Flink 系列之七 - Data Stream API的源算子原理
之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
目录
- 1 Source的底层原理
- 1.1 Source
- 1.2 三个关键组件
- 1.3 源算子的流程
- 2 自定义数据源
- 2.1 新建lesson04子模块
- 2.2 定义检查点及其序列化类
- 2.3 定义三大组件
- 2.4 定义Source和main方法类
- 2.5 运行测试
上一章了解了Flink的源算子,本章将再进入一层,了解一下Flink源算子的扩展,自定义自己的源算子。
1 Source的底层原理
Flink提供了很好的扩展性,支持自定义Source源算子。如果在网上检索Flink自定义源算子,都会搜索到关于如何通过SourceFunction实现自定义源算子,但是你会发现新版本的SourceFunction已经被标注为废弃,这是因为SourceFunction相关的接口功能相对单一,没有考虑当需要对数据源的数据出现各种问题时的处理,因此Flink即将废弃,而是使用底层的Source。下面的示例,将通过实现Source新方式来实现。
不过在实现自定义之前,要先了解Source的底层原理,在《Flink的官方文档的Data Sources》中有对其详细的描述。官方文档讲得很多,可能让人看得有点迷糊。这里使用主要的源码,来剖析Flink中Source的相关内容,并使用一个自定义示例来演示一下。
1.1 Source
Source的接口。它就像一个工厂类,帮助构造SplitEnumerator和SourceReader以及相应的序列化器。简单来说就是给Flink内部调用声明一些方法,用户通过实现这些方法,Flink才能调用到自定义的SplitEnumerator和SourceReader以及相应的序列化器。下面是Source的方法说明:
public interface Source<T, SplitT extends SourceSplit, EnumChkT>extends SourceReaderFactory<T, SplitT> {/*** 设置该源算子是有界流还是无界流*/Boundedness getBoundedness();/*** 创建分片枚举器(SplitEnumerator)*/SplitEnumerator<SplitT, EnumChkT> createEnumerator(SplitEnumeratorContext<SplitT> enumContext)throws Exception;/*** 从某个检查点创建分片枚举器(SplitEnumerator),*/SplitEnumerator<SplitT, EnumChkT> restoreEnumerator(SplitEnumeratorContext<SplitT> enumContext, EnumChkT checkpoint) throws Exception;/*** 创建数据分片(SourceSplit)的序列化类*/SimpleVersionedSerializer<SplitT> getSplitSerializer();/*** 创建检查点的序列化类*/SimpleVersionedSerializer<EnumChkT> getEnumeratorCheckpointSerializer();
}
Source还继承SourceReaderFactory接口,有一个创建源阅读器(SourceReader)的方法
public interface SourceReaderFactory<T, SplitT extends SourceSplit> extends Serializable {/*** 创建源阅读器(SourceReader)*/SourceReader<T, SplitT> createReader(SourceReaderContext readerContext) throws Exception;
}
1.2 三个关键组件
通过从上面的源码,可以得知通过Source需要创建一些实现的组件,而有三个组件比较关键,如下官方图:
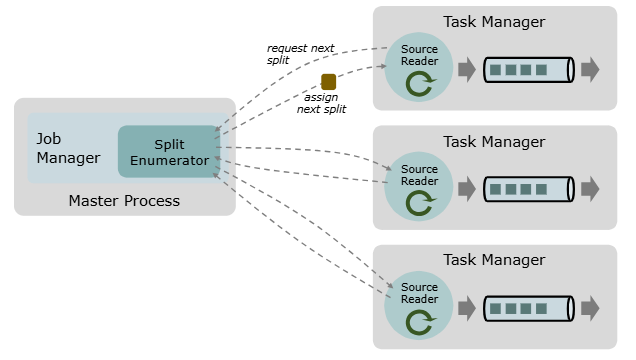
首先是官方图里面,描述了一个基本的内容,一个是源算子实现过程中需要实现三个关键组件,他们在整个流程中扮演很重要角色:
- 分片(SourceSplit) :是对一部分 Source 数据的包装,如一个文件或者日志分区。分片是 Source进行任务分配和数据并行读取的基本粒度。
- 源阅读器(SourceReader) :会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
- 分片枚举器(SplitEnumerator) :会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
看完上面的图以及三个组件之后,你可能有点感觉,但是还是了解不深,这里通过一个比喻的方式来描述整个流程:
分片(SourceSplit):把它比作一个打包好的快递
源阅读器(SourceReader):把它比作一个快递员
分片枚举器(SplitEnumerator):把它比作一个快递分类员
整个流程就是:快递分类员不定期的从仓库里取出物品,将物品按照一定规则打包成一个个快递,查看是否有空闲的快递员,如果有,按照一定规则分发快递给快递员。快递员这边负责实际配送,当快递员送完一个快递之后,回来告诉快递分类员,自己已经空闲,等待快递分类员分发新的快递。
这样描述是不是就比较清楚了,现在再来看看三个组件里面的方法的作用,最后通过一个简单流程图描述整个过程:
分片枚举器(SplitEnumerator)类:
public interface SplitEnumerator<SplitT extends SourceSplit, CheckpointT>extends AutoCloseable, CheckpointListener {/*** 启动一个分片枚举器(SplitEnumerator)都会先调用该方法(一般需要启动一个定时器,不断读取数据并分发数据)* 而SplitEnumeratorContext的callAsync方法提供了非常方便创建一个定时器(当然你也可以自己实现)*/void start();/*** 源阅读器(SourceReader)调用SourceReaderContext#sendSplitRequest(),就是告诉分片枚举器(SplitEnumerator)自己空闲,分片枚举器(SplitEnumerator)可以将其加入到空闲列表*/void handleSplitRequest(int subtaskId, @Nullable String requesterHostname);/*** 添加源阅读器(SourceReader)*/void addReader(int subtaskId);/*** 定时的快照方法,也就是保存当前处理的情况,防止程序挂了,可以从检查点开始,而不是从头开始*/CheckpointT snapshotState(long checkpointId) throws Exception;/*** 关闭方法*/@Overridevoid close() throws IOException;/*** 当所有检查点执行完成时调用该方法*/@Overridedefault void notifyCheckpointComplete(long checkpointId) throws Exception {}/*** 处理SourceEvent。这个方法是用于监听SourceEvent事件,可用于与源阅读器(SourceReader)交互。*/default void handleSourceEvent(int subtaskId, SourceEvent sourceEvent) {}/*** 将数据分片(SourceSplit)添加回分片枚举器(SplitEnumerator)。只有在源阅读器(SourceReader)发生异常读取失败,且没有被检查点保存下来时,告诉SplitEnumerator分片枚举器,这些分片没有被处理*/void addSplitsBack(List<SplitT> splits, int subtaskId);
}源阅读器(SourceReader)类:
public interface SourceReader<T, SplitT extends SourceSplit>extends AutoCloseable, CheckpointListener {/** * 启动一个源阅读器(SourceReader)都会先调用该方法*/void start();/*** 源阅读器(SourceReader)做数据处理,并将数据发送给下游*/InputStatus pollNext(ReaderOutput<T> output) throws Exception;/*** 定时的快照方法,也就是保存当前处理的情况,防止程序挂了,可以从检查点开始,而不是从头开始*/List<SplitT> snapshotState(long checkpointId);/*** 判断源阅读器(SourceReader)自己是否已经处理完数据,如果处理完,调用SourceReaderContext#sendSplitRequest()通知分片枚举器(SplitEnumerator)自己空闲*/CompletableFuture<Void> isAvailable();/*** 将数据分片(SourceSplit)添加到该源阅读器(SourceReader),当分片枚举器(SplitEnumerator)调用assignSplit方法时,会将数据分片(SourceSplit)传输到这个方法,源阅读器(SourceReader)接收数据分片(SourceSplit)*/void addSplits(List<SplitT> splits);/*** 当该源阅读器(SourceReader)不想再处理数据分片(SourceSplit)时,调用该方法。*/void notifyNoMoreSplits();/*** 处理SourceEvent。这个方法是用于监听SourceEvent事件,可用于与分片枚举器(SplitEnumerator)交互。*/default void handleSourceEvents(SourceEvent sourceEvent) {}/*** 当所有检查点执行完成时调用该方法*/@Overridedefault void notifyCheckpointComplete(long checkpointId) throws Exception {}}
数据分片(SourceSplit)类:
public interface SourceSplit {/*** 返回数据分片(SourceSplit)的ID*/String splitId();
}
1.3 源算子的流程
除了三大组件之外,还有2个类上下文的类要知道,分别是SplitEnumeratorContext和SourceReaderContext,它们分别是**分片枚举器(SplitEnumerator)和源阅读器(SourceReader)的上下文信息,通过它们来传递两者之间分配数据的信息。这是因为分片枚举器(SplitEnumerator)和源阅读器(SourceReader)**都是独立的进程或者线程,所以需要通过上下文来传递信息,下面是一个基本流程,顺便也说明每个类的方法在具体流程中的作用。(注意:由于是多进程或线程,因此他们之间顺序并不一定是这样子,只不过是按照一个正常逻辑画一个符合逻辑的版本)
