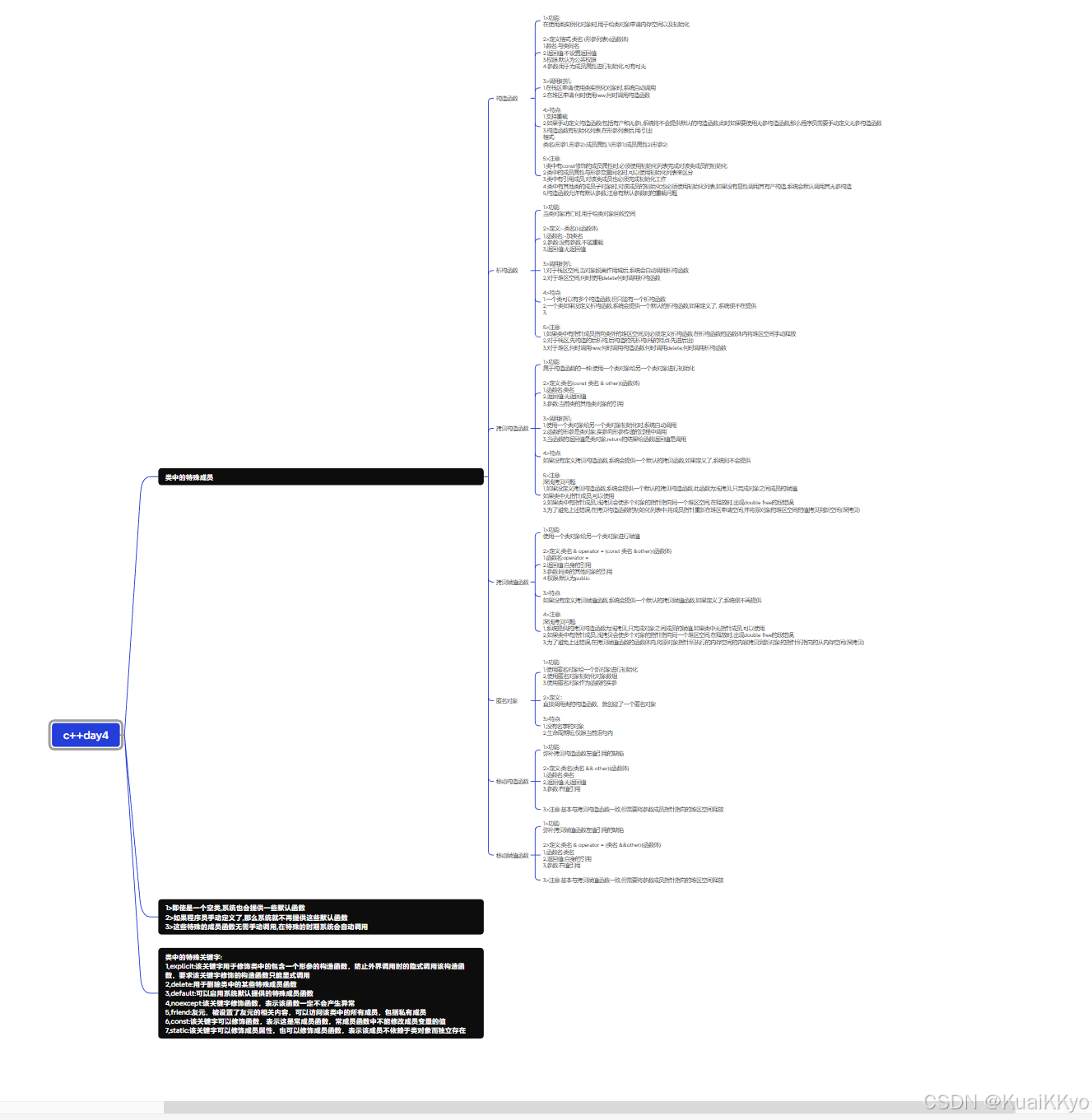
2024年中国研究生数学建模竞赛B题 (WLAN组网吞吐量机理建模+GBDT+LSTM 进阶建模文章)
全文请从 底部名片 处获取哦~



问题重述和分析
问题重述
本题旨在基于实际测量的WLAN(无线局域网)数据,建立一个精确的系统吞吐量预测模型。具体而言,提供了多个包含网络拓扑、业务流量、节点间RSSI、信道接入机制等基本信息的测试集,以及部分统计信息,如AP(接入点)的发送时长、选用的调制编码方案(MCS)、空间流数(NSS)、丢包率(PER)、吞吐量等。
需要解决的问题包括:
- 分析各参数对AP发送机会(发送数据帧序列的总时长)的影响,并预测AP的发送机会。
- 建立模型,预测AP发送数据时选用最多次数的(MCS, NSS)。
- 建立模型,预测系统的总吞吐量。
- 对模型的精度进行评估,绘制预测误差的累积分布函数(CDF),并计算模型的精度。
整体问题分析
赛题的核心是建立一个能够准确预测WLAN系统吞吐量的模型。在高密度部署场景下,节点密集度增加,导致干扰和碰撞加剧,实际带宽和数据传输速率下降。因此,需要准确地预测吞吐量,以优化WLAN系统性能。
主要挑战:
- 多因素耦合:节点间的RSSI、CCA门限、NAV机制、业务流量等因素相互影响,导致AP的发送机会和PHY层参数的选择具有复杂性。
- 数据复杂性:提供的数据集包含大量的参数,需要从中提取关键特征,并进行合理的简化和假设。
- 建模精度要求高:需要在模型中充分考虑各种影响因素,以满足赛题对预测精度的要求。
数据说明分析
赛题提供的数据集主要分为两部分:
-
测试基本信息:包括网络拓扑、业务流量、门限、节点间RSSI等。这些信息作为模型的输入参数,需要分析其对AP发送机会和PHY层参数的影响。
-
数据帧统计信息:包括AP发送数据的时长、选用的(MCS, NSS)、丢包率(PER)、吞吐量等。这些信息作为模型的输出参数,或者用于模型验证。
需要特别注意的是:
-
RSSI的多种形式:不同的RSSI用于不同的判决,如最大值用于CCA门限判决,平均值用于NAV门限判决,所有天线RSSI的和用于解码信号。
-
业务流量类型:UDP和TCP流量的特性不同,影响AP的发送行为,需要在模型中区分处理。
附录资料深入分析

- 随机回退和二进制指数退避算法
AP在信道竞争中采用二进制指数退避算法来决定发送时机。
竞争窗口(CW)在每次传输失败后翻倍,传输成功后重置为CWmin。
退避计数器(BO)在 0 , C W − 1 0, CW - 1 0,CW−1范围内随机选取,决定了回退的时隙数。
- 数据帧序列和RTS-CTS机制
采用RTS-CTS机制可以减少碰撞,提高信道利用率。
一个完整的帧序列包括:RTS、CTS、数据帧、ACK,以及相应的帧间隔(DIFS、SIFS)。
- 聚合机制

采用AMSDU和AMPDU聚合,可以提高小包传输的效率。
聚合的PPDU时长不超过4.5ms,聚合的MSDU和MPDU个数有限制。
- 业务流量类型
UDP流量:单向数据流,报文大小为1500 Bytes,发送间隔服从泊松分布。
TCP流量:双向数据流,需要考虑上行的TCP ACK。
问题建模与求解
问题一:AP发送机会的分析与预测
目标:根据实测数据,分析各参数对AP发送机会(seq_time)的影响,并预测AP的发送机会。
分析各参数对AP发送机会的影响
- 节点间RSSI
影响:AP之间的RSSI决定了它们是否能“听”到彼此,以及干扰的程度。
情况分析:
RSSI > ED门限(-62dBm):AP能够检测到对方的传输,避免同时发送,导致发送机会减少。
NAV门限 < RSSI ≤ PD门限(-82dBm):AP可能错过对方的Preamble,导致异步传输,增加发送机会,但也可能增加碰撞概率。
RSSI ≤ NAV门限:AP无法感知对方的存在,可能导致更多的信道占用。
- CCA门限
影响:CCA门限决定了AP对信道忙闲的判断。
判决规则:
包检测(PD)门限:用于检测Wi-Fi报文的Preamble。
能量检测(ED)门限:用于检测非Wi-Fi报文。
判决条件:
RSSI max ≥ PD ⟹ 信道繁忙 \text{RSSI}_{\text{max}} \geq \text{PD} \implies \text{信道繁忙} RSSImax≥PD⟹信道繁忙
PD > RSSI max ≥ ED ⟹ 信道繁忙 \text{PD} > \text{RSSI}_{\text{max}} \geq \text{ED} \implies \text{信道繁忙} PD>RSSImax≥ED⟹信道繁忙
