目标
读完本文后,您应该能够解释:
- 什么是上下文
- 哪些数据同时存储在应用程序和请求上下文中
- 在 Flask 中处理请求时,处理应用程序和请求上下文所需的步骤
- 如何使用应用程序和请求上下文的代理
- 如何在视图函数中使用
current_app和代理request - 什么是上下文本地
什么是上下文?
为了执行你编写的代码,需要处理数据。这些数据可能是配置数据、输入数据、数据库数据等等。
上下文用于跟踪代码需要执行的数据。
在 Flask 中,上下文用于提供处理请求和命令行界面 (CLI) 命令所需的数据。
虽然本文重点介绍处理请求,但所提出的概念也适用于 CLI 命令。
请求处理
让我们从高层的角度开始了解请求的处理方式:
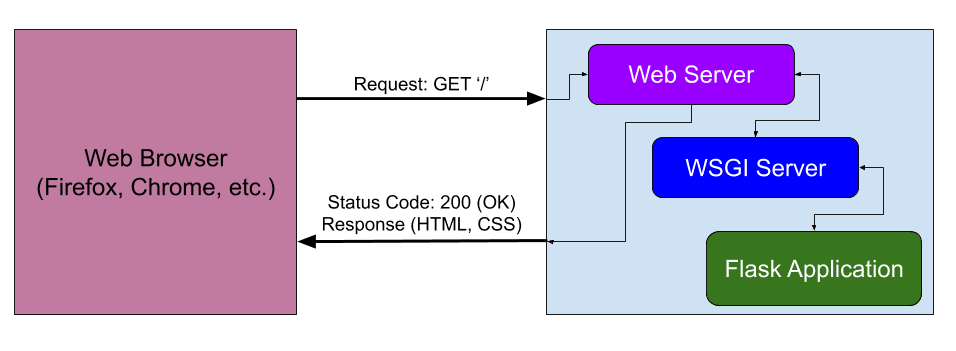
因此,浏览器会向 Web 服务器(如 Nginx 或 Apache)发送请求,以请求特定的 URL(上图中的“/”URL)。然后,Web 服务器会将此请求路由到 WSGI 服务器进行处理。
WSGI 代表 Web 服务器网关接口,是 Web 服务器和基于 Python 的 Web 应用程序之间的接口。它是必需的,因为 Web 服务器无法直接与 Python 应用程序通信。有关详细信息,请查看WSGI。
WSGI 服务器告诉 Flask 应用程序处理请求。
Flask 应用程序生成一个响应,该响应被发送回 WSGI 服务器,再发送回 Web 服务器,最终发送回 Web 浏览器。
这些步骤描述了请求-响应周期,这是通过 Web 服务器、WSGI 应用服务器和 Web 应用程序处理请求的关键功能。
Flask 中的上下文
当收到请求时,Flask 提供两个上下文:
语境 描述 可用对象 应用 跟踪应用程序级数据(配置变量、记录器、数据库连接) current_app,g要求 跟踪请求级数据(URL、HTTP 方法、标头、请求数据、会话信息) request,session值得注意的是,上述每个对象通常被称为“代理”。这只是意味着它们是对象全局风格的代理。我们稍后会深入探讨这一点。
Flask 在收到请求时处理这些上下文的创建。它们可能会造成混淆,因为您并不总是能够根据应用程序所处的状态访问特定对象。
概览图
下图说明了处理请求时如何处理上下文:

第 1 步 - Web 和 WSGI 服务器
当 Web 服务器收到请求时,一切就开始了:

Web 服务器的工作是将传入的 HTTP 请求路由到WSGI服务器。
Apache和Nginx是两种常见的 Web 服务器,而Gunicorn、uWSGI和mod_wsgi是流行的 WSGI 服务器。
值得注意的是,虽然Flask 开发服务器是一个 WSGI 服务器,但它并不适合用于生产。
步骤 2 - 工作者
为了处理该请求,WSGI 服务器会生成一个工作进程来处理该请求:

工作线程可以是线程、进程或协程。例如,如果您使用 Flask Development Server 的默认配置,则工作线程将是线程。
如果您有兴趣了解有关 Python 中线程、多处理和异步之间的更多区别,请查看使用并发、并行和异步加速 Python文章和Python 中的并发视频。
对于这个解释,工作者类型并不重要;关于工作者的关键点是它一次处理一个请求(因此需要多个工作者)。
步骤 3 - 上下文
一旦执行切换到 Flask 应用程序,Flask 就会创建应用程序和请求上下文并将它们推送到各自的堆栈上:

回顾一下,应用程序上下文存储应用程序级数据,例如配置变量、数据库连接和记录器。同时,请求上下文存储需要处理以生成响应的特定于请求的数据。
可能会令人惊讶地看到,但两个堆栈都是作为全局对象实现的(这将在下一节中变得更加清晰)。
步骤 4 - 代理
现在 Flask 应用程序已准备好处理数据(在视图函数中),并且数据已在应用程序和请求上下文堆栈中准备就绪,我们需要一种方法来连接这两部分......代理来救援!

