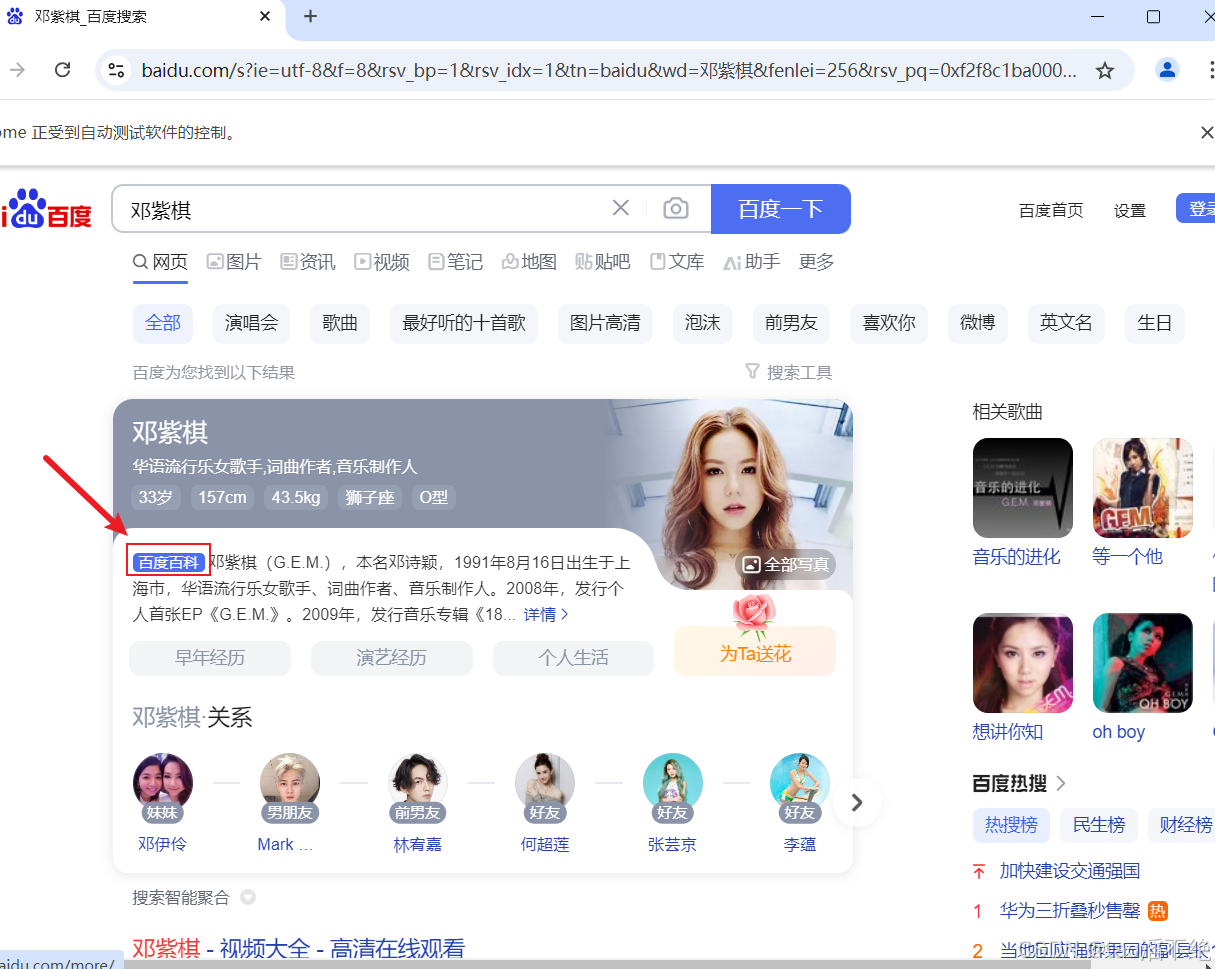
脚本代码如下:
void test01() throws InterruptedException {createDriver();driver.get("https://www.baidu.com/");driver.findElement(By.cssSelector("#kw")).sendKeys("邓紫棋");driver.findElement(By.cssSelector("#su")).click();driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")).click();
// driver.findElement(By.xpath("//*[@id=\"1\"]/div/div/div/div/div/div[4]/div/div[1]/div[1]/div/div/p/span[1]/span")).click();driver.quit();}执行代码,cssSelector路径和xpath路径都试试,发现有NotFindSuchElementException异常,如图:
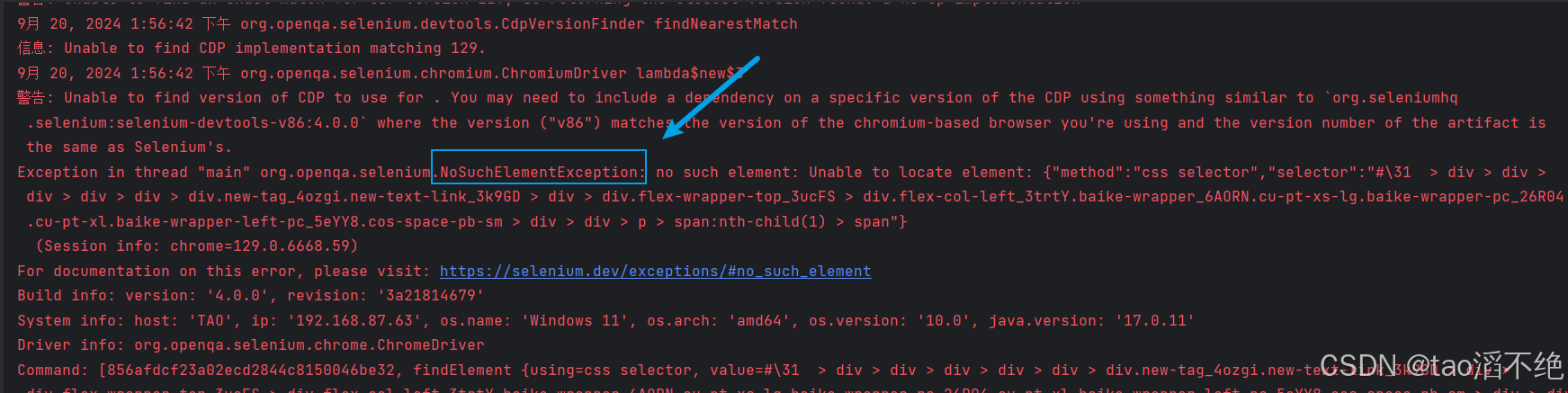
这是为什么呢?检查一下在自动化脚本上能不能找到selector和xpath路径,如图:
selector:
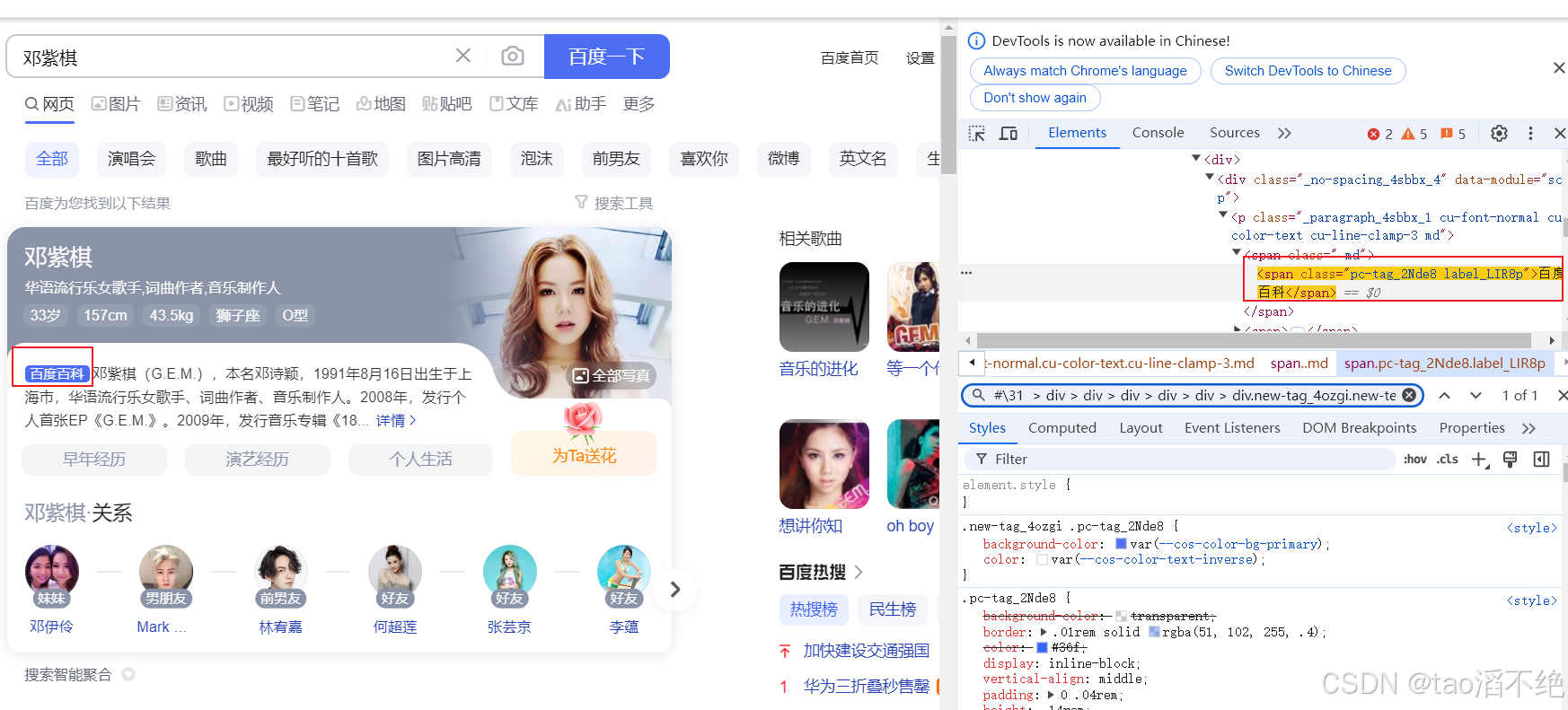
xpath:
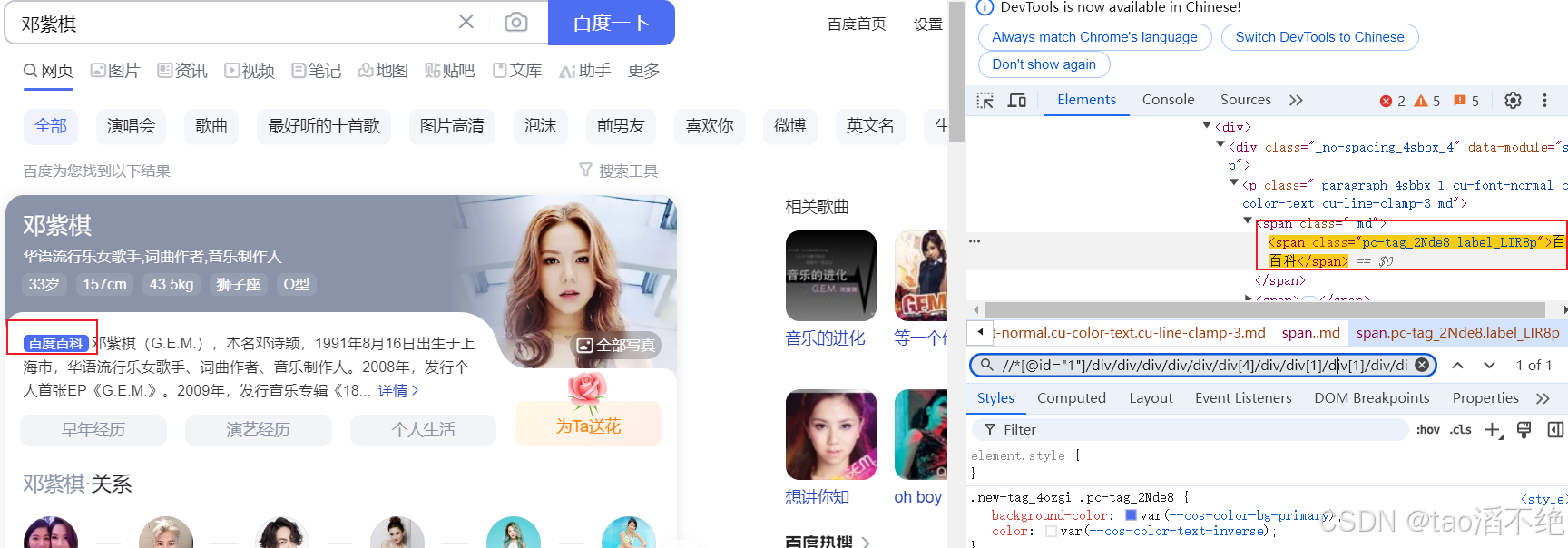
两个路径都能找到。现在,我们加上一个强制等待,也就是 Thread.sleep(3000),再试试会不会报错。
void test01() throws InterruptedException {createDriver();driver.get("https://www.baidu.com/");driver.findElement(By.cssSelector("#kw")).sendKeys("邓紫棋");driver.findElement(By.cssSelector("#su")).click();Thread.sleep(3000);//强制等待driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")).click();
// driver.findElement(By.xpath("//*[@id=\"1\"]/div/div/div/div/div/div[4]/div/div[1]/div[1]/div/div/p/span[1]/span")).click();driver.quit();}发现程序执行成功了,如图:
原因就是代码执行的太快了,而页面渲染速度没代码执行速度快,导致有些元素还没来得及加载出来,就去查找指定元素,这时候找不到,就会出现NotFindSuchElementException 异常(没有找到这样的元素异常)。