RSSI max < ED ⟹ 信道空闲 \text{RSSI}_{\text{max}} < \text{ED} \implies \text{信道空闲} RSSImax<ED⟹信道空闲
- NAV机制
影响:NAV门限决定了AP是否会进入静默期。
情况分析:
RSSI ≥ NAV门限:AP接收到相邻AP的帧,更新NAV,进入静默期,发送机会减少。
RSSI < NAV门限:AP无法更新NAV,不进入静默期,可能导致信道竞争加剧。
- 业务流量
影响:业务流量的类型(UDP/TCP)、数据包大小、发送间隔等影响AP的发送需求。
分析:
UDP流量:发送间隔服从泊松分布,发送需求较稳定。
TCP流量:由于需要接收TCP ACK,发送需求可能受到网络状况影响。
影响性强弱排序
- 节点间RSSI
- CCA门限
- NAV机制
- 业务流量参数
建模方法
- 数据预处理
输入特征提取:
节点间RSSI: RSSI AP i − AP j \text{RSSI}_{\text{AP}_i-\text{AP}_j} RSSIAPi−APj
CCA门限:PD、ED值
NAV门限:NAV值
业务流量参数:协议类型、数据包长度(pkt_len)
- 统计分析
相关性分析:
计算各输入特征与seq_time的皮尔逊相关系数。
识别主要影响因素。
可视化:
绘制散点图,观察特征与seq_time之间的关系。
可能发现线性或非线性的关系。
- 数学建模
多元回归模型:
建立回归模型,将seq_time作为因变量,输入特征作为自变量。
回归模型形式:
seq_time i = β 0 + β 1 ⋅ RSSI i + β 2 ⋅ CCA i + β 3 ⋅ NAV i + β 4 ⋅ Traffic i + ε i \text{seq\_time}_i = \beta_0 + \beta_1 \cdot \text{RSSI}_{i} + \beta_2 \cdot \text{CCA}_{i} + \beta_3 \cdot \text{NAV}_{i} + \beta_4 \cdot \text{Traffic}_{i} + \varepsilon_i seq_timei=β0+β1⋅RSSIi+β2⋅CCAi+β3⋅NAVi+β4⋅Traffici+εi
其中, β 0 , β 1 , β 2 , β 3 , β 4 \beta_0, \beta_1, \beta_2, \beta_3, \beta_4 β0,β1,β2,β3,β4为回归系数, ε i \varepsilon_i εi为误差项。
非线性模型:
如果发现特征与seq_time之间的关系非线性,可以考虑多项式回归或对数变换。
- 机器学习模型
模型选择:
决策树、随机森林、支持向量机(SVM)、人工神经网络(ANN)等。
优点:
能够捕捉复杂的非线性关系。
对于高维特征具有较好的处理能力。
- 模型训练与验证
训练集与验证集划分:
使用交叉验证或留出法,评估模型的泛化能力。
模型评估指标:
均方误差(MSE)、平均绝对误差(MAE)、决定系数( R 2 R^2 R2)等。
- 预测测试集
使用训练好的模型,对test_set_1_2ap和test_set_1_3ap进行预测,得到每个AP的seq_time。
数学公式与推导
- 发送概率模型
假设:
AP采用CSMA/CA机制,发送概率与竞争窗口有关。
发送概率:
τ i = 2 W i + 1 \tau_i = \frac{2}{W_i + 1} τi=Wi+12
其中, W i W_i Wi为AP_i的竞争窗口大小。
- 碰撞概率
AP_i的碰撞概率:
P collision , i = 1 − ∏ j ≠ i ( 1 − τ j ) P_{\text{collision}, i} = 1 - \prod_{j \neq i} (1 - \tau_j) Pcollision,i=1−j=i∏(1−τj)
- 成功发送概率
AP_i的成功发送概率:
P success , i = τ i ∏ j ≠ i ( 1 − τ j ) P_{\text{success}, i} = \tau_i \prod_{j \neq i} (1 - \tau_j) Psuccess,i=τij=i∏(1−τj)
- 平均发送时长
AP_i的平均发送时长:
seq_time i = test_dur × P success , i × T tx \text{seq\_time}_i = \text{test\_dur} \times P_{\text{success}, i} \times T_{\text{tx}} seq_timei=test_dur×Psuccess,i×Ttx
