目录
- 一、项目简介
- 概述
- 时间
- 主要工作和收获
- 技术栈
- 数据集
- 结果
- 参考
- 二、训练阶段的完整代码
- 什么是 QLoRA 微调?
- 注意
- 安装库
- 导入包
- 配置
- 定义一个Config类
- 配置训练参数
- 配置Lora
- 初始化分词器和模型
- 数据预处理
- 计算模型评估指标
- 交叉验证划分数据集
- 举例:
- 创建Trainer,开始训练
- 三、推理阶段的完整代码
- 安装库
- 导入包
- 配置
- 加载和预处理数据
- 注意事项:
- 分词
- 加载模型
- 加载 LoRA 适配器
- 推理
- 四、背景知识补充
- 为什么LoRA只针对自注意力投影层进行微调?
- QLoRA(Quantized Low-Rank Adaptation)
- QLoRA 的核心思想:
- QLoRA 的优势:
- QLoRA 的典型工作流程:
- QLoRA 的应用场景:
- 混合精度训练(Mixed Precision Training)
- 混合精度训练的基本概念:
- 混合精度训练的优势:
- 如何实现混合精度训练:
- 工作机制:
- 适用场景:
- 总结:
- 梯度溢出(Gradient Overflow)
- 为什么会发生梯度溢出?
- 梯度溢出的影响
- 解决梯度溢出的常见方法
- 总结:
- TTA(Test Time Augmentation)
- 工作原理:
- TTA 在不同任务中的应用:
- TTA 的优点:
- TTA 的缺点:
- 总结:
一、项目简介
概述
本项目使用QLoRA技术(即结合了量化 和 LoRA 技术),旨在在资源有限的情况下对预训练大模型进行高效微调,如移动设备或嵌入式设备,并将微调后的模型用在了一个文本分类任务的推理上。包含了完整的训练和推理过程。
时间
2024.09.18-2024.09.19
主要工作和收获
- 使用 QLoRA 技术在资源有限的情况下对大规模预训练模型进行高效微调
- 使用了多GPU并行推理技术
- 使用了交差验证
- 使用了TTA(测试时增强)技术,提升模型在测试阶段的泛化能力,进一步提高推理结果的鲁棒性
- 做了一个文本分类任务的推理
技术栈
Gemma 2,QLoRA微调,混合精度训练,TTA(测试时增强),多GPU并行推理,交叉验证
数据集
lmsys-chatbot-arena
结果
我没有参加下面这个比赛,只是学习目的,下面是原作者的参赛结果,供参考
比赛地址:LMSYS - Chatbot Arena Human Preference Predictions
比赛简介和推理任务:
我们使用了从 Chatbot Arena 收集的大型数据集,用户在该平台与两个匿名 LLM 进行对话,并选择他们更喜欢的回答。在这次竞赛中,你的任务是预测用户在这些对决中更倾向于哪个回应。
原作者提交后的结果如下:效果非常好,击败了之前所有人的提交结果(0.98-1)
| 子集 | 对数损失 |
|---|---|
| 评估集 | 0.9371 |
| LB | 0.941 |
参考
[Training] Gemma-2 9b 4-bit QLoRA fine-tuning
[Inference] Gemma-2 9b 4-bit QLoRA
二、训练阶段的完整代码
kaggle地址:[Training] Gemma-2 9b 4-bit QLoRA fine-tuning
什么是 QLoRA 微调?
在传统的微调中,权重 ( W \mathbf{W} W) 按如下方式更新:
W ← W − η ∂ L ∂ W = W + Δ W \mathbf{W} \leftarrow \mathbf{W} - \eta \frac{{\partial L}}{{\partial \mathbf{W}}} = \mathbf{W} + \Delta \mathbf{W} W←W−η∂W∂L=W+ΔW
其中 L L L 是当前步骤的损失, η \eta η 是学习率。
LoRA 尝试通过将 Δ W ∈ R d × k \Delta \mathbf{W} \in \mathbb{R}^{\text{d} \times \text{k}} ΔW∈Rd×k 因式分解为两个更小的矩阵 B ∈ R d × r \mathbf{B} \in \mathbb{R}^{\text{d} \times \text{r}} B∈Rd×r 和 A ∈ R r × k \mathbf{A} \in \mathbb{R}^{\text{r} \times \text{k}} A∈Rr×k 来近似 Δ W \Delta \mathbf{W} ΔW,其中 r ≪ min ( d , k ) r \ll \text{min}(\text{d}, \text{k}) r≪min(d,k)。
Δ W s ≈ B A \Delta \mathbf{W}_{s} \approx \mathbf{B} \mathbf{A} ΔWs≈BA
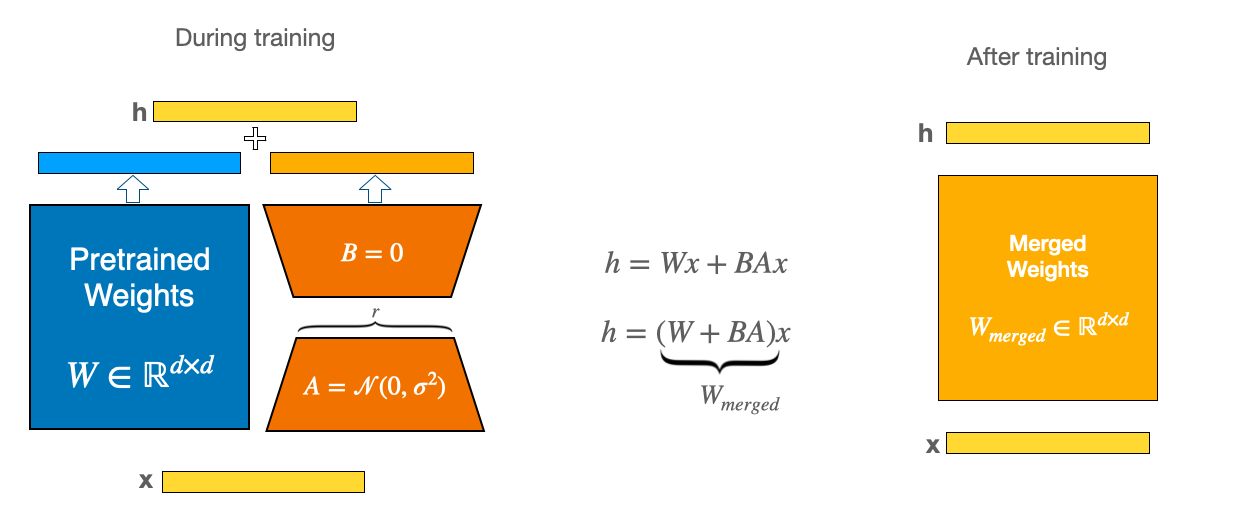
图片来源:https://img-blog.csdnimg.cn/img_convert/51b5e42ed5e9fd61448a48478d3eee6e.png
在训练过程中,只有 A \mathbf{A} A 和 B \mathbf{B} B 被更新,而原始权重保持冻结状态,这意味着在训练过程中只需更新一小部分(例如 <1%)原始权重。这样,在训练时可以显著减少 GPU 内存的使用,同时实现与常规(完整)微调相当的性能。
QLoRA 通过对 LLM 进行量化进一步提高了效率。例如,具有 80 亿参数的模型在 32-bit 下单独占用 32GB 的显存,而量化到 8-bit/4-bit 的 80 亿参数模型仅需分别占用 8GB/4GB 的显存。请注意,QLoRA 仅对 LLM 的权重进行低精度量化(例如 8-bit),而前向/反向计算在更高精度(例如 16-bit)下进行,LoRA 适配器的权重也保持更高精度。
注意
在 Kaggle 的内核上运行完整训练所需的时间过长,建议使用外部计算资源来进行完整训练。此项目仅使用 100 个样本用于演示。
安装库
-
"transformers>=4.42.3":transformers:这是Hugging Face的库,主要用于加载和操作预训练的Transformer模型(例如BERT、GPT、T5等)。它提供了各种用于NLP任务的模型和工具。- gemma-2 可在 transformers>=4.42.3 中使用
-
bitsandbytes:bitsandbytes是一个高效的库,用于在GPU上进行低精度(如8-bit)训练和推理。它允许通过更少的内存占用来加速大规模模型的训练和推理,特别是对于大型Transformer模型(例如GPT类模型)。- 安装此库的目的通常是为了在有限的GPU资源下运行大模型,并且仍然保持较高的性能。
-
accelerate:accelerate是Hugging Face提供的一个库,用于简化多GPU、多TPU分布式训练。它帮助用户轻松配置和运行复杂的并行化训练,特别是在需要跨多个设备进行计算时。- 安装这个库的目的是为了提高训练效率,尤其是当处理大规模数据或大模型时,它能显著减少训练时间。
-
peft:peft(Parameter-Efficient Fine-Tuning)是用于参数高效微调的库。它提供了轻量化微调大型语言模型的方法,如LoRA(Low-Rank Adaptation),使得在有限资源的情况下也能对大型模型进行微调。- 安装这个库通常用于在对大模型进行定制训练时,减少微调所需的资源消耗。
这些库共同作用,使得用户能够在有限的资源下,高效地训练、微调和部署大型Transformer模型。
!pip install -U "transformers>=4.42.3" bitsandbytes accelerate peft
导入包
import os
import copy # 提供深拷贝功能,用于在创建对象副本时避免对原对象的修改。
from dataclasses import dataclass # 用于简化类的定义,尤其是在需要存储数据的场景。import numpy as np
import torch
from datasets import Dataset