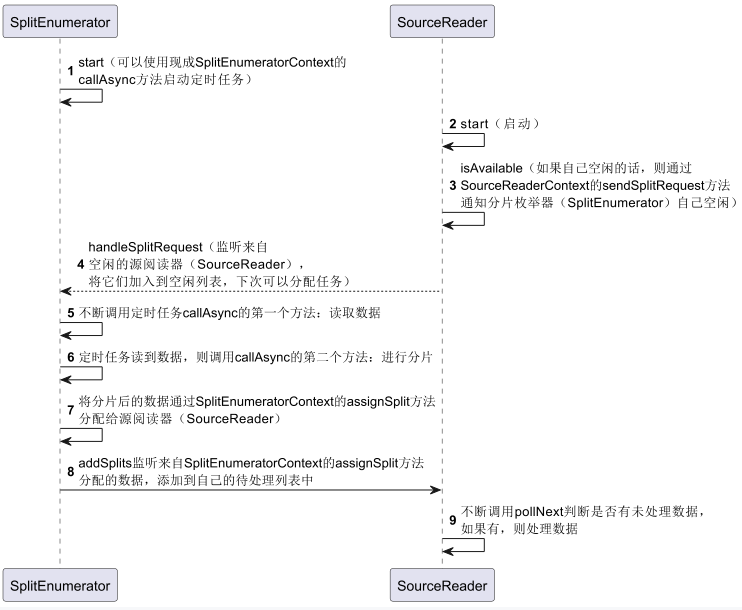
这里还有关于检查点的实现没有列出来。其实可以简单理解检查点是另外一个线程处理,每个一段时间,会将目前的处理中间状态数据都保存下来,下次可以从保存的检查点加载,继续处理,无需重头开始。由于检查点还需后面介绍,这里就不多累述。
2 自定义数据源
接下来,使用一个简单示例,来演示如何自定义Source算子。在日常工作中,读取服务器日志并汇总到一个可视化平台供监控和分析是一个非常常见的场景。在这里假设一个场景:
有一个服务器,在固定的目录下面会按照日期不断生成日志,假设每个5分钟生成一个日志文件,由于日志是不断产生,因此常见写日志的方法是正在写的日志都会是以tmp为后缀文件,写完的日志才会被命名为log为后缀。示例需要读取该文件夹下面以log为后缀的日志,并按照文件分配给TaskManager的源阅读器(SourceReader)处理,源阅读器(SourceReader)将其日志的内容按行读取,然后传送到下游算子,读取完之后删除本地log日志,下游算子只是简单打印出来数据。这样子就模拟了一个采集服务器实时日志的过程。(注意,这里只是模拟从本地读取文件,实际业务中可能文件在远程服务器,这个就需要远程访问读取,这里为了方便就不演示远程读取)
解题思路:使用分片枚举器(SplitEnumerator)定时读取文件夹中的文件,分发给源阅读器(SourceReader),源阅读器(SourceReader)负责读取文件里面的数据,并输出给下一个算子。
代码参考lesson04子模块
2.1 新建lesson04子模块
1)在flink-study父项目的pom中引入dependencyManagement。引入hutool和fastjson作为工具类和序列化使用
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>${hutool.version}</version>
</dependency>
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version>
</dependency>
2)新建lesson04子模块,其pom引入如下:
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><scope>provided</scope></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency>
</dependencies>
2.2 定义检查点及其序列化类
1)新建检查点类CustomSplitEnumeratorCheckpoint (这就保存存储已加载的文件和待分配的数据分片(SourceSplit))
import java.util.LinkedList;
import java.util.Set;/*** 检查点,只需要保存已加载文件名称列表和用于保存待分配的数据分片(SourceSplit)*/
public class CustomSplitEnumeratorCheckpoint {/*** 存储已加载的文件*/private Set<String> loadedFiles;/*** 用于保存待分配的数据分片(SourceSplit)--因为还没有分配给源阅读器(SourceReader)处理*/private LinkedList<CustomSourceSplit> sourceSplitList;public CustomSplitEnumeratorCheckpoint(Set<String> loadedFiles, LinkedList<CustomSourceSplit> sourceSplitList) {this.loadedFiles = loadedFiles;this.sourceSplitList = sourceSplitList;}public Set<String> getLoadedFiles() {return loadedFiles;}public void setLoadedFiles(Set<String> loadedFiles) {this.loadedFiles = loadedFiles;}public LinkedList<CustomSourceSplit> getSourceSplitList() {return sourceSplitList;}public void setSourceSplitList(LinkedList<CustomSourceSplit> sourceSplitList) {this.sourceSplitList = sourceSplitList;}
}
2)新建检查点序列化类CustomEnumeratorCheckpointSerializer,这里使用fastjson来进行序列化
import com.alibaba.fastjson.JSON;
import org.apache.flink.core.io.SimpleVersionedSerializer;import java.io.IOException;/*** 检查点的序列化,由于检查点需要保存到本地磁盘,因此需要序列化。这里使用alibaba的fastjson组件做序列化*/