其中, T tx T_{\text{tx}} Ttx为一次成功发送的时长。
代码和可视化结果如下
# 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split# 设置中文字体
from matplotlib import rcParamsrcParams['font.sans-serif'] = ['SimHei']
rcParams['axes.unicode_minus'] = False# 读取数据
training_data_path = 'training_set_2ap_loc0_nav82.csv'
test_data_path = 'test_set_1_2ap.csv'# 加载数据集
df_train = pd.read_csv(training_data_path)
df_test = pd.read_csv(test_data_path)# 打印训练数据和测试数据的前几行,了解数据结构
print("训练数据前几行:")
print(df_train.head())
print("测试数据前几行:")
print(df_test.head())# 数据分析
print("训练数据的描述性统计:")
print(df_train.describe())# 缺失值分析
print("训练数据的缺失值统计:")
print(df_train.isnull().sum())# 将数据分为数值列和非数值列# 全文详见底部名片加群获取~# 将数值列和分类列合并
df_train_imputed = pd.concat([df_train_numeric_imputed, df_train_categorical_imputed], axis=1)# 对分类列进行编码(Label Encoding)
label_encoders = {}
for col in categorical_cols:le = LabelEncoder()df_train_imputed[col] = le.fit_transform(df_train_imputed[col])label_encoders[col] = le# 假设目标列是 'throughput',如果实际目标列不同,请根据实际情况修改
if 'throughput' in df_train.columns:X = df_train_imputed.drop(columns=['throughput']) # 特征y = df_train_imputed['throughput'] # 目标
else:raise KeyError("训练数据中没有找到目标列 'throughput',请检查列名或修改代码中的目标列名称")# 划分训练集和验证集
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.8, random_state=42)# 创建GBDT模型
gbdt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)# 训练模型
gbdt.fit(X_train, y_train)# 训练集和验证集上的预测
y_train_pred = gbdt.predict(X_train)
y_valid_pred = gbdt.predict(X_valid)# 计算RMSE
train_rmse = np.sqrt(mean_squared_error(y_train, y_train_pred))
valid_rmse = np.sqrt(mean_squared_error(y_valid, y_valid_pred))print(f"训练集上的RMSE: {train_rmse}")
print(f"验证集上的RMSE: {valid_rmse}")# 对测试数据进行同样的预处理
df_test_numeric_imputed = pd.DataFrame(imputer_numeric.transform(df_test[numeric_cols]), columns=numeric_cols)
df_test_categorical_imputed = pd.DataFrame(imputer_categorical.transform(df_test[categorical_cols]), columns=categorical_cols)# 将数值列和分类列合并
