# [嵌入模型 · Ollama 博客 - Ollama 中文](https://ollama.org.cn/blog/embedding-models)# 步骤1:生成嵌入import ollama
import chromadbdocuments =["Llamas are members of the camelid family meaning they're pretty closely related to vicuñas and camels","Llamas were first domesticated and used as pack animals 4,000 to 5,000 years ago in the Peruvian highlands","Llamas can grow as much as 6 feet tall though the average llama between 5 feet 6 inches and 5 feet 9 inches tall","Llamas weigh between 280 and 450 pounds and can carry 25 to 30 percent of their body weight","Llamas are vegetarians and have very efficient digestive systems","Llamas live to be about 20 years old, though some only live for 15 years and others live to be 30 years old",]client = chromadb.Client()
collection = client.create_collection(name="docs")# store each document in a vector embedding databasefor i, d inenumerate(documents):response = ollama.embeddings(model="mxbai-embed-large", prompt=d)embedding = response["embedding"]collection.add(ids=[str(i)],embeddings=[embedding],documents=[d])# 步骤2:检索# an example prompt
prompt ="What animals are llamas related to?"# generate an embedding for the prompt and retrieve the most relevant doc
response = ollama.embeddings(prompt=prompt,model="mxbai-embed-large")
results = collection.query(query_embeddings=[response["embedding"]],n_results=1)
data = results['documents'][0][0]# 步骤3:生成# generate a response combining the prompt and data we retrieved in step 2
output = ollama.generate(model="qwen2:7b",prompt=f"Using this data: {data}. Respond to this prompt: {prompt}")print(output['response'])
直接参考【正点原子】I.MX6U嵌入式Linux驱动开发指南V1.81 本文仅作为个人笔记使用,方便进一步记录自己的实践总结。 前两章我们简单了解了一下 Linux 内核顶层 Makefile 和 Linux 内核的启动流程,本章我们就来学习一下如何将 NXP官方提供的 Linux 内核移…
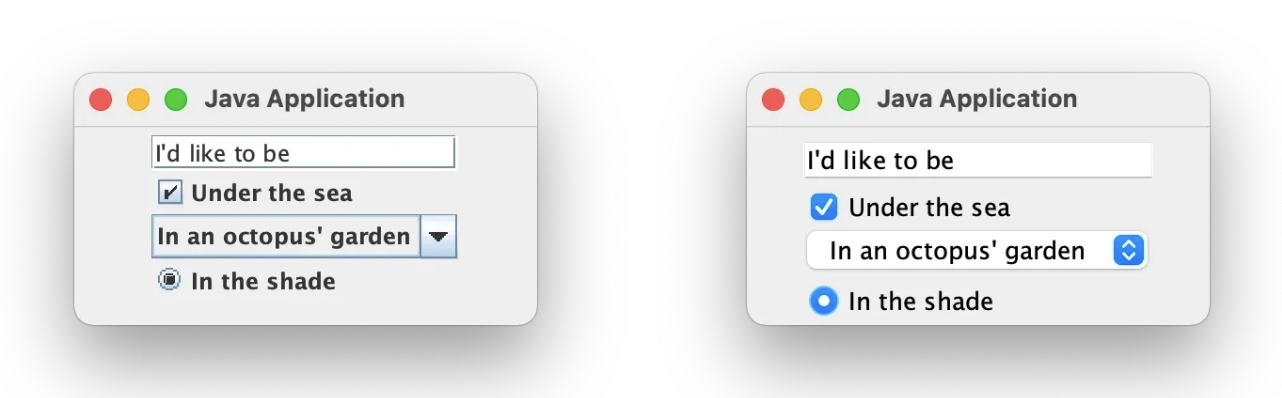
在 Java 中编写桌面应用程序时,我们总是希望其外观和感觉能够尽量贴近原生应用程序。因为一个优秀的应用程序应该要能融入其中,为用户提供已经熟悉的体验。 Swing GUI 的外观和感觉: Metal vs. Native
在桌面上,用户的使用旅程并不是从应用程…