加入会员社群,免费获取本项目数据集和代码:点击进入>>
1. 项目简介
A034-Informer模型复现项目实战的目标是通过复现Informer模型,帮助理解其在时间序列预测中的实际应用和效果。该项目基于深度学习模型Informer,这是一种针对长序列时间序列预测而优化的Transformer变种。相较于传统的Transformer模型,Informer通过引入稀疏自注意力机制来显著降低计算复杂度,特别适用于大规模时间序列数据预测场景。项目的主要背景是在大数据和物联网环境下,越来越多的行业依赖精准的时间序列预测来提升运营效率与决策质量。然而,随着数据规模的不断扩大,常规预测模型在处理长时间跨度、多维数据时存在计算瓶颈,Informer的出现正是为了解决这一问题。它不仅在处理速度上具备优势,还可以在准确度上超越其他流行模型,因此适用于诸如电力负荷预测、气象预测、流量预测等场景。本项目通过复现该模型,旨在加深对其架构、算法优化策略及实际应用的理解。
2.技术创新点摘要
稀疏自注意力机制:Informer模型的一个核心创新点是它引入了稀疏自注意力机制(ProbSparse Attention),通过选择性地关注最具信息量的注意力头,显著减少了全局自注意力的计算复杂度。传统Transformer模型在处理长序列数据时,计算复杂度为O(L2)O(L^2)O(L2),而Informer通过引入稀疏性使得复杂度降低到O(LlogL)O(L \log L)O(LlogL),特别适合长时间序列的高效处理。
多尺度卷积堆叠:模型的Encoder部分引入了多尺度的卷积操作,这使得模型可以更好地捕捉不同时间跨度的特征信息,尤其适用于处理长时间序列中的局部和全局信息。
Distillation机制:Informer通过使用Distillation机制进一步优化模型的性能。该机制会逐步蒸馏掉一些冗余信息,以提升模型的计算效率和泛化能力。这不仅减少了计算开销,还能保留最有价值的信息,适合大规模数据的处理。
长序列预测的优化架构:相较于传统的Transformer模型,Informer在结构设计上更加适应长序列时间序列预测场景,使用了更深层次的Encoder-Decoder结构来提升预测的精度和效率。在实际应用中,如电力负载、流量预测等场景,Informer通过减少冗余计算和自注意力机制优化,大大提升了模型的预测能力。
批量处理和多步预测:模型支持大批量数据的并行处理,且能够进行多步预测,显著提高了实际应用中的预测效率。

3. 数据集与预处理
在A034-Informer模型复现项目中,使用的数据集主要来自于典型的时间序列预测任务,如电力负荷预测、天气预报或流量预测等场景。这些数据集的特点是包含长时间跨度、多维度的连续时间数据,通常具有高维度的输入特征和多个目标变量。每个数据点都包含时间戳以及与该时间点相关的多个特征,例如日期、时间、温度、湿度、负载等。
数据预处理流程:
- 缺失值处理:时间序列数据通常会遇到缺失值问题,项目首先会通过插值或填补等技术处理这些缺失数据,确保数据的完整性和一致性。
- 归一化:为了加速模型的训练过程并确保不同特征的取值范围相对一致,项目对所有的输入特征进行了归一化处理。常用的归一化方法是将数据缩放到[0,1][0, 1][0,1]或[−1,1][-1, 1][−1,1]区间,这有助于避免特征值过大导致的梯度爆炸或模型不稳定。
- 数据切分:将数据按照时间顺序划分为训练集、验证集和测试集,确保模型能够在验证和测试阶段评估其泛化能力。时间序列预测通常要遵循时间顺序,避免训练数据泄漏到测试数据中。
- 滑动窗口机制:为了生成模型的输入和目标输出,数据预处理通过滑动窗口机制从时间序列数据中提取特征和标签。具体来说,使用固定长度的窗口提取序列片段作为输入,预测窗口之后的值作为模型的输出。
- 特征工程:除了原始数据特征,还可能会构建额外的时间特征,如小时、周几、月份等。这些特征能够捕捉到周期性规律,提升模型的预测效果。
4. 模型架构
Informer模型架构基于Transformer的改进,专门针对长序列时间序列预测问题进行了优化。它的核心创新在于稀疏自注意力机制(ProbSparse Attention),用于减少计算复杂度,并通过分层处理长序列数据。模型的主要组成部分如下:
- 输入层(Input Layer) :输入的序列特征为长度 LLL,每个时间步的特征维度为 ddd。通过输入嵌入(Embedding)将原始特征映射到一个高维向量空间,公式为:
E = X W e + b e E = XW_e + b_e E=XWe+be
- 其中,X是输入序列,We是嵌入矩阵,be是偏置项。
- 稀疏自注意力层(ProbSparse Attention Layer) :该层的稀疏性在于,只计算对预测最为重要的注意力权重,显著减少了传统Transformer中的 O(L2) 计算复杂度,公式为:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
- 其中,QQQ, KKK, VVV 分别是查询(Query)、键(Key)、值(Value)矩阵。Informer只保留对 QQQ 最重要的 KKK 项,大大降低了复杂度。
- 多尺度卷积层(Multi-scale Convolution Layer) :在Encoder中,使用多尺度卷积来提取不同时间尺度的特征,有助于捕捉局部和全局模式。
- 蒸馏机制(Distillation Layer) :通过层层蒸馏,减少冗余信息,保留核心特征,进一步提升模型的效率,公式为:
X ~ = D ( X ) \tilde{X} = D(X) X~=D(X)
- 其中,D(X)表示将输入 X通过蒸馏层的处理,减少序列长度。
- 解码器(Decoder) :与Transformer类似,由堆叠的多头注意力机制组成,用于逐步生成预测结果。通过使用前一步的输出作为下一步的输入,实现序列到序列的预测。
2) 模型的整体训练流程与评估指标
训练流程:
- 数据输入:模型接收经过预处理的时间序列数据,输入序列通过嵌入层和蒸馏层处理后,进入Encoder。
- 前向传播:稀疏自注意力机制用于计算输入序列中的重要依赖关系,多尺度卷积层提取多时间尺度的特征。
- 误差计算:通过解码器输出预测值后,计算与实际值之间的误差,常用的损失函数为均方误差(MSE),公式为: L o s s = 1 n ∑ i = 1 n ( y i − y i ^ ) 2 Loss = \frac{1}{n} \sum_{i=1}^{n}(y_i - \hat{y_i})^2 Loss=n1i=1∑n(yi−yi^)2
其中,yi为真实值,yi^ 为预测值。
评估指标:
- 均方误差(MSE) :衡量预测值与真实值之间的平均平方差。
- 平均绝对百分比误差(MAPE) :评估预测结果的相对误差,公式为: M A P E = 1 n ∑ i = 1 n ∣ y i − y i ^ y i ∣ MAPE = \frac{1}{n} \sum_{i=1}^{n} \left| \frac{y_i - \hat{y_i}}{y_i} \right| MAPE=n1i=1∑n yiyi−yi^
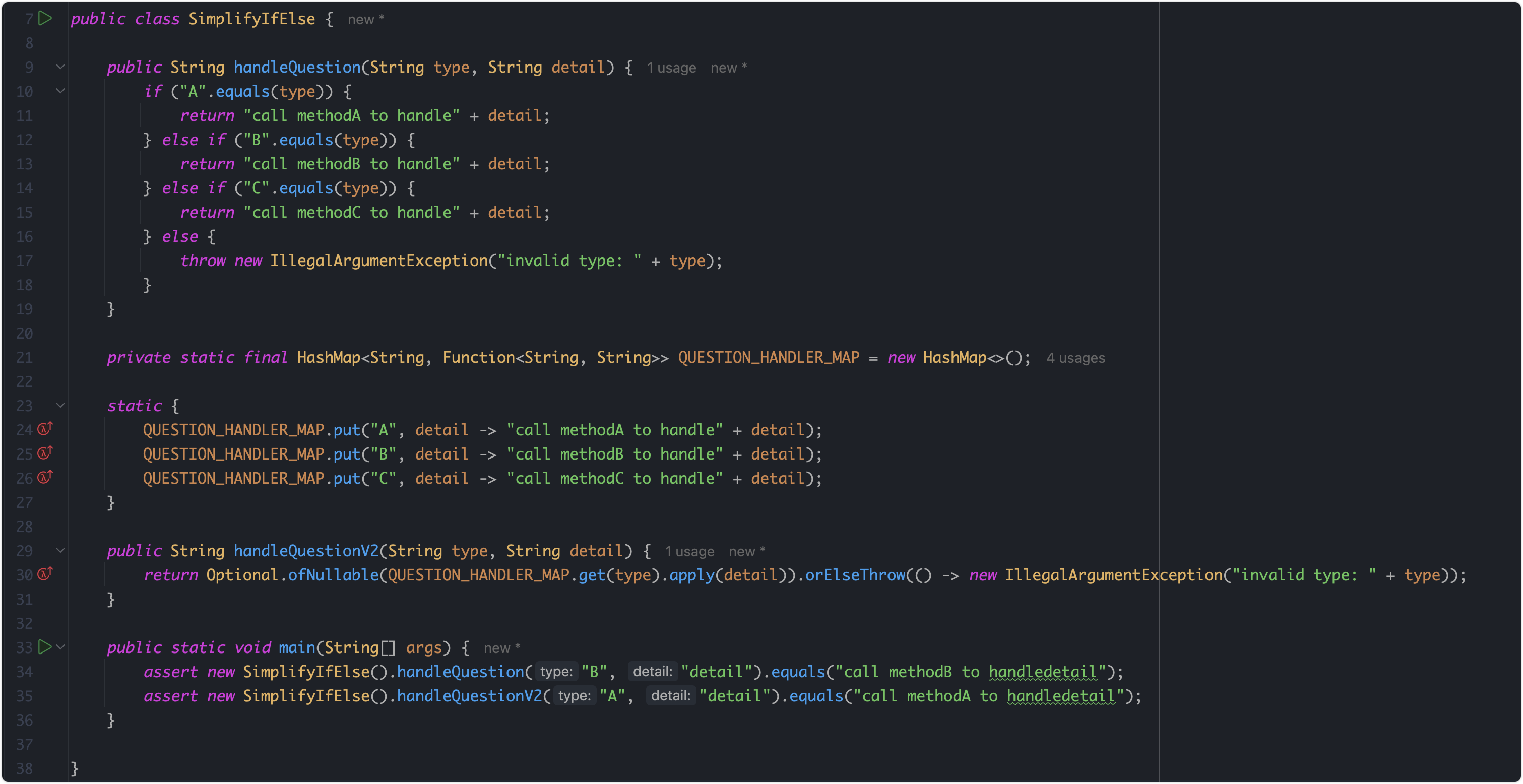
5. 核心代码详细讲解
1. 数据预处理
在代码中,数据的预处理主要通过命令行参数的方式进行配置,核心在于定义如何将时间序列数据转换为模型可接受的输入。
核心代码解释:
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length')
parser.add_argument('--label_len', type=int, default=48, help='start token length')
parser.add_argument('--pred_len', type=int, default=24, help='prediction sequence length')
这段代码定义了模型的输入序列长度 seq_len(即用于预测的历史时间步数),标签序列长度 label_len,以及模型需要预测的未来时间步数 pred_len。这三个参数控制了输入数据的切割方式。
2. 模型架构构建