from transformers import (BitsAndBytesConfig, # 这是用来配置低精度计算的(如8-bit训练)。Gemma2ForSequenceClassification, # Gemma2的预训练模型,用于文本分类任务。GemmaTokenizerFast, # 快速分词器,支持高效地处理文本输入,将文本转换为模型可以理解的token序列。Gemma2Config, # 配置类,用于设置Gemma2模型的架构和超参数(如层数、隐藏层维度等)。PreTrainedTokenizerBase, # Hugging Face中所有预训练分词器的基类,定义了分词器的基本操作。EvalPrediction, # 在评估模型时使用的类,包含预测值和标签,用于计算评估指标。Trainer, # Hugging Face用于简化模型训练和评估的高阶API,集成了训练、评估、预测等功能。TrainingArguments, # 用于配置训练过程的参数(如学习率、批量大小、训练epoch等)。DataCollatorWithPadding, # 一个数据整理器,用于自动为批处理的数据填充padding,以使每个batch中的样本长度一致,方便进行并行计算。
)
'''
LoraConfig:用于配置LoRA(Low-Rank Adaptation),一种参数高效微调方法。它通过减少要调整的参数数量,允许在资源有限的情况下微调大型模型。
get_peft_model:根据LoRA配置,获取微调后的模型。
prepare_model_for_kbit_training:准备模型以进行低精度训练,例如8-bit或4-bit训练,进一步节省显存和计算资源。
TaskType:用于指定任务类型(如文本分类、生成等)。
'''
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training, TaskType
from sklearn.metrics import log_loss, accuracy_score
配置
定义一个Config类
方便存储与微调Gemma模型相关的超参数。
@dataclass
class Config:output_dir: str = "output" # 模型输出目录checkpoint: str = "unsloth/gemma-2-9b-it-bnb-4bit" # 指定预训练模型的检查点路径。这里使用Gemma模型的4-bit量化版本max_length: int = 1024 # 输入序列的最大长度n_splits: int = 5 # 交叉验证的折数fold_idx: int = 0 # 当前的折索引,第0折,即第1个子集作为验证集,剩余4个子集作为训练集。optim_type: str = "adamw_8bit" # 使用8-bit的AdamW优化器,节省显存per_device_train_batch_size: int = 2 # 每个设备的训练批量大小gradient_accumulation_steps: int = 2 # 梯度累积步数,表示梯度会在2个步骤后累积更新。这实际上把全局的批量大小增加到 2 * 2 = 4,有助于在小显存环境下进行更大批量的训练。per_device_eval_batch_size: int = 8 # 每个设备上的评估批量大小设置为8,用于验证模型的性能。在验证过程中,每个设备同时处理8个样本。n_epochs: int = 1 # 训练的总epoch数量freeze_layers: int = 16 # 冻结前16层,只微调后面的层lr: float = 2e-4 # 学习率warmup_steps: int = 20 # 预热步骤数,在训练的前20步中,学习率会从低到高逐渐增加,以防止训练开始时模型参数更新过快。lora_r: int = 16 # LoRA的秩,值越小,训练时的参数量越少,占用显存越少,计算量也越小lora_alpha: float = lora_r * 2 # LoRA的缩放因子,用来控制学习到的低秩适配器(adapter)的权重更新幅度。它通常是r的2倍lora_dropout: float = 0.05 # LoRA的dropout率lora_bias: str = "none" # 表示LoRA不会修改偏置项,通常只对投影矩阵进行调整。config = Config()
配置训练参数
配置语言模型训练的细节,包括输出设置、训练轮数、批次大小、梯度累积、优化器类型、混合精度等。所有这些参数为后续使用Hugging Face的Trainer类进行训练提供了基本配置。
training_args = TrainingArguments(output_dir="output",overwrite_output_dir=True, # 允许覆盖现有的输出目录。如果已经有内容存在,它们将会被新的训练结果覆盖。这对于反复实验或重新训练同一模型时很有用。report_to="none", # 禁用日志报告功能。这意味着不会将训练过程中的日志发送到外部工具或平台(如TensorBoard、WandB等)。num_train_epochs=config.n_epochs,per_device_train_batch_size=config.per_device_train_batch_size,gradient_accumulation_steps=config.gradient_accumulation_steps,per_device_eval_batch_size=config.per_device_eval_batch_size,logging_steps=10, # 每10个训练步打印一次日志。它控制训练过程中输出日志的频率,便于观察训练过程中的一些关键指标(如损失值)。eval_strategy="epoch", # 设置评估策略为epoch,即在每个epoch结束后对验证集进行评估来检查模型的表现。save_strategy="steps", # 模型保存的策略。设置为steps,表示按步数间隔进行保存,而不是按epoch保存。save_steps=200, # 每200步保存一次模型optim=config.optim_type,fp16=True, # 启用16-bit浮点数精度训练(即混合精度训练)。这有助于减少模型在训练时的显存占用,并加速计算,同时保持数值稳定性。learning_rate=config.lr,warmup_steps=config.warmup_steps,
)
配置Lora
通过LoraConfig配置了LoRA的参数和应用范围,主要针对模型中的自注意力投影层,并选择性地对模型的深层进行微调(冻结前16层)。这种配置能够有效减少训练开销,使得在资源受限的环境下,也可以进行大模型的微调。
lora_config = LoraConfig(r=config.lora_r,lora_alpha=config.lora_alpha,# 这是LoRA微调的目标模块。在Transformer模型中,自注意力机制的核心操作包括查询(`q_proj`)、键(`k_proj`)、和值(`v_proj`)的投影,这些模块在计算注意力分数时至关重要。# 通过指定只在这些模块应用LoRA,减少了要调整的参数数量,同时仍能有效影响模型的表现。target_modules=["q_proj", "k_proj", "v_proj"],# 决定哪些层将应用LoRA调整,将LoRA应用于从第16层到第42层的部分,忽略前16层。这种做法减少了计算开销,同时保留对深层特征的调整能力。layers_to_transform=[i for i in range(42) if i >= config.freeze_layers],lora_dropout=config.lora_dropout,bias=config.lora_bias, # 表示这是一项序列分类任务(sequence classification)。LoRA可以适应不同任务类型,这里通过指定任务类型,确保LoRA配置与任务相匹配。task_type=TaskType.SEQ_CLS,
)
初始化分词器和模型
# 加载预训练分词器
tokenizer = GemmaTokenizerFast.from_pretrained(config.checkpoint) # 每个输入文本的末尾将自动添加一个<eos>(End of Sequence,序列结束符)标记。