出现NotFindSuchElementException 的排查问题思路
(1)在报错代码前添加 Thread.sleep(),设置的时间长一点。
(2)执行自动化,手动检查自动化打开的页面里是否存在该元素。
1、自动化打开的也确实不存在该元素
—— 手动打开的页面和自动化打开的页面不一样(很可能是登录和未登录状态下页面不一样)。
—— 元素为动态元素。
解决办法:先定位动态元素的前一级标签,再增加要定位的元素标签


2、自动化打开的页面确实存在该元素
—— 代码执行的速度比页面渲染的速度要快,页面还没渲染出来,程序已经开始找了,导致元素没被找到。
解决办法:添加等待。
下面介绍3种等待。
1、强制等待
以线程阻塞的方式进行强性等待。(自动化很少用到强制等待,因为太耗时了,一般用来调试)
Thread.sleep()优点:使用简单,调试的时候比较有效。
缺点:影响运行效率,浪费大量的时间。
2、隐式等待
隐式等待是一种智能等待,他可以规定在查找元素时,在指定时间内不断查找元素。如果找到则代码继续执行,直到超时没找到元素才会报错。
implicitlyWait() 参数:Duration类中提供的毫秒、秒、分钟等方法。
//隐式等待1000毫秒
driver.manage().timeouts().implicitlyWait(Duration.ofMillis(1000));
//隐式等待5秒
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));隐式等待作用域是整个脚本的所有元素。即只要driver对象没有被释放掉(driver.quit()),隐式等待就一直生效(只要是在查找元素,就会隐式等待)。
优点:智能等待,作用于全局。(只要写一次隐式等待,就会全局都起作用)。
缺点:只能查找元素、每次查找元素都要等待。
上面出现的问题,也可以使用隐式等待的方式解决,代码如下:
void test02(){createDriver();driver.get("https://www.baidu.com/");driver.findElement(By.cssSelector("#kw")).sendKeys("邓紫棋");driver.findElement(By.cssSelector("#su")).click();//隐式等待driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));//点击“百度百科driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")).click();
// driver.findElement(By.xpath("//*[@id=\"1\"]/div/div/div/div/div/div[4]/div/div[1]/div[1]/div/div/p/span[1]/span")).click();driver.quit();}运行程序,我们会发现执行的非常快,因为隐式等待是一查找到元素,就不在等待,继续执行下面的代码。