public class CustomEnumeratorCheckpointSerializer implements SimpleVersionedSerializer<CustomSplitEnumeratorCheckpoint> {@Overridepublic int getVersion() {return 0;}@Overridepublic byte[] serialize(CustomSplitEnumeratorCheckpoint obj) throws IOException {return JSON.toJSONBytes(obj);}@Overridepublic CustomSplitEnumeratorCheckpoint deserialize(int version, byte[] serialized) throws IOException {return JSON.parseObject(serialized, CustomSplitEnumeratorCheckpoint.class);}
}
2.3 定义三大组件
1)新建数据分片的类CustomSourceSplit
import org.apache.flink.api.connector.source.SourceSplit;/*** 数据分片(SourceSplit)*/
public class CustomSourceSplit implements SourceSplit {// 由于我们是按照文件分发的规则,因此数据分片(SourceSplit)我们只需要将文件的路径给源阅读器(SourceReader)即可private String path;public CustomSourceSplit() {}public CustomSourceSplit(String path) {this.path = path;}@Overridepublic String splitId() {return path;}public String getPath() {return path;}public void setPath(String path) {this.path = path;}
}
2)新建分片枚举器类CustomSplitEnumerator
/*** 分片枚举器(SplitEnumerator)*/
public class CustomSplitEnumerator implements SplitEnumerator<CustomSourceSplit, CustomSplitEnumeratorCheckpoint> {// 分片枚举器(SplitEnumerator)上下文,用于与源阅读器(SourceReader)通讯private SplitEnumeratorContext<CustomSourceSplit> splitSplitEnumeratorContext;// 定时查询文件夹的时间间隔private long refreshInterval;// 文件路径private File fileDir;// 文件过滤器private LogFileFilter logFileFilter;/*** 用于保存待分配的数据分片(SourceSplit)*/private LinkedList<CustomSourceSplit> sourceSplitList;/*** 用于保存空闲的CustomSourceReader*/private List<Integer> sourceReaderList;/*** 已加载文件名称列表*/private Set<String> loadedFiles;/*** 新建CustomSplitEnumerator*/public CustomSplitEnumerator(SplitEnumeratorContext<CustomSourceSplit> splitSplitEnumeratorContext, long refreshInterval, String path) {this.splitSplitEnumeratorContext = splitSplitEnumeratorContext;this.refreshInterval = refreshInterval;this.fileDir = new File(path);this.logFileFilter = new LogFileFilter();this.sourceSplitList = new LinkedList<>();this.sourceReaderList = new ArrayList<>();this.loadedFiles = new ConcurrentSkipListSet<>();}/*** 从某个检查点新建CustomSplitEnumerator*/public CustomSplitEnumerator(SplitEnumeratorContext<CustomSourceSplit> splitSplitEnumeratorContext, long refreshInterval, String path, LinkedList<CustomSourceSplit> sourceSplitList, Set<String> loadedFiles) {this.splitSplitEnumeratorContext = splitSplitEnumeratorContext;this.refreshInterval = refreshInterval;this.fileDir = new File(path);this.logFileFilter = new LogFileFilter();this.sourceSplitList = sourceSplitList;this.sourceReaderList = new ArrayList<>();this.loadedFiles = loadedFiles;}/*** 启动方法:这里使用SplitEnumeratorContext的callAsync方法启动一个定时任务(我们也可以自己写)*/@Overridepublic void