# "<eos>"标记用于告诉模型该序列已经结束,在处理生成任务或分类任务时尤其重要,因为它明确了文本的结束,避免模型无穷生成。
tokenizer.add_eos_token = True # 在NLP任务中,模型输入通常需要统一的长度,如果某些句子较短,需要在句子中添加填充符号(<pad>)来补齐。
# 填充方式对模型的训练和推理有一定影响,有时不同任务中使用不同的填充策略(右侧填充或左侧填充),根据模型的需求和训练方法进行调整。
tokenizer.padding_side = "right"
model = Gemma2ForSequenceClassification.from_pretrained(config.checkpoint,num_labels=3, # 指定分类任务中有3个标签。这告诉模型我们正在处理一个三类分类问题(如情感分类中有三种情感:正面、中性、负面)。torch_dtype=torch.float16, # 指定模型使用16-bit浮点数(FP16)进行计算,通常用于混合精度训练,以减少显存占用和加速计算。device_map="auto", # 自动将模型分配到可用的硬件设备(如GPU或CPU)。如果有多个GPU,模型的不同部分可能会被分配到不同的设备,以优化资源利用。
)# 禁用缓存机制
# 在模型推理或生成时,通常会启用缓存机制以加速推理。
# 然而,在某些情况下(如进行梯度反向传播训练时),使用缓存可能会导致显存不够,因此这里将缓存禁用。
# 对于分类任务,禁用缓存不会影响模型的训练性能,但可以避免显存溢出。
model.config.use_cache = False# 这是PEFT(Parameter-Efficient Fine-Tuning)库中的一个函数,用于将模型准备为低比特训练模式(如8-bit或4-bit训练)。
# 大幅度减少内存使用,特别适用于大模型的微调
model = prepare_model_for_kbit_training(model)# 使用LoRA对模型进行参数高效微调(PEFT)
model = get_peft_model(model, lora_config)
model
model.print_trainable_parameters()
数据预处理
ds = Dataset.from_csv("/kaggle/input/lmsys-chatbot-arena/train.csv")
ds = ds.select(torch.arange(100)) # 只使用前100个数据进行演示
- 这个
CustomTokenizer类用于从批量数据中提取提示和模型生成的响应,并将它们格式化、标记化。 - 它为两个模型的生成结果(
response_a和response_b)进行对比,并根据哪个模型表现更好来生成分类标签。 - 最终,生成的token和标签可以用于训练或评估NLP模型,特别是分类任务(如模型选择或对话生成质量评估)。
class CustomTokenizer:def __init__(self, tokenizer: PreTrainedTokenizerBase, max_length: int # 这是标记化过程中允许的最大序列长度,超过此长度的序列将被截断。) -> None:self.tokenizer = tokenizerself.max_length = max_lengthdef __call__(self, batch: dict) -> dict:'''处理和标记化文本每个输入样本有三个字段:prompt:表示输入的提示,前缀为"<prompt>:"。response_a 和 response_b:分别表示两个模型生成的响应,前缀为"<response_a>:"和"<response_b>:"。'''prompt = ["<prompt>: " + self.process_text(t) for t in batch["prompt"]]response_a = ["\n\n<response_a>: " + self.process_text(t) for t in batch["response_a"]]response_b = ["\n\n<response_b>: " + self.process_text(t) for t in batch["response_b"]]# 将 prompt, response_a 和 response_b 拼接成一个字符串texts = [p + r_a + r_b for p, r_a, r_b in zip(prompt, response_a, response_b)]# 使用预训练的分词器将处理后的文本进行标记化,生成模型所需的输入形式。标记化结果会被截断到 max_length。tokenized = self.tokenizer(texts, max_length=self.max_length, truncation=True)'''生成标签根据 winner_model_a 和 winner_model_b 的值,生成对应的分类标签。0:winner_model_a 赢。1:winner_model_b 赢。2:没有明确的赢家。这些标签将作为模型的训练目标(如分类模型中的类别标签)。'''labels=[]for a_win, b_win in zip(batch["winner_model_a"], batch["winner_model_b"]):if a_win:label = 0elif b_win:label = 1else:label = 2labels.append(label)# 最终返回标记化后的文本(tokenized)以及相应的标签(labels)。这些返回值将作为模型的输入和训练时的目标。return {**tokenized, "labels": labels}@staticmethoddef process_text(text: str) -> str:return " ".join(eval(text, {"null": ""}))
encode = CustomTokenizer(tokenizer, max_length=config.max_length)# 对整个数据集 ds 中的所有样本进行批量处理,使用 encode 这个 CustomTokenizer 实例对每个样本进行处理。
# 处理后的数据集将包含新的字段,通常包括分词后的 input_ids、attention_mask 以及 labels。
ds = ds.map(encode, batched=True)
计算模型评估指标
该函数用于 Hugging Face Trainer 类的 compute_metrics 回调中。当评估模型时,Trainer 会自动调用这个函数,计算准确率和对数损失,并将这些指标用于模型评估或展示。
# 输入参数 eval_preds 是 Hugging Face transformers 库中的 EvalPrediction 对象,它包含了模型在评估集上的预测结果和真实标签。
def compute_metrics(eval_preds: EvalPrediction) -> dict:# 从评估预测中获取模型的预测 logits 和真实标签。preds = eval_preds.predictions # 这是模型的预测输出,通常是 logits(未经过 softmax 的输出)。这些 logits 代表了模型对每个类别的信心分数。labels = eval_preds.label_ids # 这是模型的真实标签,即 label_ids。它是评估集中的实际分类标签。# 通过 softmax 将 logits 转换为概率分布probs = torch.from_numpy(preds).float().softmax(-1).numpy()# 计算对数损失,对数损失是一个用于分类任务的损失函数,衡量预测概率与真实标签之间的差异,预测的概率越接近真实标签,损失越小。loss = log_loss(y_true=labels, y_pred=probs)# 通过 argmax 计算预测的类别,并基于此计算准确率。准确率是指模型预测正确的样本比例。acc = accuracy_score(y_true=labels, y_pred=preds.argmax(-1))return {"acc": acc, "log_loss": loss}