现在更改一下代码,在上面代码基础上,加上其他操作:1、清除输入框的内容。2、输入 “迪丽热巴”。3、点击搜索。4、获取迪丽热巴 文本内容。5、将其内容打印到控制台上。
代码如下:
void test02(){createDriver();driver.get("https://www.baidu.com/");driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");driver.findElement(By.cssSelector("#su")).click();//隐式等待driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));//点击“百度百科”driver.findElement(By.xpath("//*[@id=\"1\"]/div/div/div/div/div/div[4]/div/div[1]/div[1]/div/div/p/span[1]/span")).click();//清空文本内容driver.findElement(By.cssSelector("#kw")).clear();//在输入框输入邓紫棋driver.findElement(By.cssSelector("#kw")).sendKeys("邓紫棋");//点击搜索driver.findElement(By.cssSelector("#su")).click();//获取邓紫棋元素WebElement ele = driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div > div.cos-row.row-text_1L24W.row_4WY55 > div > div.title-wrapper_XLSiK > a > div > p > span > span"));//打印出来String text = ele.getText();System.out.println("text:" + text);driver.quit();}运行程序,发现打印出来的是迪丽热巴,而不是邓紫棋
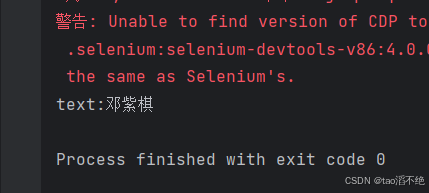
预期结果:邓紫棋 实际结果:迪丽热巴
原因分析:
因为隐式等待是只管查找元素,查找到了了就继续执行下面的代码,这里虽然元素都找到了,但clear()、sendKeys()、click()都还没执行完,下面就又查到相应的元素,又继续执行下面代码,把该元素打印出来了(也就是页面还没渲染到邓紫棋页面,就把迪丽热巴页面上的元素打印出来了)。
解决方案:在查找邓紫棋的元素之前强制等待几秒(Thread.sleep(3000))

3、显式等待
显式等待也是一种智能等待,在指定时间阈值内只要满足操作的条件就会继续执行后续代码。