start() {this.splitSplitEnumeratorContext.callAsync(this::loadFiles, // 定时轮询方法this::distributeSplit, // 如果读取到数据,则使用该方法进行分片数据refreshInterval, // 启动多少秒之后开始读取文件夹refreshInterval); // 间隔多少秒读取一次文件夹}/*** 定时扫描指定路径,如果发现新文件,返回数据*/private List<CustomSourceSplit> loadFiles() {File[] files = fileDir.listFiles(logFileFilter);if (files==null|| files.length == 0) {return new ArrayList<>();}//将加载出的文件放入loadedFiles并包装为分片(FileSourceSplit)返回List<CustomSourceSplit> result = new ArrayList<>();for(File file : files){// 加入到列表中,防止重复if(loadedFiles.add(file.getAbsolutePath())){result.add(new CustomSourceSplit(file.getAbsolutePath()));}}return result;}/*** 如果读取到数据,则使用该方法进行分片数据,其中assignSplit方法就是分配给源阅读器(SourceReader)*/private void distributeSplit(List<CustomSourceSplit> list, Throwable error) {sourceSplitList.addAll(list);if (sourceSplitList.isEmpty()) {return;}// 看看空闲的sourceReaderList列表有没有空闲的源阅读器(SourceReader)Iterator<Integer> iterator = sourceReaderList.iterator();while (iterator.hasNext()) {Integer next = iterator.next();// 拿出一个数据分片CustomSourceSplit poll = sourceSplitList.poll();if (poll == null) {break;}// 设置给源阅读器(SourceReader)splitSplitEnumeratorContext.assignSplit(poll, next);iterator.remove();}}/*** 源阅读器(SourceReader)调用SourceReaderContext#sendSplitRequest(),* 就是告诉分片枚举器(SplitEnumerator)自己空闲,分片枚举器(SplitEnumerator)可以将其加入到空闲列表*/@Overridepublic void handleSplitRequest(int subtaskId, @Nullable String requesterHostname) {sourceReaderList.add(subtaskId);}/*** 将数据分片(SourceSplit)添加回分片枚举器(SplitEnumerator)。* 只有在源阅读器(SourceReader)发生异常读取失败,且没有被检查点保存下来时,告诉SplitEnumerator分片枚举器,这些分片没有被处理*/@Overridepublic void addSplitsBack(List splits, int subtaskId) {sourceSplitList.addAll(splits);}/*** 添加源阅读器(SourceReader),这里在我们本次演示无需做任何内容*/@Overridepublic void addReader(int subtaskId) {}/*** 定时的快照方法,也就是保存当前处理的情况,防止程序挂了,可以从检查点开始,而不是从头开始*/@Overridepublic CustomSplitEnumeratorCheckpoint snapshotState(long checkpointId) throws Exception {return new CustomSplitEnumeratorCheckpoint(loadedFiles, sourceSplitList);}/*** 关闭方法,这里在我们本次演示无需做任何内容*/@Overridepublic void close() throws IOException {}/*** 处理SourceEvent。这个方法是用于监听SourceEvent事件,可用于与源阅读器(SourceReader)交互* 这里监听来自源阅读器(SourceReader)的CustomSourceEvent事件,删除loadedFiles中已经完成读取的文件,防止loadedFiles过大* 这个方法会将sourceReader已完成读取并已通过检查点的文件删除。*/@Overridepublic void handleSourceEvent(int subtaskId, SourceEvent sourceEvent) {if (sourceEvent instanceof CustomSourceEvent) {Set<String> fileSplits = ((CustomSourceEvent) sourceEvent).getSplits();loadedFiles.removeAll(fileSplits);}}/*** 过滤文件名,只读取log结尾的文件名且是文件的*/public static class LogFileFilter implements FileFilter {private String suffixName = ".log";public LogFileFilter() {}public LogFileFilter(String suffixName) {this.suffixName = suffixName;}@Overridepublic boolean accept(File pathname) {return pathname.isFile() && pathname.getName().endsWith(suffixName);}}