交叉验证划分数据集
这段代码通过交叉验证的方式,将数据集 ds 划分为训练集和验证集的不同折(folds)。它使用了 config.n_splits(交叉验证的折数)将数据集按照折数进行分块,并创建了一个包含训练集和验证集索引的列表。
# folds 是一个列表,包含 n_splits 个这样的元组,每个元组都对应一个交叉验证折的训练集和验证集。
folds = [# 每个折是一个元组,元组的第一个元素是训练集的索引,第二个元素是验证集的索引。(# 这部分生成的是训练集的索引,表示在当前折中那些没有被分配到验证集的样本。[i for i in range(len(ds)) if i % config.n_splits != fold_idx],# 这部分生成的是验证集的索引,表示当前折所使用的验证样本。[i for i in range(len(ds)) if i % config.n_splits == fold_idx]) for fold_idx in range(config.n_splits)
]
举例:
假设 len(ds) = 10 且 config.n_splits = 5,那么数据集有 10 个样本,进行 5 折交叉验证。结果生成的 folds 可能类似如下:
folds = [([1, 2, 3, 4, 6, 7, 8, 9], # 训练集索引,排除余数为0的样本(如样本0和样本5)[0, 5] # 验证集索引),([0, 2, 3, 4, 5, 7, 8, 9], # 训练集索引,排除余数为1的样本[1, 6] # 验证集索引),# 后续折...
]
创建Trainer,开始训练
# 选择数据:通过交叉验证的 folds,为当前 fold_idx 获取训练集和验证集的索引,并从数据集中选择对应的样本。
train_idx, eval_idx = folds[config.fold_idx] # Trainer 是 Hugging Face transformers 库中的一个高级 API,用于简化模型训练和评估过程
trainer = Trainer(args=training_args, model=model,tokenizer=tokenizer,train_dataset=ds.select(train_idx),eval_dataset=ds.select(eval_idx),compute_metrics=compute_metrics,# 对数据进行自动填充(padding),使得批次内的每个样本长度一致,以便并行计算。data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
)# 训练过程:调用 train() 方法后,模型开始训练。
# 训练过程中,Trainer 会自动计算梯度、更新模型权重、记录日志、并根据配置的频率进行评估。
# 模型在每个训练周期结束时使用验证集评估性能,通过传入的 compute_metrics 函数计算诸如准确率、对数损失等指标。
trainer.train()
三、推理阶段的完整代码
kaggle地址:[Inference] Gemma-2 9b 4-bit QLoRA
安装库
和推理部分的库相同,不过这里通过本地路径安装并升级这些库,而不是从 PyPI 下载。这种方式有助于加速安装,尤其是在 Kaggle 比赛或实验中,安装一些较大的包时,可以通过本地预先上传的 .whl 文件快速完成。
--no-index:表示要从本地文件或指定的路径中查找包,而不是从网络上的 PyPI 获取。--find-links:告诉pip查找要安装的包时,使用指定的本地路径或文件。/kaggle/input/lmsys-wheel-files:这是一个包含已经编译好的wheel文件的目录。
!pip install transformers peft accelerate bitsandbytes \-U --no-index --find-links /kaggle/input/lmsys-wheel-files
导入包
import time
from dataclasses import dataclass
from concurrent.futures import ThreadPoolExecutorimport torch
import sklearn
import numpy as np
import pandas as pd
from transformers import Gemma2ForSequenceClassification, GemmaTokenizerFast, BitsAndBytesConfig
from transformers.data.data_collator import pad_without_fast_tokenizer_warning
from peft import PeftModel
确保代码运行时有两个 GPU 可用,否则就中断运行并报错
assert torch.cuda.device_count() == 2
配置
该配置将用于加载 Gemma 模型和 LoRA 微调后的模型,并控制模型的输入处理方式,适应不同的推理场景
@dataclass
class Config:# 指定 Gemma 模型的目录路径。该路径是模型文件的存储位置,通常在加载预训练模型时使用。gemma_dir = '/kaggle/input/gemma-2/transformers/gemma-2-9b-it-4bit/1/gemma-2-9b-it-4bit'# 指定 LoRA 微调后的模型权重路径。这是已经经过 LoRA 微调后的模型检查点的存储位置。lora_dir = '/kaggle/input/73zap2gx/checkpoint-5748'max_length = 2048 # 指定输入文本的最大长度,超过该值,将进行截断。batch_size = 4 # 推理时处理的样本批量大小。device = torch.device("cuda") # 使用 CUDA 设备(GPU)进行模型计算。# 控制是否启用测试时增强(Test Time Augmentation, TTA)。# 当启用 TTA 时,可能会交换模型生成的不同响应或对其进行组合,以增强推理的效果。# 例如,`<prompt>` 后跟随 `<model-b's response>` 和 `<model-a's response>` 进行推理,以增强模型在推理时的泛化能力。tta = False # 控制如何应用 max_length 参数。# 如果为 True,将把 max_length 平均分配到每个输入段(例如,prompt 和响应),即每个部分的最大长度为 max_length//3。# 如果为 False,则对整个拼接后的输入应用 max_length,即所有文本组合起来后长度不得超过 max_length。spread_max_length = False cfg = Config()
加载和预处理数据
test = pd.read_csv('/kaggle/input/lmsys-chatbot-arena/test.csv')
对 test 数据集中的 prompt、response_a 和 response_b 进行文本预处理,使用 process_text 函数解析文本中的 null 值,并返回处理后的纯文本数据。处理后的数据会展示前3行,用于验证预处理是否正确。
注意事项:
-
使用
eval解析字符串时需要特别小心,因为它会执行传入的表达式。如果数据来源不受信任,可能会带来安全风险。为了安全性,可以考虑使用ast.literal_eval来解析安全的表达式,而不是直接用eval。例如:
import ast def process_text(text: str) -> str:return " ".join(ast.literal_eval(text))
# 清理带有 null 值的 JSON-like 数据,将其转化为普通字符串。
def process_text(text: str) -> str:return " ".join(eval(text, {"null": ""}))# loc 是 Pandas 中用于选取行或列的方式,这里选择的是整个 prompt 列,并将其重新赋值为处理后的结果。
test.loc[:, 'prompt'] = test['prompt'].apply(process_text)