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(3));wait.until(ExpectedConditions.);ExpectedConditions后面跟有有很多方法,如图:(返回值是boolean)
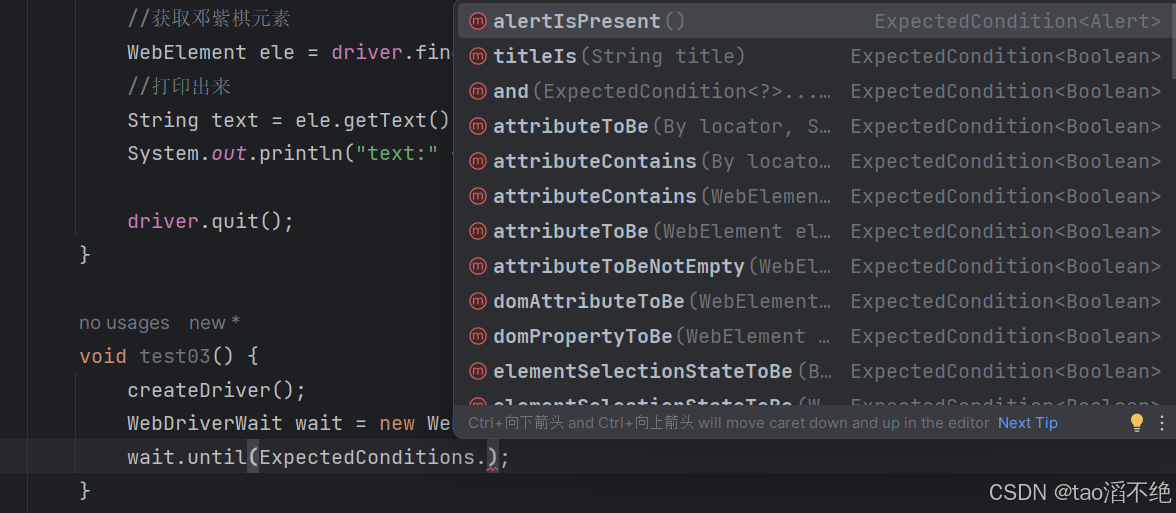
ExpectedConditions预定义方法的一些示例:
elementToBeClickable(By locator):用于检查元素的期望值是可见的并启用,以便你可以单击它。textToBe(By locator, String str):检查元素。(精确匹配)。
presenceOfElementLocated(By locator):检查页面的 DOM 上是否存在元素。
urlToBe(java.lang.String url):检查当前页面的URL是一个特定的URL。
(1)elementToBeClickable
void test03() {createDriver();driver.get("https://www.baidu.com/");WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(3));//确保你有["#su"可点击的]才能执行下面的操作;如果没有,又超过3秒后就会报错wait.until(ExpectedConditions.elementToBeClickable(By.cssSelector("#su")));driver.findElement(By.cssSelector("#su")).click();driver.quit();}(2)textToBe
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(3));
//查找百度首页的是否有“新闻”的文本信息(精确匹配)
wait.until(ExpectedConditions.textToBe(By.cssSelector("#s-top-left > a:nth-child(1)"), "新闻"));如果所选的元素是 “新闻” ,才会继续下面的操作。
(3)presenceOfElementLocated
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(3));
//检查是否有 #kw 元素(搜索框,在搜索框输入"迪丽热巴")
wait.until(ExpectedConditions.presenceOfElementLocated(By.cssSelector("#kw")));
driver.findElement(By.cssSelector("#kw")).sendKeys("迪丽热巴");如果有 #kw 元素,才会继续下面的操作。
4、隐式和显式等待同时使用