}
3)新建源阅读器类CustomSourceReader
import cn.hutool.core.io.FileUtil;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.connector.source.ReaderOutput;
import org.apache.flink.api.connector.source.SourceReader;
import org.apache.flink.api.connector.source.SourceReaderContext;
import org.apache.flink.core.io.InputStatus;import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Queue;
import java.util.Set;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ConcurrentLinkedDeque;
import java.util.stream.Collectors;/*** 源阅读器(SourceReader)*/
public class CustomSourceReader implements SourceReader<String, CustomSourceSplit> {/*** 源阅读器(SourceReader)的上下文,用于跟分片枚举器(SplitEnumerator)通讯使用*/private final SourceReaderContext sourceReaderContext;/*** 用于存放从文件中读取的数据的,由于是按行读取,因此每一行存储一个String*/private Queue<String> waitQueue = new ConcurrentLinkedDeque<>();/*** 用于存放从分片枚举器(SplitEnumerator)接收到的分片*/private List<CustomSourceSplit> allSplit = new ArrayList<>();/*** 用于存储已读取完成的分片,可用于删除*/private List<CustomSourceSplit> finishSplit;/*** 用于标记数据是否读取完成*/private CompletableFuture<Void> completableFuture;public CustomSourceReader(SourceReaderContext sourceReaderContext) {this.sourceReaderContext = sourceReaderContext;this.completableFuture = new CompletableFuture<>();this.finishSplit = new ArrayList<>();}/*** 源阅读器(SourceReader)的启动,这里在我们本次演示无需做任何内容*/@Overridepublic void start() {}/*** 源阅读器(SourceReader)数据处理函数,这里从waitQueue中读到数据,并发送到下游算子,不做任何处理*/@Overridepublic InputStatus pollNext(ReaderOutput<String> output) throws Exception {if (!waitQueue.isEmpty()) {String poll = waitQueue.poll();if (StringUtils.isNotEmpty(poll)) {output.collect(poll);}/*** MORE_AVAILABLE - SourceReader 有可用的记录。* NOTHING_AVAILABLE - SourceReader 现在没有可用的记录,但是将来可能会有记录可用。* END_OF_INPUT - SourceReader 已经处理完所有记录,到达数据的尾部。这意味着 SourceReader 可以终止任务了。*/return InputStatus.MORE_AVAILABLE;}return InputStatus.NOTHING_AVAILABLE;}/*** 保存快照方法*/@Overridepublic List<CustomSourceSplit> snapshotState(long checkpointId) {if (allSplit.isEmpty()) {return new ArrayList<>();}synchronized (allSplit) {finishSplit.addAll(allSplit);allSplit.clear();}return finishSplit;}/*** 是否已经处理完数据,如果处理完,调用SourceReaderContext#sendSplitRequest()通知分片枚举器(SplitEnumerator)自己空闲可以分配新数据*/@Overridepublic