test.loc[:, 'response_a'] = test['response_a'].apply(process_text)
test.loc[:, 'response_b'] = test['response_b'].apply(process_text)display(test.head(3))
展示结果如下:

分词
定义一个名为 tokenize 的函数,用于将输入的 prompt(提示)、response_a(模型 A 的响应)和 response_b(模型 B 的响应)进行分词,并生成用于 NLP 模型的 input_ids 和 attention_mask。函数的设计允许选择性地使用 spread_max_length 选项,以不同方式处理和截断文本长度。
def tokenize(tokenizer, prompt, response_a, response_b, max_length=cfg.max_length, spread_max_length=cfg.spread_max_length
):# 为每个 prompt、response_a 和 response_b 添加对应的标记,明确表明这些文本的来源,让模型能够识别每部分的含义。prompt = ["<prompt>: " + p for p in prompt]response_a = ["\n\n<response_a>: " + r_a for r_a in response_a]response_b = ["\n\n<response_b>: " + r_b for r_b in response_b]if spread_max_length:# 每个 prompt、response_a 和 response_b 将分别分配最大长度的三分之一,即 max_length//3。prompt = tokenizer(prompt, max_length=max_length//3, truncation=True, padding=False).input_idsresponse_a = tokenizer(response_a, max_length=max_length//3, truncation=True, padding=False).input_idsresponse_b = tokenizer(response_b, max_length=max_length//3, truncation=True, padding=False).input_ids# 组合 input_ids:将每个 prompt、response_a 和 response_b 的分词结果拼接起来,生成完整的输入序列。input_ids = [p + r_a + r_b for p, r_a, r_b in zip(prompt, response_a, response_b)]# 通过生成与 input_ids 等长的 1 列表,表示这些 token 都是有效的(1 表示非 padding 的 token)。attention_mask = [[1]* len(i) for i in input_ids]else:# 直接将 prompt、response_a 和 response_b 拼接成一个完整的文本序列,然后作为一个整体进行分词处理。text = [p + r_a + r_b for p, r_a, r_b in zip(prompt, response_a, response_b)]tokenized = tokenizer(text, max_length=max_length, truncation=True, padding=False)# 分词器返回的 input_ids 是分词后的 token 序列,而 attention_mask 用于标记哪些 token 是有效的(1),哪些是 padding token(0)。input_ids = tokenized.input_idsattention_mask = tokenized.attention_maskreturn input_ids, attention_mask
%%time# 加载预训练的 Gemma 分词器
tokenizer = GemmaTokenizerFast.from_pretrained(cfg.gemma_dir)
# 在每个输入文本的末尾添加 <eos>(End of Sequence)标记。这通常用于生成任务,告诉模型输入序列的结束。
tokenizer.add_eos_token = True
# 设置填充方向为右侧。即如果输入文本长度不足最大长度,将在右侧填充 <pad> 标记。
tokenizer.padding_side = "right"# 分词
# 调用之前定义的 tokenize 函数,对 test 数据集中的 prompt、response_a 和 response_b 进行分词。
# 生成的 input_ids(token 序列)和 attention_mask(注意力掩码)分别存储在 data 的相应列中。
data = pd.DataFrame()
data["id"] = test["id"]
data["input_ids"], data["attention_mask"] = tokenize(tokenizer, test["prompt"], test["response_a"], test["response_b"])
data["length"] = data["input_ids"].apply(len)# 数据增强
# 再一次调用 tokenize 函数,不同的是,这次将 response_a 和 response_b 交换,生成新的 input_ids 和 attention_mask。
# 这种方法称为 测试时增强(TTA),即通过交换模型生成的不同响应来增加预测的多样性,帮助提升模型的泛化能力。
aug_data = pd.DataFrame()
aug_data["id"] = test["id"]
aug_data['input_ids'], aug_data['attention_mask'] = tokenize(tokenizer, test["prompt"], test["response_b"], test["response_a"])
aug_data["length"] = aug_data["input_ids"].apply(len)
查看 data 数据框中第一个样本的 input_ids 所对应的文本,验证分词和拼接后的文本格式是否符合预期。
# tokenizer.decode():这是 Hugging Face tokenizer 提供的方法,用于将模型的 token IDs 转换回原始的可读文本。
print(tokenizer.decode(data["input_ids"][0]))
打印结果如下:

print(tokenizer.decode(aug_data["input_ids"][0]))
数据增强后的打印结果如下:

加载模型
将相同的模型分别加载到 GPU 0 和 GPU 1 上,以便在多 GPU 环境下加速模型的计算,并行进行推理。
# 加载基础模型到 GPU 0
device_0 = torch.device('cuda:0')
model_0 = Gemma2ForSequenceClassification.from_pretrained(cfg.gemma_dir,device_map=device_0,use_cache=False, # 禁用缓存(通常用于生成任务时启用)。对于分类任务,禁用缓存不会影响性能,并且可能节省内存。
)# 加载基础模型到 GPU 1
device_1 = torch.device('cuda:1')
model_1 = Gemma2ForSequenceClassification.from_pretrained(cfg.gemma_dir,device_map=device_1,use_cache=False,
)
加载 LoRA 适配器
model_0 = PeftModel.from_pretrained(model_0, cfg.lora_dir)
model_1 = PeftModel.from_pretrained(model_1, cfg.lora_dir)
推理