df_test_imputed = pd.concat([df_test_numeric_imputed, df_test_categorical_imputed], axis=1)# 对测试数据的分类列进行编码(与训练数据一致),并处理新的标签
for col in categorical_cols:if col in label_encoders:le = label_encoders[col]# 处理未见过的标签,将新标签映射为一个特殊的未知标签编码df_test_imputed[col] = df_test_imputed[col].apply(lambda x: le.transform([x])[0] if x in le.classes_ else -1)# 在测试集中寻找目标列并进行预测
if 'throughput' in df_test.columns:X_test = df_test_imputed.drop(columns=['throughput'], errors='ignore')
else:X_test = df_test_imputed # 如果测试集没有目标列 'throughput'# 进行预测
test_predictions = gbdt.predict(X_test)# 将预测结果保存到文件中
df_test['throughput_predictions'] = test_predictions
output_path = 'test_predictions.csv'
df_test.to_csv(output_path, index=False)print(f"预测完成,结果已保存到 {output_path} 文件中。")# 可视化:预测值 vs 真实值,特征重要性和热力图
plt.figure(figsize=(16, 12))# 子图1:训练集预测值 vs 真实值
plt.subplot(2, 2, 1)
plt.scatter(y_train, y_train_pred, alpha=0.5, color='b')
plt.title("训练集: 预测值 vs 真实值")
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.grid(True)# 子图2:验证集预测值 vs 真实值
plt.subplot(2, 2, 2)
plt.scatter(y_valid, y_valid_pred, alpha=0.5, color='g')
plt.title("验证集: 预测值 vs 真实值")
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.grid(True)# 子图3:特征重要性
plt.subplot(2, 2, 3)
importances = gbdt.feature_importances_
indices = np.argsort(importances)[::-1]
plt.barh(range(X_train.shape[1]), importances[indices], align='center')
plt.yticks(range(X_train.shape[1]), [X_train.columns[i] for i in indices])
plt.title("特征重要性")
plt.xlabel("重要性得分")# 子图4:相关性热力图
plt.subplot(2, 2, 4)
corr_matrix = df_train_imputed.corr()
sns.heatmap(corr_matrix, cmap='coolwarm', annot=False)
plt.title("特征相关性热力图")# 显示图表
plt.tight_layout()
plt.show()



问题二:AP的(MCS, NSS)选择预测
目标:预测AP发送数据时选用最多次数的(MCS, NSS)。
分析影响因素
- 信号与干扰
信号功率:AP到STA的RSSI,记为 P signal P_{\text{signal}} Psignal。
干扰功率:其他AP到STA的RSSI,记为 P interference P_{\text{interference}} Pinterference。
- SINR计算
公式:
省略部分内容
其中, P noise P_{\text{noise}} Pnoise为噪声功率。
- 传输方式的影响
同步传输:干扰较小,SINR较高。
异步传输:干扰较大,SINR降低。
- PER与SINR的关系
PER模型:
PER = e − α ( SINR − β ) \text{PER} = e^{-\alpha (\text{SINR} - \beta)} PER=e−α(SINR−β)
其中, α \alpha α、 β \beta β为拟合参数。
建模方法
- SINR计算
信号功率:
P signal = sta_from_ap_x_sum_ant_rssi P_{\text{signal}} = \text{sta\_from\_ap\_x\_sum\_ant\_rssi} Psignal=sta_from_ap_x_sum_ant_rssi
干扰功率:
P interference = ∑ j ≠ i sta_from_ap_j_sum_ant_rssi P_{\text{interference}} = \sum_{j \neq i} \text{sta\_from\_ap\_j\_sum\_ant\_rssi} Pinterference=j=i∑sta_from_ap_j_sum_ant_rssi
噪声功率:可设定为常数,例如, P noise = − 90 dBm P_{\text{noise}} = -90\, \text{dBm} Pnoise=−90dBm。
- (MCS, NSS)映射
建立映射表:
根据标准或实测数据,确定SINR与(MCS, NSS)的对应关系。
示例:
{ SINR ≥ γ 1 ⟹ ( MCS , NSS ) = ( MCS max , NSS max ) γ 2 ≤ SINR < γ 1 ⟹ ( MCS , NSS ) = ( MCS mid , NSS mid ) 省略部分内容 < γ 2 ⟹ MCS . . . . . . \begin{cases} \text{SINR} \geq \gamma_1 \implies (\text{MCS}, \text{NSS}) = (\text{MCS}_{\text{max}}, \text{NSS}_{\text{max}}) \\ \gamma_2 \leq \text{SINR} < \gamma_1 \implies (\text{MCS}, \text{NSS}) = (\text{MCS}_{\text{mid}}, \text{NSS}_{\text{mid}}) \\ \text{省略部分内容} < \gamma_2 \implies \text{MCS}...... \end{cases} ⎩ ⎨ ⎧SINR≥γ1⟹(MCS,NSS)=(MCSmax,NSSmax)γ2≤SINR<γ1⟹(MCS,NSS)=(MCSmid,NSSmid)省略部分内容<γ2⟹MCS......
- 分类模型
使用机器学习算法:
多分类模型,如决策树、随机森林、支持向量机(SVM)、神经网络等。
特征:
SINR、信号功率、干扰功率、传输方式(同步/异步)、PER等。
目标变量:
(MCS, NSS)组合。
- 模型训练
数据集:
使用训练集中的数据,提取特征和目标变量。
模型评估:
准确率、召回率、F1-score等。
- 预测测试集
对于test_set_2_2ap和test_set_2_3ap,计算SINR,输入模型,预测(MCS, NSS)。
问题二部分可视化展示

问题三:系统吞吐量的建模与预测
目标:预测网络的总吞吐量。
步骤
- 获取发送时长(seq_time)
使用问题一的预测结果。
- 确定PHY速率(PHY Rate)
使用问题二的(MCS, NSS)预测结果,查表获取PHY Rate。
PHY Rate查表:
例如,对于20MHz带宽,MCS和NSS的组合对应的PHY Rate。
- 计算有效传输时间
公式:
省略部分内容
- 计算成功传输的比特数
公式:
省略部分内容
- 考虑聚合机制
PPDU有效载荷计算:
PPDU有效载荷 = num_ppdu × pkt_len × 8 bits \text{PPDU有效载荷} = \text{num\_ppdu} \times \text{pkt\_len} \times 8\, \text{bits} PPDU有效载荷=num_ppdu×pkt_len×8bits
吞吐量计算修正:
省略部分内容
- 计算每个AP的吞吐量
公式:
Throughput i = 成功传输的比特数 i test_dur \text{Throughput}_i = \frac{\text{成功传输的比特数}_i}{\text{test\_dur}} Throughputi=test_dur成功传输的比特数i
- 系统总吞吐量
公式:
省略部分内容
模型优化
-
PER模型的精细化:
- 根据SINR与PER的关系,建立更精确的模型。
- 可能采用分段函数或插值方法。