Informer的核心架构是基于稀疏自注意力机制(ProbSparse Attention)和分层的编码器-解码器结构。
核心代码解释:
class ProbSparseAttention(nn.Module):def init(self, factor, scale=None):super(ProbSparseAttention, self).
__init__
()self.factor = factorself.scale = scale
这里定义了稀疏自注意力机制类 ProbSparseAttention,其中 factor 是一个稀疏因子,用于控制注意力矩阵的计算效率。该机制通过选择性地计算最重要的注意力权重,从而降低复杂度。
def forward(self, queries, keys, values):score = torch.matmul(queries, keys.transpose(-1, -2)) / self.scaleattention = torch.softmax(score, dim=-1)out = torch.matmul(attention, values)return out
这段代码实现了稀疏注意力的前向传播。首先,queries 和 keys 通过矩阵乘法计算相似度得分 score,然后通过 softmax 函数归一化,得到最终的注意力权重。接着,权重与 values 相乘以输出注意力结果。
3. 模型训练与评估
Informer模型的训练过程使用的是经典的深度学习训练流程,包括前向传播、计算损失、反向传播和优化。
核心代码解释:
exp = Exp(args)
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
这里实例化了 Exp 类,该类封装了整个模型的训练和测试过程,调用了 train 函数开始模型的训练。setting 参数配置了所有的训练超参数。
loss = criterion(preds, trues)
loss.backward()
optimizer.step()
这段代码是模型的训练核心,通过计算损失 loss,使用反向传播算法 loss.backward() 更新模型参数,optimizer.step() 执行梯度下降
6. 模型优缺点评价
模型优点:
- 稀疏自注意力机制(ProbSparse Attention) :Informer通过稀疏自注意力机制,显著降低了计算复杂度,将传统Transformer的O(L2)O(L^2)O(L2)复杂度减少到O(LlogL)O(L \log L)O(LlogL),使其更加适合处理长时间序列数据。
- 多尺度特征提取:通过多尺度卷积模块,模型能够同时捕捉长短期特征,提升了在长序列预测中的效果。
- 蒸馏机制:模型采用了蒸馏机制,减少了冗余信息,保留了最具代表性的特征,提高了模型的计算效率和泛化能力。
- 高效处理长序列数据:相比传统的Transformer模型,Informer更适合长序列预测任务,尤其是在诸如电力负荷预测、气象预测等场景中表现优异。
模型缺点:
- 局限于特定任务:虽然Informer在长时间序列预测上表现优异,但其针对性的架构和稀疏性设计可能不适合短序列或非时间序列任务。
- 模型复杂性:虽然稀疏注意力降低了部分计算复杂度,但整体模型结构仍然较复杂,训练过程中的调参成本较高。
- 依赖大量数据:如同其他深度学习模型,Informer在小数据集上可能会出现过拟合或性能不稳定的问题,尤其是在缺乏多样性的数据集上。
可能的模型改进方向:
- 超参数优化:通过进一步优化超参数,如稀疏因子、注意力头数等,可能会进一步提升模型的性能。
- 引入更多的数据增强方法:对于数据较少的场景,可以考虑引入时间序列数据增强技术,如时间步采样、噪声添加等,以提高模型的泛化能力。
- 模型结构优化:可以引入轻量化模型或混合模型,将Informer与其他神经网络(如LSTM、GRU)结合,以提高对短期依赖问题的处理能力。
↓↓↓更多热门推荐:
GAN模型实现二次元头像生成
CNN模型实现mnist手写数字识别
点赞收藏关注,免费获取本项目代码和数据集,点下方名片↓↓↓