CompletableFuture<Void> isAvailable() {if (this.completableFuture.isDone()) {this.completableFuture = new CompletableFuture<>();}//分片枚举器(SplitEnumerator)this.sourceReaderContext.sendSplitRequest();return this.completableFuture;}/*** 拿到分片枚举器(SplitEnumerator)分给自己的数据分片(SourceSplit)* 按行读取文件并将读取每行数据放到该源阅读器(SourceReader)的waitQueue,供pollNext处理数据*/@Overridepublic void addSplits(List<CustomSourceSplit> splits) {for (CustomSourceSplit split : splits) {//按行读取数据List<String> lines = FileUtil.readLines(split.getPath(), StandardCharsets.UTF_8);waitQueue.addAll(lines);}//设置数据已经读取完成this.completableFuture.complete(null);//将分片加入到allSplitsynchronized (allSplit) {allSplit.addAll(splits);}}/*** 当该源阅读器(SourceReader)不想再处理数据分片(SourceSplit)时,调用该方法。这里在我们本次演示无需做任何内容*/@Overridepublic void notifyNoMoreSplits() {}/*** 当该源阅读器(SourceReader)关闭时,调用该方法。这里在我们本次演示无需做任何内容*/@Overridepublic void close() throws Exception {}/*** 当所有检查点执行完成时调用该方法,这里我们清理掉已经读取的日志文件*/@Overridepublic void notifyCheckpointComplete(long checkpointId) throws Exception {if (finishSplit.isEmpty()) {return;}//将已完成检查点的数据删除Set<String> deleteFile = finishSplit.stream().map(it -> {FileUtil.del(it.getPath());return it.getPath();}).collect(Collectors.toSet());finishSplit.clear();//将已删除的文件通过事件通知分片枚举器(SplitEnumerator),分片枚举器(SplitEnumerator)可以删除loadedFile列表this.sourceReaderContext.sendSourceEventToCoordinator(new CustomSourceEvent(deleteFile));}
}4)新建事件类CustomSourceEvent,用于通知使用:
import org.apache.flink.api.connector.source.SourceEvent;import java.util.Set;/*** SourceEvent事件,用于源阅读器(SourceReader)删除文件后通知分片枚举器(SplitEnumerator)*/
public class CustomSourceEvent implements SourceEvent {private Set<String> splits;public CustomSourceEvent() {}public CustomSourceEvent(Set<String> splits) {this.splits = splits;}public Set<String> getSplits() {return splits;}public void setSplits(Set<String> splits) {this.splits = splits;}
}
5)新建数据分片的序列化类CustomSplitSerializer
/*** 数据分片的序列化,由于分片枚举器(SplitEnumerator)和源阅读器(SourceReader)可能在不同服务器,因此数据分片需要序列化传输。这里使用alibaba的fastjson组件做序列化*/
public class CustomSplitSerializer implements SimpleVersionedSerializer<CustomSourceSplit> {@Overridepublic int getVersion() {return 0;}@Overridepublic byte[] serialize(CustomSourceSplit obj) throws IOException {return JSON.toJSONBytes(obj);}@Overridepublic CustomSourceSplit deserialize(int version, byte[] serialized) throws IOException {return JSON.parseObject(serialized, CustomSourceSplit.class);}
}
2.4 定义Source和main方法类
1)新建源算子类CustomSource
/*** 自定义的Source*/