操作:打开百度,然后查找一个百度首页不存在的元素,隐式等待5秒,显式等待10秒,代码如下:
void test06() {createDriver();SimpleDateFormat sim = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");System.out.println(sim.format(System.currentTimeMillis()));driver.get("https://www.baidu.com/");//隐式等待driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));//显式等待WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(10));try {//百度首页不存在该元素wait.until(ExpectedConditions.presenceOfElementLocated(By.cssSelector("#headline-tabs > ul > li > a")));} catch (Exception e) {System.out.println("nosuelement!");}System.out.println(sim.format(System.currentTimeMillis()));driver.quit();}代码分析:因为想要找的元素不存在,所以肯定会在显式等待10秒后抛异常,打印出nosielement,但我们运行代码后发现,中间间隔并不是10秒,说明隐式打印和显式打印一起混用的时间不可预测。
执行结果如下:


结果:重复多次,最终打印的等待有11s、12s。
结论:隐式和显式等待混合使用需注意,可能会导致不可预测的等待时间。
五、浏览器导航
1、打开网站
//更长的方法
driver.navigate().to("https://www.baidu.com/");
//简洁的方法
driver.get("https://www.baidu.com/");2、浏览器的前进、后退、刷新
//前进
driver.navigate().forward();
//后退
driver.navigate().back();
//刷新
driver.navigate().refresh();六、弹窗
弹窗有三种:警告弹窗、确认弹窗、输入弹窗,如图:

弹窗是在页面找不到任何元素的,这种情况怎么处理?使用selenium提供的Alert接口。
弹窗的操作有:切换弹窗、点击确认、点击取消、输入文本信息。
//切换弹窗Alert alert = driver.switchTo().alert();//点击确认alert.accept();//点击取消alert.dismiss();输入文本信息:
//切换弹窗Alert alert = driver.switchTo().alert();//输入文本信息alert.sendKeys("hello");alert.accept();alert.dismiss();如果页面出现弹窗,而我们不去管它,继续执行下面的代码,很可能就会报错(比如后续代码查找的是关闭弹窗后的元素,就会报异常:UnhandledAlertException)
七、文件操作
点击文件长传的场景下会弹出系统窗口,进行文件的选择。
selenium无法识别非web的控件,上传文件窗口为系统自带,无法识别窗口元素,但是可以使用sendkeys来上传指定路径的文件,达到的效果是一样的。
//html页面的元素
WebElement ele = driver.findElement(By.cssSelector("页面的上传文件元素"));
//把文件路径放到该元素下,相当于文件的上传
ele.sendKeys("本地文件的绝对路径");八、参数设置
1、设置无头模式
无头模式表示在执行自动化脚本,不会出现浏览器页面,在后台里执行,我们是观察不到自动化脚本的操作的。
如果不设置该选项,默认是有头模式。
代码如下:
WebDriverManager.chromedriver().setup();ChromeOptions options = new ChromeOptions();options.addArguments("----remote-allow-origins=*");//允许访问所有urloptions.addArguments("-headless");//设置无头模式WebDriver driver1 = new ChromeDriver(options);driver1.get("https://www.baidu.com/");driver1.quit();2、设置浏览器加载策略
代码如下:
void test08() {WebDriverManager.chromedriver().setup();ChromeOptions options = new ChromeOptions();options.addArguments("----remote-allow-origins=*");//允许访问所有url//设置浏览器加载策略(有三种加载策略)options.setPageLoadStrategy(PageLoadStrategy.NONE);options.setPageLoadStrategy(PageLoadStrategy.EAGER);options.setPageLoadStrategy(PageLoadStrategy.NORMAL);WebDriver driver1 = new ChromeDriver(options);driver1.get("https://www.baidu.com/");driver1.quit();}官网的加载机制介绍:浏览器选项 | Selenium
加载策略有三种:normal、eager、none,如下图
通常情况下不需要设置页面加载策略;只有在极端情况下,如页面元素都可见了,但页面还在加载资源中(以备不时之需)。