该函数的目标是对给定的数据框(df)中的样本进行推理,生成模型A获胜、模型B获胜以及平局的概率,并将这些概率结果添加到原始数据框中。
@torch.no_grad() # 在推理阶段不需要计算梯度
@torch.cuda.amp.autocast() # 这是自动混合精度(AMP)模式,用于在推理时自动使用半精度浮点数(FP16),从而减少显存占用并加快推理速度。通常用于 GPU 上的推理。
def inference(df, model, device, batch_size=cfg.batch_size, max_length=cfg.max_length):a_win, b_win, tie = [], [], [] # 分别用于存储模型A获胜、模型B获胜以及平局的概率值。for start_idx in range(0, len(df), batch_size):end_idx = min(start_idx + batch_size, len(df))tmp = df.iloc[start_idx:end_idx]input_ids = tmp["input_ids"].to_list()attention_mask = tmp["attention_mask"].to_list()# 这个函数的作用是对输入进行填充。填充方式是根据输入序列的最长序列进行填充,以确保批处理中的所有样本长度一致。inputs = pad_without_fast_tokenizer_warning(tokenizer,{"input_ids": input_ids, "attention_mask": attention_mask},padding="longest",pad_to_multiple_of=None,return_tensors="pt", # 表示将结果转换为 PyTorch 张量(tensor)。)# 将填充后的输入数据移到指定的设备(如 GPU),并通过模型进行推理,生成 logits(模型的输出)。outputs = model(**inputs.to(device))# 对 logits 进行 softmax 操作,将模型的输出转换为概率分布。# -1 表示在最后一个维度上进行 softmax,即每个样本的类别概率。# 将输出的张量移动到 CPU,便于后续操作。proba = outputs.logits.softmax(-1).cpu()# 存储推理结果a_win.extend(proba[:, 0].tolist()) # 提取第一个类别(模型A获胜)的概率并存储到 a_win 列表中。b_win.extend(proba[:, 1].tolist())tie.extend(proba[:, 2].tolist())# 更新原始的dfdf["winner_model_a"] = a_win # 将 a_win 列表中的概率值赋给df的 winner_model_a 列,表示模型A获胜的概率。df["winner_model_b"] = b_windf["winner_tie"] = tiereturn df
使用两个不同的 GPU 同时运行模型推理,并借助 Python 的 ThreadPoolExecutor 来并行化处理。通过按输入序列长度排序数据,充分利用动态填充(dynamic padding)的优化,并将数据划分为两个子集 sub_1 和 sub_2,分别在两个 GPU 上运行推理任务,最后合并结果。
st = time.time()# 将数据框 data 按照 length 列(表示输入序列的长度)降序排序。
# 这样做的目的是为了充分利用动态填充(dynamic padding),即在一个批次内,所有序列都会填充到批次中最长的序列长度。通过这种方式,减少填充冗余,提高推理的效率。
data = data.sort_values("length", ascending=False)# 将 data 分成两个子集,这种方式确保两个子集的大小大致相同,且每个子集中的序列长度分布相似。这样可以平衡两个 GPU 上的工作负载。
sub_1 = data.iloc[0::2].copy() # 从 data 中每隔一行取一行(即索引为 0, 2, 4,... 的行)。
sub_2 = data.iloc[1::2].copy() # 从 data 中每隔一行取一行,但从索引 1 开始(即索引为 1, 3, 5,... 的行)。# 通过两个线程分别处理 sub_1 和 sub_2,充分利用两个 GPU 的计算资源实现并行推理。
with ThreadPoolExecutor(max_workers=2) as executor:# 将推理任务并行地映射到不同的数据子集、模型和设备上results = executor.map(inference, (sub_1, sub_2), (model_0, model_1), (device_0, device_1))# 按行合并结果
result_df = pd.concat(list(results), axis=0)# 提取概率,这些概率可以用于后续的决策或评估,比如判断哪个模型的表现更好。
proba = result_df[["winner_model_a", "winner_model_b", "winner_tie"]].valuesprint(f"elapsed time: {time.time() - st}")
实现测试时增强(TTA),并使用两个不同的 GPU 并行运行推理。主要目的是通过交换模型A和模型B的响应来进行 TTA,并最终将原始推理结果与 TTA 结果进行平均。通过这种方式,可以提升模型在测试阶段的泛化能力,进一步提高推理结果的鲁棒性。
st = time.time()if cfg.tta: # 检查是否启用 TTA# 排序增强数据集 aug_datadata = aug_data.sort_values("length", ascending=False) # sort by input length to boost speedsub_1 = data.iloc[0::2].copy()sub_2 = data.iloc[1::2].copy()# 并行执行推理with ThreadPoolExecutor(max_workers=2) as executor:results = executor.map(inference, (sub_1, sub_2), (model_0, model_1), (device_0, device_1))# 合并 TTA 结果tta_result_df = pd.concat(list(results), axis=0)# 交换模型A和模型B的结果顺序# TTA 的顺序是颠倒的:因为在 TTA 中,response_a 和 response_b 被交换,因此 TTA 结果中模型A和模型B的概率需要重新排序tta_proba = tta_result_df[["winner_model_b", "winner_model_a", "winner_tie"]].values # 计算平均概率,通过结合原始结果和 TTA 结果,提升模型的稳定性和泛化能力。proba = (proba + tta_proba) / 2print(f"elapsed time: {time.time() - st}")
将推理结果格式化并保存为 CSV 文件,用于提交或者进一步处理。
result_df.loc[:, "winner_model_a"] = proba[:, 0] # 提取第一列,即模型A获胜的概率。
result_df.loc[:, "winner_model_b"] = proba[:, 1]
result_df.loc[:, "winner_tie"] = proba[:, 2]
submission_df = result_df[["id", 'winner_model_a', 'winner_model_b', 'winner_tie']]
submission_df.to_csv('submission.csv', index=False)
display(submission_df)
展示结果如下:
winner_model_a:模型A获胜的概率。
winner_model_b:模型B获胜的概率。
winner_tie:平局的概率。

四、背景知识补充
为什么LoRA只针对自注意力投影层进行微调?