视图函数使用代理来访问应用程序(存储在应用程序上下文堆栈中)和请求上下文(存储在请求上下文堆栈中):
current_app- 代理工作者的应用程序上下文request- 代理工作者的请求上下文
乍一看,这个序列似乎令人困惑,因为视图函数似乎正在通过代理访问全局对象(应用程序和请求上下文堆栈)。如果是这样的话,这个操作就会有问题,因为它不是线程安全的。您可能还会认为这些堆栈(作为全局对象)可以被任何工作程序访问,这将是一个安全问题。
然而,这种设计是 Flask 的一大特色……堆栈被实现为上下文本地对象。
有关代理的更多信息,请查看Flask 文档中的代理注释和代理模式文章。
上下文局部变量
Python 有一个线程本地数据的概念,用于存储特定于线程的数据,它既是“线程安全的,又是线程唯一的”。换句话说,每个线程都能够以线程安全的方式访问数据,并且数据对于特定线程始终是唯一的。
Flask 实现了类似的行为(上下文本地),但是以更通用的方式允许工作者成为线程、进程或协程。
上下文局部变量实际上是在Werkzeug中实现的,它是 Flask 的关键包之一。为简单起见,我们在讨论上下文局部变量时将引用 Flask。
当数据存储在上下文本地对象中时,数据以只有一个工作进程可以检索的方式存储。因此,如果两个单独的工作进程访问上下文本地对象,它们将各自获取各自独有的特定数据。
下一节将介绍一个使用上下文本地对象的示例。
总而言之,每个视图函数中都有current_app和request代理,它们用于从各自的堆栈访问上下文,这些堆栈存储为上下文本地对象。
在应用程序和请求上下文堆栈中使用“堆栈”使这个概念比原来更加令人困惑。这些“堆栈”通常存储的上下文不超过一个。
使用的数据结构是堆栈,因为存在非常高级的场景(例如,内部重定向)需要多于一个的元素。
Flask 中代理的好处
如果你要从头开始创建自己的 Web 框架,那么你可能会考虑将应用程序和请求上下文传递到每个视图函数中,如下所示:
@app.route('/add_item', methods=['GET', 'POST'])
def add_item(application_context, request_context): # contexts passed in!if request_context.method == 'POST':# Save the form data to the database...application_context.logger.info(f"Added new item ({ request_context.form['item_name'] })!")...事实上,许多 Web 框架都是这样工作的(包括Django)。
然而,Flask 提供了current_app和request代理,它们最终看起来像视图函数的全局变量:
from flask import current_app, request@app.route('/add_item', methods=['GET', 'POST'])
def add_item():if request.method == 'POST':# Save the form data to the database...current_app.logger.info(f"Added new item ({ request.form['item_name'] })!")...
通过使用这种方法,视图函数不需要将上下文作为参数传入;这种方法简化了视图函数定义。但它可能会引起混淆,因为您并不总是能够访问current_app和request代理,具体取决于您的应用程序所处的状态。
提醒:
current_app和request代理实际上不是全局变量;它们指向作为上下文本地实现的全局对象,因此代理对于每个工作者来说始终是唯一的。
第 5 步 - 清理
生成响应后,请求和应用程序上下文将从各自的堆栈中弹出:

此步骤清理堆栈。
然后将响应发送回 Web 浏览器,完成对该请求的处理。
上下文局部变量
上下文本地对象是使用本地对象实现的,可以像这样创建:
$ python>>> from werkzeug.local import Local
>>> data = Local()
>>> data.user = 'pkennedy@hey.com'
每个上下文(即上一节中讨论的“工作者”)都可以访问一个Local对象,用于上下文独有的数据存储。所访问的数据对于上下文来说是唯一的,并且只能由该上下文访问。
LocalStack对象与Local对象类似,但是保留一个对象堆栈以允许push()和pop()操作。
LocalStack在上一节中,我们了解了在 Flask 中处理请求时如何使用应用程序上下文堆栈和请求上下文堆栈。这些堆栈在 Flask 中作为全局内存中的对象实现。
为了帮助巩固上下文局部变量的工作原理,让我们通过一个例子来说明如何LocalStack在全局内存中创建一个对象,然后让三个独立的线程访问它:

以下是该示例的完整脚本:
"""
Example script to illustrate how a global `LocalStack` object can be used
when working with multiple threads.
"""
import random
import threading
import timefrom werkzeug.local import LocalStack# Create a global LocalStack object for storing data about each thread
thread_data_stack = LocalStack()def long_running_function(thread_index: int):"""Simulates a long-running function by using time.sleep()."""thread_data_stack.push({'index': thread_index, 'thread_id': threading.get_native_id()})print(f'Starting thread #{thread_index}... {thread_data_stack}')time.sleep(random.randrange(1, 11))print(f'LocalStack contains: {thread_data_stack.top}')print(f'Finished thread #{thread_index}!')thread_data_stack.pop()if __name__ == "__main__":threads = []# Create and start 3 threads that each run long_running_function()for index in range(3):thread = threading.Thread(target=long_running_function, args=(index,))threads.append(thread)thread.start()# Wait until each thread terminates before the script exits by# 'join'ing each threadfor thread in threads:thread.join()print('Done!')
该文件创建一个LocalStack对象(thread_data_stack)用于存储将要创建的每个线程的数据。
thread_data_stack模仿 Flask 中的应用程序上下文堆栈或请求上下文堆栈。
long_running_function在每个线程中运行:
def long_running_function(thread_index: int):"""Simulates a long-running function by using time.sleep()."""thread_data_stack.push({'index': thread_index, 'thread_id': threading.get_native_id()})print(f'Starting thread #{thread_index}... {thread_data_stack}')time.sleep(random.randrange(1, 11))print(f'LocalStack contains: {thread_data_stack.top}')print(f'Finished thread #{thread_index}!')thread_data_stack.pop()
该函数将有关线程的数据推送到thread_data_stack全局内存中的对象:
thread_data_stack.push({'index': thread_index, 'thread_id': threading.get_native_id()})
此操作模仿将应用程序或请求上下文推送到其各自的堆栈。
函数完成后time.sleep(),将访问以下数据thread_data_stack:
print(f'LocalStack contains: {thread_data_stack.top}')
此操作模仿使用
app_context和request代理,因为这些代理访问其各自堆栈顶部的数据。
在函数的末尾,数据从中弹出thread_data_stack:
thread_data_stack.pop()
此操作模拟从各自的堆栈中弹出应用程序或请求上下文。
脚本运行时会启动3个线程:
# Create and start 3 threads that each run long_running_function()
for index in range(3):thread = threading.Thread(target=long_running_function, args=(index,))threads.append(thread)thread.start()
并且join每个线程都等待,直到每个线程完成执行:
# Wait until each thread terminates before the script exits by
# 'join'ing each thread
for thread in threads:thread.join()
让我们运行这个脚本看看会发生什么:
$ python app.pyStarting thread #0... <werkzeug.local.LocalStack object at 0x109cebc40>
Starting thread #1... <werkzeug.local.LocalStack object at 0x109cebc40>
Starting thread #2... <werkzeug.local.LocalStack object at 0x109cebc40>
LocalStack contains: {'index': 0, 'thread_id': 320270}
Finished thread #0!
LocalStack contains: {'index': 1, 'thread_id': 320271}
Finished thread #1!
LocalStack contains: {'index': 2, 'thread_id': 320272}
Finished thread #2!
Done!
每个线程真正有趣的是它们都指向LocalStack内存中的同一个对象:
Starting thread #0... <werkzeug.local.LocalStack object at 0x109cebc40>
Starting thread #1... <werkzeug.local.LocalStack object at 0x109cebc40>
Starting thread #2... <werkzeug.local.LocalStack object at 0x109cebc40>
当每个线程访问 时thread_data_stack,访问都是该线程独有的LocalStack!这就是(和)的魔力Local——它们允许上下文独有的访问:
LocalStack contains: {'index': 0, 'thread_id': 320270}
LocalStack contains: {'index': 1, 'thread_id': 320271}
LocalStack contains: {'index': 2, 'thread_id': 320272}
与典型的全局内存访问不同,对的访问
thread_data_stack也是线程安全的。
结论
Flask 的一个强大(但令人困惑)的方面是如何处理应用程序和请求上下文。希望本文能对这个主题提供一些澄清!
应用程序和请求上下文在处理请求或 CLI 命令时提供必要的数据。确保使用current_app和request代理来访问应用程序上下文和请求上下文。