-
协议开销的考虑:
- 考虑RTS、CTS、ACK等帧的开销。
- 修正有效传输时间。
-
调整因子:
- 根据实测数据,加入调整因子,提高模型精度。
问题三部分可视化展示

目标:评估模型的精度,绘制预测误差的CDF曲线。
步骤
- 计算预测误差(error)
公式:
error i = 预测吞吐量 i − 实测吞吐量 i 实测吞吐量 i × 100 % \text{error}_i = \frac{\text{预测吞吐量}_i - \text{实测吞吐量}_i}{\text{实测吞吐量}_i} \times 100\% errori=实测吞吐量i预测吞吐量i−实测吞吐量i×100%
- 绘制CDF曲线
步骤:
将所有error按从小到大排序,形成序列 { error ( 1 ) , error ( 2 ) , … , error ( N ) } \{\text{error}_{(1)}, \text{error}_{(2)}, \ldots, \text{error}_{(N)}\} {error(1),error(2),…,error(N)}。
计算累积分布函数(CDF):
省略部分内容
绘制图形:
横轴为error,纵轴为CDF。
- 模型精度评估
定义模型精度:
找到使CDF达到90%的error值,记为 ERROR 90 \text{ERROR}_{90} ERROR90。
模型精度为:
省略部分内容
解释:
当90%的预测误差小于 ERROR 90 \text{ERROR}_{90} ERROR90时,模型精度越高, ERROR 90 \text{ERROR}_{90} ERROR90越小。
- 分别评估
每个AP的吞吐量预测精度:
对每个AP的error单独计算CDF,得到AP级别的模型精度。
系统吞吐量的预测精度:
对所有AP的总吞吐量计算error和CDF,得到系统级别的模型精度。
附录:关键公式与参数
-
SINR计算公式
SINR = P signal P interference + P noise \text{SINR} = \frac{P_{\text{signal}}}{P_{\text{interference}} + P_{\text{noise}}} SINR=Pinterference+PnoisePsignal
-
PER模型
PER = e − α ( SINR − β ) \text{PER} = e^{-\alpha (\text{SINR} - \beta)} PER=e−α(SINR−β)
-
PHY Rate查表
20MHz带宽时,选用不同(MCS, NSS)组合的PHY Rate(单位:Mbps):
| MCS | NSS=1 | NSS=2 |
|---|---|---|
| 0 | 8.6 | 17.2 |
| 1 | 17.2 | 34.4 |
| 2 | 25.8 | 51.6 |
| 3 | 34.4 | 68.8 |
| 4 | 51.6 | 103.2 |
| 5 | 68.8 | 137.6 |
| 6 | 77.4 | 154.9 |
| 7 | 86.0 | 172.1 |
| 8 | 103.2 | 206.5 |
| 9 | 114.7 | 229.4 |
| 10 | 129.0 | 258.1 |
| 11 | 143.4 | 286.8 |
- 帧序列时长
RTS-CTS模式下的帧序列总时长:
T tx = T RTS + SIFS + T CTS + SIFS + T data + SIFS + T ACK T_{\text{tx}} = T_{\text{RTS}} + \text{SIFS} + T_{\text{CTS}} + \text{SIFS} + T_{\text{data}} + \text{SIFS} + T_{\text{ACK}} Ttx=TRTS+SIFS+TCTS+SIFS+Tdata+SIFS+TACK
各部分时长:
省略部分内容
省略部分内容
- 竞争窗口
二进制指数退避算法:
省略部分内容
其中, k k k为重传次数。
- 发送概率
省略部分内容
总结
通过对WLAN系统的深入分析,建立了从输入参数到AP发送机会、PHY层参数、最终系统吞吐量的完整预测模型。利用数学公式和机器学习方法,详细阐述了每个问题的解题思路和步骤。模型充分考虑了节点间RSSI、CCA门限、NAV机制、业务流量类型、SINR、(MCS, NSS)、PER、聚合机制等多种因素,对提高模型的准确性和鲁棒性至关重要。最后,通过CDF曲线评估了模型的精度,为模型的优化和改进提供了参考。
全文请从 底部名片 处获取哦~