LoRA通过在自注意力投影层(q_proj、k_proj、v_proj)中插入低秩适配器进行微调,因为这些层是Transformer模型中计算复杂度最高、且对性能影响最关键的部分。由于自注意力机制本质上决定了模型的上下文理解能力,针对自注意力层进行微调可以在不大幅度修改模型其他部分的情况下,快速优化模型的性能。仅微调这些投影层能够在减少计算资源和显存消耗的同时,快速适应不同任务,保持模型的有效性和泛化能力。这也是为什么LoRA选择只针对这些特定模块进行微调,而不是对整个模型进行全量微调的原因。
QLoRA(Quantized Low-Rank Adaptation)
QLoRA(Quantized Low-Rank Adaptation)是结合了量化(Quantization)和 LoRA(Low-Rank Adaptation)技术的微调方法,旨在在资源有限的情况下对大规模预训练模型进行高效微调。它通过将模型参数进行量化,同时利用低秩矩阵进行适应性学习,以减少计算开销和显存需求,从而实现对大模型的高效微调。
QLoRA 的核心思想:
-
量化(Quantization):量化是一种压缩技术,将模型参数从高精度的浮点数(如32位浮点数)压缩到低精度(如4位或8位整数)。通过量化,模型的存储需求和计算成本大大降低。
-
低秩适应(LoRA):LoRA 是一种低秩矩阵分解技术,在不改变原始预训练模型的基础上,通过插入低秩矩阵来进行任务特定的微调。这使得在模型参数更新时只需要学习和存储这些低秩矩阵,从而节省资源。
-
结合量化和低秩适应:QLoRA 首先对模型的全精度参数进行量化,以减少显存占用和计算成本,然后在量化后的模型上应用 LoRA,进一步进行任务特定的微调。这种方法可以在资源有限的情况下,利用大规模预训练模型的能力进行高效微调,而不影响模型的性能。
QLoRA 的优势:
- 资源高效:通过量化模型参数,大幅减少显存占用和计算资源需求,使得即使在低端设备上也可以进行大模型的微调。
- 灵活性高:LoRA 仅在任务相关的部分进行低秩微调,保留了模型的预训练权重,允许在多个任务上灵活应用。
- 可扩展性:QLoRA 可以在多个任务和领域中广泛应用,特别适合在推理任务、文本生成等领域进行微调。
QLoRA 的典型工作流程:
-
加载预训练模型:加载一个大规模预训练模型(如 GPT、BERT 等),并对其参数进行量化处理。
-
插入 LoRA 层:在模型的注意力层或其他关键层插入 LoRA 层,用于低秩矩阵的微调。
-
训练微调:在量化后的模型上,只训练插入的低秩矩阵部分,而冻结原始量化后的参数。这大大减少了需要更新的参数数量,提升了训练效率。
-
推理与部署:通过微调后的低秩矩阵和量化的参数进行推理,既节省计算资源又能提供接近全精度模型的性能。
QLoRA 的应用场景:
- 资源受限的设备:QLoRA 尤其适合在低端硬件(如 CPU 或较小的 GPU)上进行大模型的微调,适用于移动设备或嵌入式设备。
- 多任务学习:通过低秩矩阵的适应性,QLoRA 可以实现多个任务的高效微调和快速切换,适合需要处理多任务的场景。
总结来说,QLoRA 将量化和 LoRA 技术相结合,使得在计算和资源有限的情况下能够高效微调大模型,特别适合在低资源环境中进行深度学习模型的适应性微调。
混合精度训练(Mixed Precision Training)
混合精度训练(Mixed Precision Training)是一种通过使用半精度浮点数(16-bit,FP16)和单精度浮点数(32-bit,FP32)组合进行训练的方法。这种方法可以在不明显牺牲模型精度的前提下,大幅度减少模型的显存占用,并提高计算速度。
混合精度训练的基本概念:
-
FP32(单精度浮点数):
- 传统深度学习训练使用32位浮点数来表示模型的权重和梯度。虽然FP32能够提供较高的数值精度,但其内存需求较高,尤其是对于大规模模型,会占用大量显存。
-
FP16(半精度浮点数):
- 混合精度训练引入了16位浮点数。FP16的数据占用更小,但精度也较低。GPU可以在执行计算时加速FP16操作,因为它需要的内存带宽更低,且计算吞吐量更高。
-
混合使用FP16和FP32:
- 混合精度训练并非简单地将所有计算切换为FP16,而是对部分计算使用FP16,另一部分仍使用FP32。
- 例如,模型的权重和激活可能以FP16存储和更新,而损失函数和梯度累积等更为关键的数值部分仍使用FP32来保持数值的稳定性。
混合精度训练的优势:
-
显存节省:
- FP16占用的显存只有FP32的一半,因此使用混合精度可以减少显存的需求,使得更大规模的模型可以在同样的显存条件下运行。
-
计算加速:
- 许多现代GPU(如NVIDIA的Volta、Turing和Ampere架构)专门为FP16计算做了优化,使用Tensor Cores来加速FP16运算。相比FP32,FP16的计算速度通常更快,从而加速训练。
-
适合大规模模型:
- 在深度学习模型越来越大的趋势下,混合精度训练是有效处理大模型的关键技术之一,允许在有限的硬件资源上训练比以前更大、更复杂的模型。
如何实现混合精度训练:
在使用Hugging Face的transformers库中,可以很简单地通过以下方式启用混合精度训练:
training_args = TrainingArguments(output_dir="output",num_train_epochs=3,per_device_train_batch_size=16,learning_rate=5e-5,fp16=True, # 启用混合精度训练
)
设置fp16=True就会开启混合精度训练。Hugging Face的Trainer类和PyTorch的自动混合精度功能会自动处理FP16与FP32之间的切换,确保模型在训练过程中的数值稳定性。
工作机制:
-
自动混合精度(Automatic Mixed Precision,AMP):
- AMP会根据需要自动选择FP16或FP32,通常由PyTorch和TensorFlow框架管理。大多数非关键性操作使用FP16来加速训练和减少显存占用,而关键性操作(如梯度计算)仍保持FP32的精度,以避免数值不稳定。
-
动态损失缩放(Dynamic Loss Scaling):
- 在混合精度训练中,由于FP16的表示范围较小,可能导致梯度溢出的问题。为了避免这个问题,通常会使用动态损失缩放(Dynamic Loss Scaling)。它通过动态调整损失函数的比例,防止梯度溢出,同时保持训练的数值稳定性。
适用场景:
- 大规模语言模型:如BERT、GPT、T5等大型预训练模型,在训练和微调过程中需要大量的内存和计算资源,混合精度训练可以有效地减少资源需求。
- 图像分类模型:如ResNet、EfficientNet等,在计算量很大的图像分类任务中,使用混合精度也可以显著提升训练效率。
总结:
混合精度训练是一种通过同时使用FP16和FP32来加速深度学习模型训练的方法。它可以节省显存、加速计算,并且通过AMP和动态损失缩放保持训练的数值稳定性。通过在现代GPU上启用混合精度,用户可以在同样的硬件资源下运行更大规模的模型或者在更短的时间内完成模型训练。
梯度溢出(Gradient Overflow)
梯度溢出(Gradient Overflow)是指在深度学习训练过程中,梯度的数值变得过大,以至于超出了数值表示的范围,导致计算结果为无穷大或无法表示的数值(例如NaN)。这种现象在使用半精度浮点数(FP16)进行训练时尤为常见,因为FP16的数值表示范围比FP32小得多。
为什么会发生梯度溢出?