public class CustomSource implements Source<String, CustomSourceSplit, CustomSplitEnumeratorCheckpoint> {// 文件路径private final String dir;// 定时查询文件夹的时间间隔private final long refreshInterval;public CustomSource(String dir, long refreshInterval) {this.dir = dir;this.refreshInterval = refreshInterval;}/*** 设置该源算子是有界流还是无界流*/@Overridepublic Boundedness getBoundedness() {return Boundedness.CONTINUOUS_UNBOUNDED;}/*** 创建分片枚举器(SplitEnumerator)*/@Overridepublic SplitEnumerator<CustomSourceSplit, CustomSplitEnumeratorCheckpoint> createEnumerator(SplitEnumeratorContext<CustomSourceSplit> enumContext) throws Exception {return new CustomSplitEnumerator(enumContext, refreshInterval, dir);}/*** 从某个检查点创建分片枚举器(SplitEnumerator),*/@Overridepublic SplitEnumerator<CustomSourceSplit, CustomSplitEnumeratorCheckpoint> restoreEnumerator(SplitEnumeratorContext<CustomSourceSplit> enumContext, CustomSplitEnumeratorCheckpoint checkpoint) throws Exception {return new CustomSplitEnumerator(enumContext, refreshInterval, dir, checkpoint.getSourceSplitList(), checkpoint.getLoadedFiles());}/*** 创建数据分片(SourceSplit)的序列化类*/@Overridepublic SimpleVersionedSerializer<CustomSourceSplit> getSplitSerializer() {return new CustomSplitSerializer();}/*** 创建检查点的序列化类*/@Overridepublic SimpleVersionedSerializer<CustomSplitEnumeratorCheckpoint> getEnumeratorCheckpointSerializer() {return new CustomEnumeratorCheckpointSerializer();}/*** 创建源阅读器(SourceReader)*/@Overridepublic SourceReader<String, CustomSourceSplit> createReader(SourceReaderContext readerContext) throws Exception {return new CustomSourceReader(readerContext);}
}
2)新建Flink的执行类CustomSourceDemo
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** Flink的执行类*/
public class CustomSourceDemo {public static void main(String[] args) throws Exception {// 1. 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointInterval(60000); // 配置每60秒自动保存一个检查点// 2. 读取数据 -- 使用我们自定义的数据源。读取E:\mylogs目录,并且设置每隔5秒读取一次目录里面的文件列表CustomSource customSource = new CustomSource("E:\\mylogs", 10000);DataStreamSource<String> dataStreamSource = env.fromSource(customSource, WatermarkStrategy.noWatermarks(), "custom");dataStreamSource.setParallelism(1); // 这里配置1个并行度,只是为了方便debug// 3. 输出dataStreamSource.print();// 执行env.execute();}}
2.5 运行测试
1)在E:\mylogs目录下建立一些以log结尾的文件,并输入内容。还可以建立非log结尾的目录以测试是否会被读取。
2)运行CustomSourceDemo:

上面的示例基本实现了前面定下来的需求,但是你会看到整个过程还是挺复杂,而示例其实还是比较简单的处理方式,中间很多细节还需打磨。Flink也提供SourceReaderBase等更高层的实现类,封装解决底层的一些常见问题,所以大家不必从最底层的SourceReader开始。
结语:通过本章对Data Stream API的源算子底层原理做了一个讲解,并通过一个实际案例自定义源算子。接下来还继续讲解Data Stream API的其它相关内容。