-
FP16的数值范围较小:
- 在混合精度训练中,当使用FP16进行计算时,FP16的有效表示范围比FP32更小。FP16的最大表示值是 6.55 × 1 0 4 6.55 \times 10^4 6.55×104,而FP32的最大值是 3.4 × 1 0 38 3.4 \times 10^{38} 3.4×1038。如果梯度的数值超出了FP16的表示范围,它将无法存储正确的梯度,导致梯度溢出为无穷大(
inf)或NaN。
- 在混合精度训练中,当使用FP16进行计算时,FP16的有效表示范围比FP32更小。FP16的最大表示值是 6.55 × 1 0 4 6.55 \times 10^4 6.55×104,而FP32的最大值是 3.4 × 1 0 38 3.4 \times 10^{38} 3.4×1038。如果梯度的数值超出了FP16的表示范围,它将无法存储正确的梯度,导致梯度溢出为无穷大(
-
大模型和复杂网络的梯度:
- 在大规模深度学习模型中(如Transformer、ResNet等),网络的层数非常多,反向传播过程中,某些层的梯度可能会变得非常大。由于累积的梯度过大,尤其是在网络的深层,FP16无法正确表示这些大梯度,从而出现梯度溢出。
-
大步长或不稳定的优化:
- 过高的学习率可能会导致模型在每次更新时改变过大,特别是在早期训练阶段,可能会导致梯度变得非常大,进而导致梯度溢出。
梯度溢出的影响
- 训练不稳定:梯度溢出会导致计算结果为
inf或NaN,进而使模型的参数更新异常,导致模型训练的失败。 - 无法收敛:如果模型参数在更新时收到错误的梯度影响,可能会导致模型无法正确地学习,进而无法收敛。
解决梯度溢出的常见方法
-
动态损失缩放(Dynamic Loss Scaling):
- 这是在混合精度训练中最常用的解决梯度溢出的技术。通过动态调整损失函数的缩放比例,减少梯度值过大带来的溢出风险。
- 当训练开始时,损失值会被乘以一个较大的缩放因子,以避免梯度值过小。然而,如果在反向传播过程中出现了梯度溢出,损失缩放因子会自动减小,直到找到一个合适的缩放值。
- PyTorch和TensorFlow框架中的AMP(Automatic Mixed Precision)都会自动应用动态损失缩放。
在PyTorch中,可以通过
torch.cuda.amp轻松启用动态损失缩放:from torch.cuda.amp import GradScalerscaler = GradScaler() # 创建动态缩放器for data, target in dataloader:optimizer.zero_grad()with torch.cuda.amp.autocast(): # 启用混合精度output = model(data)loss = loss_fn(output, target)scaler.scale(loss).backward() # 动态缩放损失并反向传播scaler.step(optimizer) # 更新模型参数scaler.update() # 动态调整缩放因子 -
降低学习率(Learning Rate):
- 通过降低学习率,可以避免梯度在反向传播过程中变得过大。较小的学习率可以使得每次更新的步幅较小,减少梯度的波动。
-
梯度裁剪(Gradient Clipping):
- 这是另一种防止梯度溢出的常用技术。在反向传播中,如果某一层的梯度值过大,梯度裁剪会将其限制在某个最大阈值内,以避免梯度更新过大,防止梯度溢出。
- 在Hugging Face的
Trainer中,可以通过max_grad_norm参数设置梯度裁剪:training_args = TrainingArguments(output_dir="output",num_train_epochs=3,per_device_train_batch_size=16,learning_rate=5e-5,max_grad_norm=1.0, # 设置梯度裁剪的最大值为1.0 )
-
使用FP32进行关键性计算:
- 对于一些数值敏感的操作,特别是梯度计算,可以使用FP32而非FP16,以确保梯度的数值稳定性。这通常由混合精度训练框架(如AMP)自动管理。
总结:
梯度溢出是深度学习中常见的问题,尤其在混合精度训练中,由于FP16的数值范围较小,更容易发生溢出。通过动态损失缩放、梯度裁剪、降低学习率等技术,可以有效避免梯度溢出,确保训练的数值稳定性。
TTA(Test Time Augmentation)
TTA(Test Time Augmentation) 是指在模型推理时使用的数据增强技术,通常用于提高模型的泛化能力和预测性能。与训练时的数据增强不同,TTA 在模型推理阶段应用,通过对输入数据进行不同的变换或增强操作,模型可以产生多个预测结果,然后结合这些结果来得出最终的预测。
工作原理:
-
输入增强:在推理时,使用不同的增强方法对输入数据进行变换。例如,对于图像分类任务,可以对同一张图片进行旋转、翻转、缩放等操作;对于 NLP 任务,可以对输入文本进行不同的处理(如改变词序、交换部分句子等)。
-
模型预测:将增强后的数据分别输入到模型中,每个增强后的数据都会生成一个预测结果。
-
结果整合:通常通过取这些预测结果的平均值(或投票机制)来得到最终的预测结果。例如,对于分类任务,可以使用多个增强后结果的平均概率作为最终的分类结果。
TTA 在不同任务中的应用:
-
图像分类:
- 对输入图像进行旋转、缩放、平移、翻转等操作,生成多个增强后的图像,模型对这些图像分别做出预测。
- 最终的分类结果可能是各个预测结果的概率平均或投票机制。
- 示例:一张图片经过 10 次不同的增强,模型将对这 10 张图片分别做出预测,最终通过这些结果决定图像属于哪个类别。
-
目标检测:
- 通过对输入图像进行裁剪、旋转等操作,对目标物体的位置进行预测。然后将多个增强后的检测结果综合,以提高目标检测的准确性。
-
NLP(自然语言处理):
- 对文本输入进行不同的改写或增强(如同义词替换、不同的响应顺序等),通过模型对不同的增强形式进行预测,并结合多个预测结果来做最终判断。
-
时间序列预测:
- 对时间序列进行切片或平移等增强操作,模型在不同时间段进行预测,最终整合多个增强后的预测结果。
TTA 的优点:
- 提高泛化能力:通过对输入数据进行增强,可以让模型对多样化的数据进行推理,从而减少模型对特定输入的过拟合。
- 提升预测准确性:通过将多个增强后的结果综合,往往能够比单一预测结果更加准确和稳定。
- 应用灵活:TTA 可以在任何无需重新训练的情况下直接应用于推理阶段,不需要对模型本身进行修改。
TTA 的缺点:
- 计算资源增加:由于需要对同一个输入进行多次变换和预测,TTA 会显著增加推理阶段的计算成本和时间。
- 效果有限:虽然 TTA 能提升模型的预测性能,但其增益通常不如训练阶段的数据增强那么显著,而且对某些任务的提升可能非常有限。
总结:
TTA(Test Time Augmentation) 是一种在推理阶段应用的数据增强技术,目的是通过对输入数据进行不同变换和增强操作来提高模型的预测性能。它广泛应用于图像分类、目标检测、时间序列分析和 NLP 等任务,能够提高模型的泛化能力,但同时也会增加推理的计算开销。